
Sicherheitsempfehlungen
Für Arbeitslasten, die eine starke Sicherheitsgrenze oder Isolation erfordern, sollten Sie Folgendes berücksichtigen:
Um eine strenge Isolation zu erzwingen, platzieren Sie sicherheitssensible Arbeitslasten in einem anderen Google Cloud Projekt.
Wenn Sie den Zugriff auf bestimmte Ressourcen steuern möchten, aktivieren Sie die rollenbasierte Zugriffssteuerung in Ihren Cloud Data Fusion-Instanzen.
Um sicherzustellen, dass die Instanz nicht öffentlich zugänglich ist, und um das Risiko einer Exfiltration vertraulicher Daten zu verringern, aktivieren Sie interne IP-Adressen und VPC Service Controls (VPC-SC) in Ihren Instanzen.
Authentifizierung
Die Web-Benutzeroberfläche von Cloud Data Fusion unterstützt Authentifizierungsmechanismen, die von der Console unterstützt werden. Der Zugriff wird über die Identitäts- und Zugriffsverwaltung gesteuert. Google Cloud
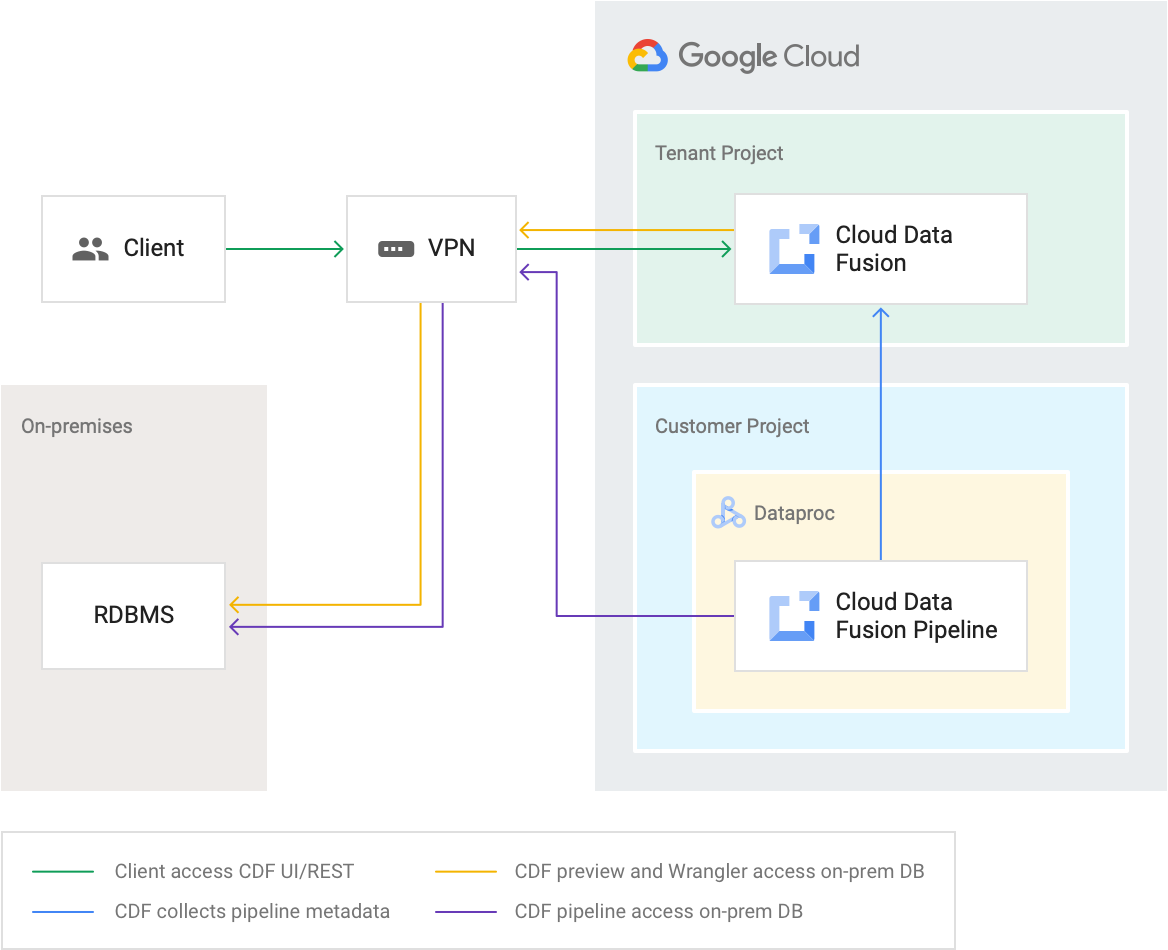
Netzwerksteuerungen
Sie können eine private Cloud Data Fusion-Instanz erstellen, die über VPC-Peering oder Private Service Connect mit Ihrem VPC-Netzwerk verbunden werden kann. Private Cloud Data Fusion-Instanzen haben eine interne IP-Adresse und sind nicht über das öffentliche Internet zugänglich. Mit VPC Service Controls können Sie die Sicherheit zusätzlich zu einer privaten Cloud Data Fusion-Instanz festlegen.
Weitere Informationen finden Sie in der Übersicht über Cloud Data Fusion-Netzwerke.
Pipelineausführung auf vorab erstellten internen IP-Clustern von Managed Service for Apache Spark
Sie können eine private Cloud Data Fusion-Instanz mit dem Remote Hadoop-Bereitsteller verwenden. Der Managed Service for Apache Spark-Cluster muss sich im VPC-Netzwerk Peering mit Cloud Data Fusion befinden. Die Remote-Hadoop-Bereitstellung wird mit der internen IP-Adresse des Masterknotens des Managed Service for Apache Spark-Clusters konfiguriert.
Zugriffssteuerung
Zugriff auf die Cloud Data Fusion-Instanz verwalten: Instanzen mit aktivierter RBAC unterstützen die Zugriffsverwaltung auf Namespace-Ebene über Identity and Access Management. Instanzen mit deaktivierter RBAC unterstützen nur die Zugriffsverwaltung auf Instanzebene. Wenn Sie Zugriff auf eine Instanz haben, können Sie auf alle Pipelines und Metadaten in dieser Instanz zugreifen.
Pipelinezugriff auf Ihre Daten: Zugriff auf die Pipeline wird durch Zugriff auf das Dienstkonto gewährt. Dabei kann es sich um ein von Ihnen angegebenes benutzerdefiniertes Dienstkonto handeln.
Firewallregeln
Bei einer Pipelineausführung steuern Sie den ein- und ausgehenden Traffic, indem Sie die entsprechenden Firewallregeln für die Kunden-VPC festlegen, auf der die Pipeline ausgeführt wird.
Weitere Informationen finden Sie unter Firewallregeln.
Schlüsselspeicherung
Passwörter, Schlüssel und andere Daten werden sicher in Cloud Data Fusion gespeichert und mit Schlüsseln verschlüsselt, die in Cloud Key Management Service gespeichert sind. Zur Laufzeit ruft Cloud Data Fusion den Cloud Key Management Service auf, um den Schlüssel abzurufen, der zum Entschlüsseln gespeicherter Geheimnisse verwendet wird.
Verschlüsselung
Standardmäßig werden inaktive Daten mit Google-owned and Google-managed encryption keys, und bei der Übertragung über TLS v1.2 verschlüsselt. Sie verwenden kundenverwaltete Verschlüsselungsschlüssel (Customer-Managed Encryption Keys, CMEK) , um die Daten zu steuern, die von Cloud Data Fusion-Pipelines geschrieben werden, einschließlich Metadaten des Managed Service for Apache Spark-Clusters sowie Cloud Storage-, BigQuery- und Pub/Sub-Datenquellen und -Senken.
Dienstkonten
Cloud Data Fusion-Pipelines werden in Managed Service for Apache Spark-Clustern im Kundenprojekt ausgeführt und können zur Ausführung mit einem vom Kunden angegebenen (benutzerdefinierten) Dienstkonto konfiguriert werden. Einem benutzerdefinierten Dienstkonto muss die Rolle Dienstkontonutzer zugewiesen sein.
Projekte
Cloud Data Fusion-Dienste werden in von Google verwalteten Mandantenprojekten erstellt, auf die Nutzer nicht zugreifen können. Cloud Data Fusion-Pipelines werden auf Managed Service for Apache Spark-Clustern innerhalb von Kundenprojekten ausgeführt. Kunden können während ihres Lebenszyklus auf diese Cluster zugreifen.
Audit-Logs
Cloud Data Fusion-Audit-Logs sind über Logging verfügbar.
Plug-ins und Artefakte
Operatoren und Administratoren sollten bei der Installation nicht vertrauenswürdiger Plug-ins oder Artefakte vorsichtig sein, da sie ein Sicherheitsrisiko darstellen können.
Workforce Identity-Föderation
Nutzer der Workforce Identity-Föderation können Vorgänge in Cloud Data Fusion ausführen, z. B. Instanzen erstellen, löschen, aktualisieren und auflisten. Weitere Informationen zu Einschränkungen finden Sie unter Workforce Identity-Föderation: Unterstützte Produkte und Einschränkungen.