
שלב 1: הגדרת עומסי עבודה
בדף הזה מוסבר איך לבצע את השלב הראשוני בהגדרת תשתית הנתונים, שהיא הליבה של Cortex Framework. השכבה הזו מבוססת על אחסון ב-BigQuery, והיא מארגנת את הנתונים הנכנסים ממקורות שונים. הנתונים המאורגנים האלה מפשטים את הניתוח ואת היישום שלהם בפיתוח AI.
הגדרה של שילוב נתונים
כדי להתחיל, צריך להגדיר כמה פרמטרים מרכזיים שישמשו כתוכנית פעולה לארגון הנתונים ולשימוש יעיל בהם במסגרת Cortex. חשוב לזכור שהפרמטרים האלה יכולים להשתנות בהתאם לעומס העבודה הספציפי, לזרימת הנתונים שבחרתם ולמנגנון השילוב. הדיאגרמה הבאה מספקת סקירה כללית של שילוב נתונים ב-Cortex Framework Data Foundation:

כדי להשתמש בנתונים בצורה יעילה ואפקטיבית ב-Cortex Framework, צריך להגדיר את הפרמטרים הבאים לפני הפריסה.
פרויקטים
- פרויקט המקור: הפרויקט שבו נמצאים הנתונים הגולמיים. צריך לפחות פרויקט אחד ב- Google Cloud כדי לאחסן נתונים ולהריץ את תהליך הפריסה.
- פרויקט יעד (אופציונלי): הפרויקט שבו מאוחסנים מודלים של נתונים מעובדים של Cortex Framework Data Foundation. הוא יכול להיות זהה לפרויקט המקור, או שונה ממנו בהתאם לצרכים שלכם.
אם רוצים להגדיר קבוצות נפרדות של פרויקטים ושל מערכי נתונים לכל עומס עבודה (לדוגמה, קבוצה אחת של פרויקטים של מקור ויעד ל-SAP וקבוצה אחרת של פרויקטים של יעד ומקור ל-Salesforce), צריך להפעיל פריסות נפרדות לכל עומס עבודה. מידע נוסף זמין בקטע שימוש בפרויקטים שונים כדי להפריד את הגישה בקטע של השלבים האופציונליים.
מודל נתונים
- פריסת מודלים: בוחרים אם רוצים לפרוס מודלים לכל עומסי העבודה או רק קבוצה אחת של מודלים (לדוגמה, SAP, Salesforce ו-Meta). למידע נוסף, אפשר לעיין במאמר בנושא מקורות נתונים ועומסי עבודה זמינים.
מערכי נתונים ב-BigQuery
- מערך נתונים של המקור (נתונים גולמיים): מערך נתונים ב-BigQuery שבו מתבצעת שכפול של נתוני המקור או שבו נוצרים נתוני הבדיקה. מומלץ ליצור מערכי נתונים נפרדים, אחד לכל מקור נתונים. לדוגמה, מערך נתונים גולמי אחד ל-SAP ומערך נתונים גולמי אחד ל-Google Ads. מערך הנתונים הזה שייך לפרויקט המקור.
- מערך נתונים של CDC: מערך נתונים ב-BigQuery שבו נמצאים הנתונים שעברו עיבוד על ידי CDC, והרשומות הזמינות האחרונות. בחלק מעומסי העבודה אפשר למפות שמות של שדות. מומלץ ליצור מערך נתונים נפרד של CDC לכל מקור. לדוגמה, קבוצת נתונים אחת של CDC ל-SAP וקבוצת נתונים אחת של CDC ל-Salesforce. מערך הנתונים הזה שייך לפרויקט המקור.
- מערך נתונים לדיווח על יעדים: מערך נתונים ב-BigQuery שבו נפרסים מודלים מוגדרים מראש של Data Foundation. מומלץ ליצור מערך נתונים נפרד לדיווח עבור כל מקור. לדוגמה, מערך נתונים אחד לדיווח עבור SAP ומערך נתונים אחד לדיווח עבור Salesforce. אם מערך הנתונים הזה לא קיים, הוא נוצר באופן אוטומטי במהלך הפריסה. מערך הנתונים הזה שייך לפרויקט היעד.
- עיבוד מראש של מערך הנתונים K9: מערך נתונים ב-BigQuery שאפשר לפרוס בו רכיבי DAG לשימוש חוזר, שמתאימים לעומסי עבודה שונים, כמו
timeמאפיינים. לעומסי עבודה יש תלות במערך הנתונים הזה, אלא אם הוא שונה. אם מערך הנתונים הזה לא קיים, הוא נוצר אוטומטית במהלך הפריסה. מערך הנתונים הזה שייך לפרויקט המקור. - עיבוד אחרי ההעברה של מערך הנתונים K9: מערך נתונים ב-BigQuery שאפשר לפרוס בו דיווח על עומסי עבודה שונים ו-DAGs נוספים ממקורות חיצוניים (לדוגמה, הטמעה של Google Trends). אם מערך הנתונים הזה לא קיים, הוא נוצר אוטומטית במהלך הפריסה. מערך הנתונים הזה שייך לפרויקט היעד.
אופציונלי: יצירת נתונים לדוגמה
אם אין לכם גישה לנתונים שלכם, או אם אין לכם כלים לשכפול כדי להגדיר נתונים, או אפילו אם אתם רק רוצים לראות איך Cortex Framework פועל, אתם יכולים להשתמש ב-Cortex Framework כדי ליצור נתונים וטבלאות לדוגמה. עם זאת, עדיין צריך ליצור ולזהות את מערכי הנתונים של CDC ושל נתונים גולמיים מראש.
יוצרים מערכי נתונים ב-BigQuery לנתונים גולמיים ול-CDC לכל מקור נתונים, לפי ההוראות הבאות.
המסוף
פותחים את הדף BigQuery במסוף Google Cloud .
בחלונית Explorer, בוחרים את הפרויקט שבו רוצים ליצור את מערך הנתונים.
מרחיבים את האפשרות פעולות ולוחצים על יצירת מערך נתונים:
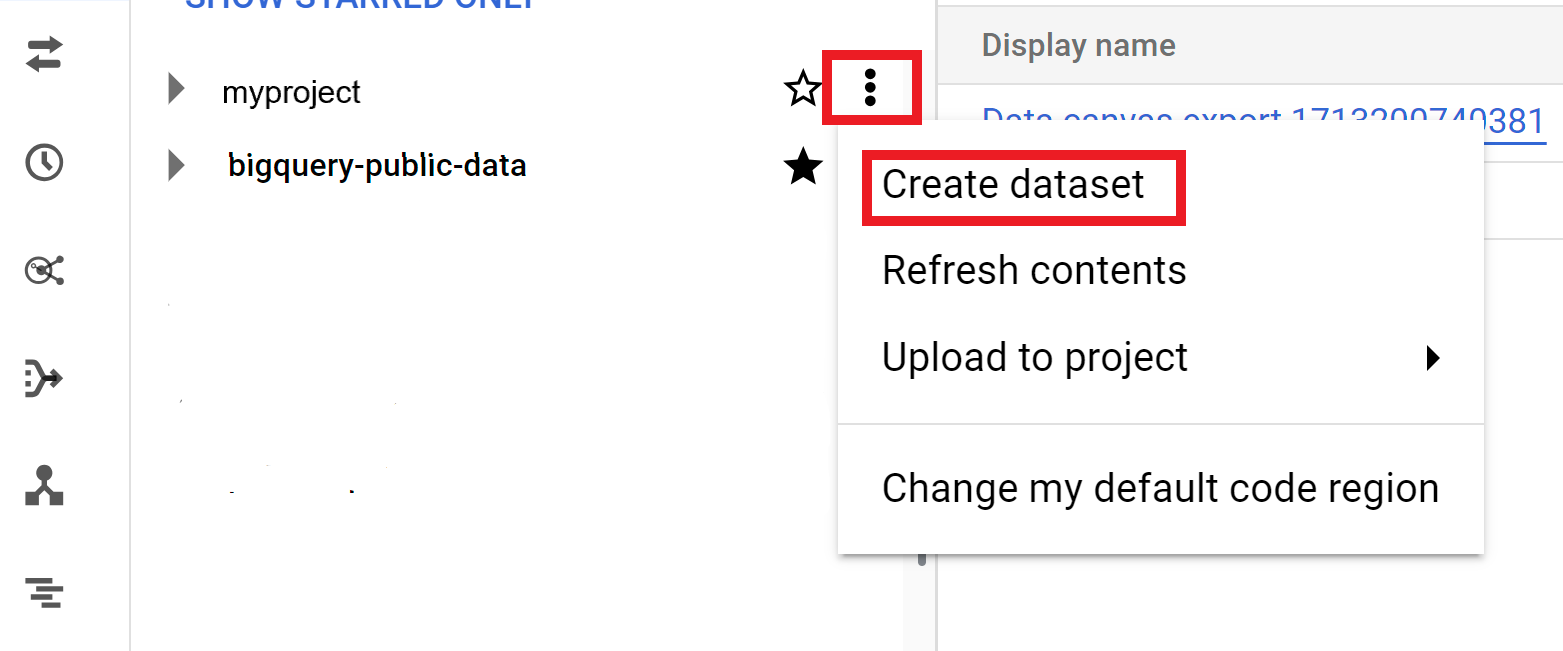
בדף Create dataset:
- בשדה Dataset ID, מזינים שם ייחודי למערך הנתונים.
בשדה Location type, בוחרים מיקום גיאוגרפי לקבוצת הנתונים. אי אפשר לשנות את המיקום אחרי שיוצרים את מערך הנתונים.
אופציונלי. פרטים נוספים על התאמה אישית של מערך הנתונים זמינים במאמר יצירת מערכי נתונים: מסוף.
לוחצים על יצירת מערך נתונים.
BigQuery
כדי ליצור מערך נתונים חדש לנתונים גולמיים, מעתיקים את הפקודה הבאה:
bq --location= LOCATION mk -d SOURCE_PROJECT: DATASET_RAWמחליפים את מה שכתוב בשדות הבאים:
-
LOCATIONעם המיקום של מערך הנתונים. -
SOURCE_PROJECTבמזהה פרויקט המקור. -
DATASET_RAWבשם של קבוצת הנתונים של הנתונים הגולמיים. לדוגמה,CORTEX_SFDC_RAW.
-
כדי ליצור מערך נתונים חדש לנתוני CDC, מעתיקים את הפקודה הבאה:
bq --location=LOCATION mk -d SOURCE_PROJECT: DATASET_CDCמחליפים את מה שכתוב בשדות הבאים:
-
LOCATIONעם המיקום של מערך הנתונים. -
SOURCE_PROJECTבמזהה פרויקט המקור. -
DATASET_CDCבשם של מערך הנתונים שלכם לנתוני CDC. לדוגמה,CORTEX_SFDC_CDC.
-
מריצים את הפקודה הבאה כדי לוודא שערכות הנתונים נוצרו:
bq lsאופציונלי. מידע נוסף על יצירת מערכי נתונים זמין במאמר יצירת מערכי נתונים.
השלבים הבאים
אחרי שמסיימים את השלב הזה, עוברים לשלבי הפריסה הבאים:
- הגדרת עומסי עבודה (הדף הזה).
- שכפול המאגר.
- קובעים את מנגנון השילוב.
- הגדרת רכיבים
- הגדרת הפריסה.
- הפעלת הפריסה.