
Migra de Aerospike a Bigtable
En este documento, se explica el proceso de migración de datos de Aerospike a Bigtable. Describe cómo usar herramientas de código abierto, como la biblioteca de adaptadores, para realizar la migración.
Antes de comenzar la migración, familiarízate con Bigtable para usuarios de Aerospike.
Descripción general de la migración
Puedes migrar tus datos de Aerospike a Bigtable con un tiempo de inactividad mínimo o nulo.
En el siguiente diagrama, se describen los pasos de la migración:
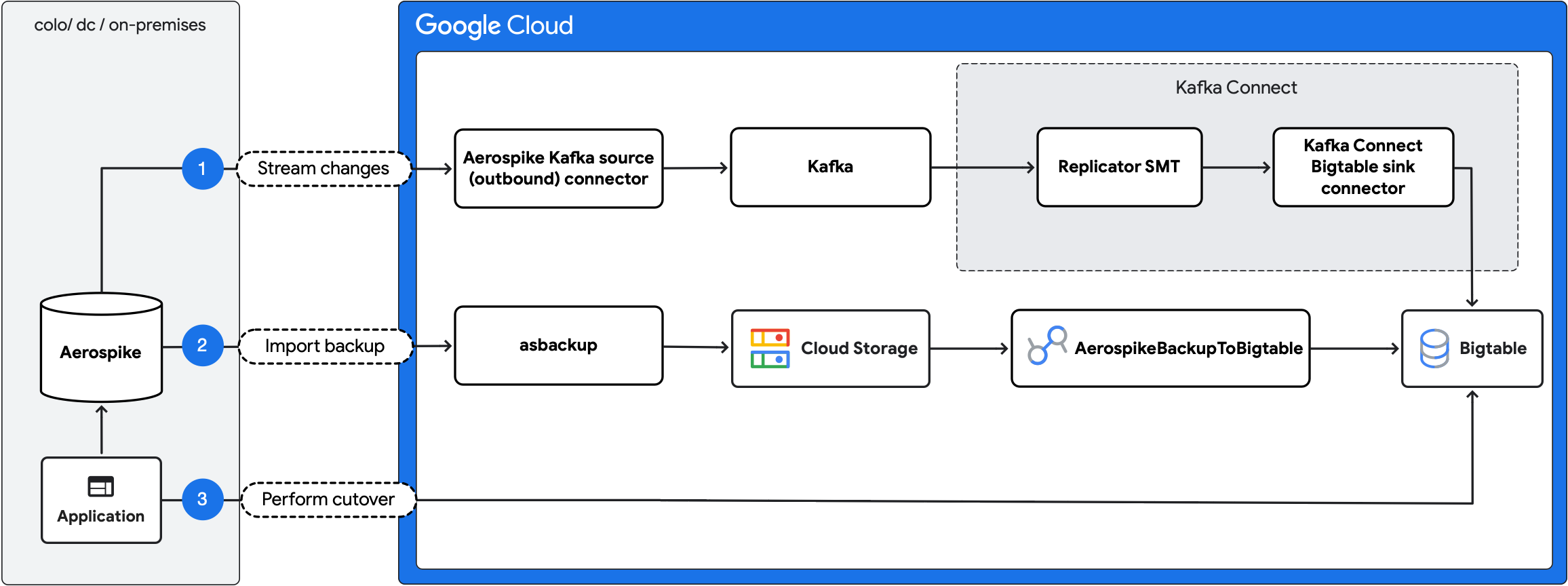
- Transmite los cambios en curso: Replica las actualizaciones en curso de Aerospike a Bigtable con el conector de origen de Aerospike Kafka (saliente) y el conector de receptor de Bigtable de Kafka Connect.
- Importar copia de seguridad: Crea una copia de seguridad de Aerospike y, luego, impórtala a Bigtable con el trabajo de
AerospikeBackupToBigtableDataflow. - Realiza la migración de sistemas: Mueve el tráfico de la aplicación a Bigtable.
Alcance y compatibilidad de la migración
Dado que Bigtable opera en bytes sin procesar en lugar de contenedores con tipo, el proceso de migración implica asignar las capacidades y funciones de Aerospike a estructuras compatibles de Bigtable. La biblioteca de adaptadores proporciona las herramientas necesarias para lograr la compatibilidad estructural y abordar las brechas, como la serialización de objetos. Sin embargo, ciertas funciones, como las funciones definidas por el usuario (UDF), no se pueden migrar debido a las diferencias fundamentales entre los sistemas.
En la siguiente tabla, se resume cómo el proceso de migración controla las capacidades de Aerospike.
| Función | Asistencia | Descripción |
|---|---|---|
| Arquitectura de memoria híbrida (HMA) de Aerospike | Admitido | Se migró al nivel de almacenamiento SSD o al nivel en memoria. La edición Enterprise Plus de Bigtable proporciona acceso al almacenamiento en la memoria para cargas de trabajo sensibles a la latencia que requieren tiempos de respuesta de submilisegundos similares al rendimiento de Aerospike. |
Escalares (Int, Float, String, Bool) |
Admitido | Se migraron a celdas de Bigtable. |
| Listas y mapas | Admitido | Los mapas deben tener claves de cadena. La biblioteca del adaptador serializa las listas y los mapas en columnas separadas. |
| Índices secundarios | Parcialmente compatible | No se migró directamente. Se debe volver a implementar como índices secundarios asíncronos. |
| Tiempo de actividad (TTL) a nivel del registro | Admitido | Se configura a nivel de la familia de columnas o se simula por celda en Bigtable. |
| UDFs | No compatible | La lógica personalizada del servidor se debe trasladar a la aplicación del cliente. |
| HyperLogLog | No compatible | No se admite en el proceso de migración. |
| GeoJSON | No compatible | No se admite en el proceso de migración. |
| Claves de registro | No compatible | Las claves de registro no se migran directamente. En cambio, la migración usa el resumen del registro como clave de fila. |
Antes de comenzar
Antes de comenzar la migración, completa los siguientes pasos preparatorios para reducir el riesgo y garantizar una transición sin problemas:
- Valida tus datos: Confirma que la implementación de Aerospike no dependa de tipos de datos, índices secundarios ni UDF no admitidos. Como medida de seguridad, puedes importar un subconjunto representativo de tus datos a Bigtable y validar el diseño del esquema.
- Aprovisiona la infraestructura: Configura los servicios necesarios para la canalización de migración: Bigtable, Kafka y Kafka Connect.
- Planificación de la capacidad: Aprovisiona Bigtable con capacidad suficiente para controlar la carga de trabajo esperada. Selecciona una región cercana al clúster de Aerospike existente. Para obtener orientación sobre cómo estimar los recursos necesarios, consulta Información sobre el rendimiento de Bigtable.
- Nivel de almacenamiento: Para las cargas de trabajo que requieren tiempos de respuesta inferiores a un milisegundo, considera usar el nivel en la memoria de Bigtable. Este nivel almacena datos en la RAM para proporcionar el mayor rendimiento para las aplicaciones con muchas lecturas o sensibles a la latencia. Para obtener más información, consulta Descripción general del nivel en memoria.
- Configura el acceso y las redes: Asigna los roles de Identity and Access Management (IAM) adecuados y garantiza la conectividad de red.
- Habilita la supervisión y los informes de errores: Configura la observabilidad para el nuevo entorno, incluidos los registros, las métricas y las alertas.
- Registra el rendimiento de referencia: Registra el rendimiento actual del sistema para proporcionar una referencia para validarlo después de la migración.
- Crea copias de seguridad: Crea una copia de seguridad completa de tus datos de Aerospike.
- Ejecuta una migración de prueba: Valida la configuración en un entorno de etapa de pruebas antes de intentar una migración de producción.
Migrar datos
Completa los siguientes pasos para migrar tus datos de Aerospike a Bigtable.
Inicia el flujo de cambios
Cuando habilitas el flujo de cambios de Aerospike, el conector de origen de Aerospike Kafka (saliente) comienza a publicar las actualizaciones de registros de Aerospike en un tema de Kafka. Asegúrate de que Kafka tenga suficiente capacidad de almacenamiento para almacenar en búfer los cambios y configura el conector para que genere datos en formato JSON.
A continuación, se muestra un ejemplo de configuración del conector de Kafka:
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
La comunicación con Kafka a través del conector de origen (saliente) de Aerospike Kafka requiere la replicación entre centros de datos (XDR) de Aerospike, que replica de forma asíncrona los cambios del clúster a través de vínculos de mayor latencia. XDR solo está disponible en la edición Enterprise de Aerospike. Si usas Aerospike Community Edition, cambia a Enterprise Edition o realiza una migración sin conexión usando solo el trabajo de Dataflow AerospikeBackupToBigtable.
Un ejemplo de configuración para XDR en Aerospike se ve de la siguiente manera:
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
Exporta datos desde Aerospike
Después de iniciar el flujo de cambios, genera una copia de seguridad del conjunto de datos existente de Aerospike. Usa la herramienta de línea de comandos de asbackup para crear copias de seguridad desde un clúster de bases de datos de Aerospike. Es posible que algunas actualizaciones aparezcan tanto en la copia de seguridad como en el flujo de cambios, lo que es normal y no afecta la migración. Para permitir importaciones paralelas durante el restablecimiento, divide las copias de seguridad en varios archivos.
Importa datos a Bigtable
Para importar datos de copia de seguridad a Bigtable, haz lo siguiente:
- Sube la copia de seguridad a un bucket de Cloud Storage.
- Ejecuta el trabajo de Dataflow
AerospikeBackupToBigtablepara importar la copia de seguridad a Bigtable. Si la copia de seguridad se divide en varios archivos, el trabajo los procesa en paralelo. Para controlar el aumento de la carga de escritura y mantener una capacidad de procesamiento óptima, aprovisiona recursos adicionales de Bigtable.
Aplica las actualizaciones de registros a Bigtable
Después de importar la copia de seguridad a Bigtable, aplica las actualizaciones de registros almacenados en búfer en Kafka a Bigtable con el conector de receptor de Kafka Connect Bigtable.
Traduce mensajes a un formato compatible
Las herramientas de migración de Aerospike incluyen el SMT de replicador, que se ejecuta dentro de Kafka Connect. El replicador traduce los mensajes que publica el conector de origen de Aerospike Kafka (saliente) a un formato compatible con el receptor de destino que escribe los registros en Bigtable. Se requiere la traducción porque el receptor espera datos en un formato específico que difiere de la forma en que Aerospike transmite los cambios.
En la siguiente tabla, se te ayuda a estimar los recursos de la máquina necesarios para lograr una capacidad de procesamiento determinada:
| Estructura del registro | Capacidad de procesamiento | Latencia del percentil 99 |
|---|---|---|
| Plano | Hasta 3,700 registros por segundo por CPU virtual | 300 ms |
| Anidados | Hasta 2,600 registros por segundo por CPU virtual | 300 ms |
En estas estimaciones, se supone que los registros serializados en formato JSON tienen un tamaño de 1 KB. El tiempo de análisis aumenta con la complejidad de las estructuras de mensajes, lo que significa que los objetos anidados almacenados en los registros de Aerospike tardan más en analizarse.
Puedes usar la métrica consumer_lag para verificar cuántos mensajes hay en la cola de procesamiento y medir el retraso de replicación. Cuando el receptor procesa el backlog de mensajes en el tema, el rezago del consumidor disminuye hasta estabilizarse cerca de cero, momento en el que el receptor procesa las actualizaciones de Aerospike casi en tiempo real, lo que te prepara para la migración. Puedes usar sink-record-active-count para verificar la cantidad de mensajes ya procesados.
Transfiere mensajes con el conector receptor de Kafka Connect Bigtable
El conector receptor de Bigtable de Kafka Connect transmite mensajes de Kafka a Bigtable. Cuando configures el conector, establece insert.mode en REPLACE_IF_NEWEST para asegurarte de que el registro escrito en la fila de destino en Bigtable sea el más reciente. Para obtener más información, consulta Configuración del conector de receptor de Bigtable de Kafka Connect.
En la siguiente tabla, se proporciona orientación sobre la latencia introducida y los recursos de procesamiento necesarios para diferentes cargas de trabajo:
| Estructura del registro | Capacidad de procesamiento | Latencia del percentil 99 |
|---|---|---|
| Plano | Hasta 3,700 registros por segundo por CPU virtual | 74 ms |
| Anidados | Hasta 3,700 registros por segundo por CPU virtual | 100 ms |
En estas estimaciones, se supone que los registros serializados en formato JSON tienen un tamaño de 1 KB. La latencia informada es el tiempo de procesamiento en el receptor. Supón una sobrecarga adicional de aproximadamente 600 ms para realizar una solicitud de escritura en Bigtable.
Cómo cambiar a Bigtable
Cambia la aplicación para que use Bigtable como la base de datos principal.
Para garantizar la coherencia de lectura y escritura, cierra temporalmente la aplicación hasta que el retraso de la replicación llegue a cero. Esto garantiza que no se pierdan mutaciones y que las lecturas de datos reflejen el estado más reciente.
Por ejemplo, es posible que una mutación aplicada en Aerospike justo antes de la migración de sistemas no se haya replicado aún en Bigtable, lo que provoca lecturas obsoletas. Para evitar esta situación, mantén la aplicación sin conexión hasta que las métricas consumer_lag y sink-record-active-count alcancen el valor 0. Después de que se propaguen todos los cambios pendientes, reinicia la aplicación con Bigtable como la base de datos principal.
Si bien una migración en vivo puede evitar el tiempo de inactividad, tiene las siguientes restricciones:
- Las mutaciones que se aplican en Bigtable no se replican en Aerospike.
- Es posible que las mutaciones que se originan en Aerospike aparezcan en Bigtable con un retraso.
- Las mutaciones retrasadas de Aerospike pueden reemplazar las actualizaciones más recientes en Bigtable.
Verifica la implementación
Después de la implementación, valida el rendimiento de la aplicación revisando métricas como las tasas de error, la latencia y el costo. También puedes realizar verificaciones de integridad de los datos.
Supervisión y observabilidad
Supervisa las siguientes métricas durante la migración:
- Retraso total: Se calcula como el retraso del consumidor de Kafka más el
sink-record-active-count. Estas métricas indican qué tan rezagado está Bigtable en comparación con Aerospike. Se requiere un valor de rezago estable antes de redireccionar el tráfico a Bigtable. - Utilización de CPU y memoria: Supervisa la utilización de CPU y memoria de todos los componentes de la canalización de flujo de cambios.
- Capacidad de almacenamiento de Kafka: Supervisa la capacidad de las implementaciones de Kafka autoadministradas. Si se llena el almacenamiento, no se pueden almacenar en búfer los eventos nuevos, lo que provoca una falla en la migración.
- Tasas de error de la aplicación: Supervisa las tasas de error y los resultados de error de todos los elementos de la canalización de transmisiones de cambios.
Limitaciones
En las siguientes secciones, se describen las limitaciones que debes tener en cuenta cuando migres datos de Aerospike a Bigtable.
Coherencia de los datos durante la migración
Cuando usas la herramienta asbackup para generar la copia de seguridad de Aerospike, es posible que se excluyan los registros modificados durante el proceso de copia de seguridad, ya que este no admite copias de seguridad atómicas. Esta limitación no afecta la corrección, ya que todos los cambios aparecen en el flujo de cambios.
Durante la importación de la copia de seguridad a Bigtable, cada fila se escribe con una marca de tiempo de la hora de la última actualización (LUT) de 0.
Las actualizaciones del flujo de cambios se aplican sobre la copia de seguridad importada. Las filas escritas desde la transmisión usan el valor de la LUT como la marca de tiempo de la fila de Bigtable. La configuración del receptor hace que la actualización con una marca de tiempo más reciente anule una más antigua. Esto garantiza que cualquier cambio que se reproduzca desde el flujo sobrescriba la fila correspondiente.
Uso de la LUT
El proceso de migración usa Aerospike XDR para replicar los cambios y se basa en la LUT para la resolución de conflictos. Debido a que las LUT se basan en el reloj del sistema del nodo, es posible que no sean estrictamente monotónicas. Como resultado, es posible que, en ocasiones, un registro desactualizado tenga una LUT más reciente y sobrescriba un registro más reciente. Además, es posible que el conector de origen (saliente) de Aerospike Kafka no conserve el orden exacto de los mensajes cuando se publiquen en Kafka. Como resultado, la LUT sirve como marcador de versión autorizada, lo que garantiza que solo se apliquen a Bigtable los registros con la LUT más reciente.
Si un registro se actualiza después de que inicias el flujo de cambios, pero antes de que generes la copia de seguridad, es posible que la copia de seguridad capture la versión más reciente, mientras que el flujo contiene una versión anterior. Es posible que esta versión anterior reemplace temporalmente a la más reciente. Sin embargo, cuando llega el evento de transmisión posterior con la LUT correcta, se restablece la versión más reciente. Para evitar incoherencias, espera a realizar la migración de sistemas hasta que se estabilice la replicación y el mensaje no procesado más antiguo de la canalización sea más reciente que la copia de seguridad.
Validación de datos
La canalización de migración no realiza la suma de verificación de los datos en tránsito. Si necesitas verificaciones de integridad de los datos de extremo a extremo, debes implementar la validación.
Soluciona problemas
En las siguientes secciones, se describen los errores comunes que pueden ocurrir durante el proceso de migración y se brindan instrucciones para resolverlos.
Errores de importación de copias de seguridad
Durante la importación de la copia de seguridad de Aerospike en Bigtable, es posible que surjan los siguientes errores:
| Tipo de error | Causa | Solución |
|---|---|---|
| Archivo de copia de seguridad dañado | Los archivos de copia de seguridad no se pueden leer o contienen registros dañados. Falla el trabajo de importación. | Inspecciona los archivos afectados para detectar problemas de integridad. Si no se puede recuperar, genera una copia de seguridad nueva y repite la importación. |
| Fallas de escritura de Bigtable | Se producen problemas de conectividad o servicio de Bigtable. La importación no falla. | Los registros con errores se exportan a un archivo de salida de errores en formato JSON. Vuelve a aplicarlos de forma manual o vuelve a intentar el trabajo de importación completo. |
| Datos no compatibles | La copia de seguridad contiene entradas que no se pueden importar a Bigtable. La importación no falla. | Los datos no admitidos, como las UDF, se registran como advertencias en los registros de trabajos. Revisa los registros para verificar las entradas no admitidas. |
Una vez que se complete la importación de la copia de seguridad y se solucionen los registros no válidos, podrás aplicar el flujo de cambios.
Errores de flujo de cambios
Durante la aplicación del flujo de cambios, pueden producirse errores en los siguientes niveles:
- Errores de SMT del replicador: El SMT no puede transformar los datos que produce Aerospike.
- Errores de receptor: Los eventos no se pueden aplicar a Bigtable.
En ambos casos, los eventos fallidos se redireccionan a un tema de Kafka dedicado. Puedes registrar los eventos para realizar auditorías o procesarlos con una lógica de recuperación personalizada.
¿Qué sigue?
- Aprende a diseñar tu esquema de Bigtable.
- Lee sobre cómo iniciar la migración a Google Cloud.
- Comprende qué estrategias tienes para transferir grandes conjuntos de datos.