
Von Aerospike zu Bigtable migrieren
In diesem Dokument wird beschrieben, wie Sie Daten von Aerospike zu Bigtable migrieren. Darin wird beschrieben, wie Sie Open-Source-Tools wie die Adapterbibliothek für die Migration verwenden.
Bevor Sie mit der Migration beginnen, sollten Sie sich mit Bigtable für Aerospike-Nutzer vertraut machen.
Übersicht über die Migration
Sie können Ihre Daten mit minimalen oder keinen Ausfallzeiten von Aerospike zu Bigtable migrieren.
Das folgende Diagramm veranschaulicht die Migrationsschritte:
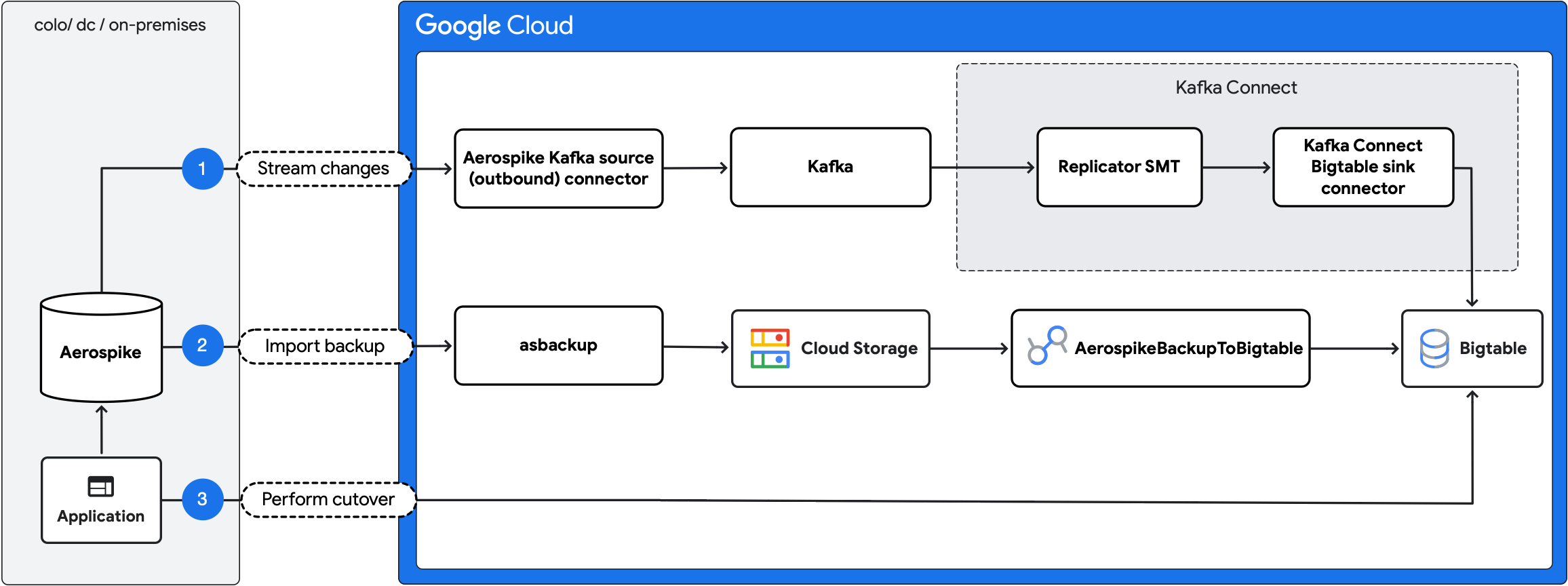
- Laufende Änderungen streamen:Laufende Aktualisierungen von Aerospike zu Bigtable replizieren. Verwenden Sie dazu den Aerospike Kafka-Quellconnector (ausgehend) und den Kafka Connect Bigtable-Senkenconnector.
- Sicherung importieren:Erstellen Sie eine Aerospike-Sicherung und importieren Sie sie mit dem
AerospikeBackupToBigtable-Dataflow-Job in Bigtable. - Umstellung durchführen:Verschieben Sie den Anwendungs-Traffic zu Bigtable.
Migrationsumfang und ‑kompatibilität
Da Bigtable mit Rohbytes und nicht mit typisierten Bins arbeitet, müssen beim Migrationsprozess Aerospike-Funktionen und ‑Features kompatiblen Bigtable-Strukturen zugeordnet werden. Die Adapterbibliothek bietet die erforderlichen Tools, um die strukturelle Kompatibilität zu erreichen und Lücken wie die Objektserialisierung zu schließen. Bestimmte Funktionen wie benutzerdefinierte Funktionen (UDFs) können jedoch aufgrund grundlegender Unterschiede zwischen den Systemen nicht migriert werden.
In der folgenden Tabelle wird zusammengefasst, wie die Aerospike-Funktionen im Migrationsprozess behandelt werden.
| Funktion | Unterstützung | Beschreibung |
|---|---|---|
| Aerospike Hybrid Memory Architecture (HMA) | Unterstützt | entweder zur SSD-Speicherebene oder zur In-Memory-Ebene migriert. Die Bigtable Enterprise Plus-Version bietet Zugriff auf In-Memory-Speicher für latenzempfindliche Arbeitslasten, die Antwortzeiten von weniger als einer Millisekunde erfordern, ähnlich wie bei Aerospike. |
Skalare (Int, Float, String, Bool) |
Unterstützt | Zu Bigtable migrierte Zellen. |
| Listen und Karten | Unterstützt | Maps müssen String-Schlüssel haben. Listen und Karten werden von der Adapterbibliothek in separate Spalten serialisiert. |
| Sekundäre Indexe | Teilweise unterstützt | Werden nicht direkt migriert. Muss als asynchrone sekundäre Indexe neu implementiert werden. |
| Gültigkeitsdauer (TTL) auf Datensatzebene | Unterstützt | Auf der Ebene der Spaltenfamilie konfiguriert oder pro Zelle in Bigtable simuliert. |
| Nutzerdefinierte Funktionen | Nicht unterstützt | Benutzerdefinierte serverseitige Logik muss in die clientseitige Anwendung verschoben werden. |
| HyperLogLog | Nicht unterstützt | Wird bei der Migration nicht unterstützt. |
| GeoJSON | Nicht unterstützt | Wird bei der Migration nicht unterstützt. |
| Datensatzschlüssel | Nicht unterstützt | Datensatzschlüssel werden nicht direkt migriert. Stattdessen wird bei der Migration der Datensatz-Digest als Zeilenschlüssel verwendet. |
Hinweis
Führen Sie vor der Migration die folgenden vorbereitenden Schritte aus, um das Risiko zu minimieren und einen reibungslosen Übergang zu gewährleisten:
- Daten validieren:Prüfen Sie, ob für die Aerospike-Bereitstellung nicht unterstützte Datentypen, sekundäre Indexe oder UDFs verwendet werden. Als Sicherheitsmaßnahme können Sie eine repräsentative Teilmenge Ihrer Daten in Bigtable importieren und das Schemadesign validieren.
- Infrastruktur bereitstellen:Richten Sie die für die Migrationspipeline erforderlichen Dienste ein: Bigtable, Kafka und Kafka Connect.
- Kapazitätsplanung: Stellen Sie Bigtable mit ausreichender Kapazität für die erwartete Arbeitslast bereit. Wählen Sie eine Region in der Nähe des vorhandenen Aerospike-Clusters aus. Informationen zum Schätzen der erforderlichen Ressourcen finden Sie unter Informationen zur Leistung von Bigtable.
- Speicherstufe: Für Arbeitslasten, die Reaktionszeiten von unter einer Millisekunde erfordern, sollten Sie die In-Memory-Stufe von Bigtable verwenden. In dieser Ebene werden Daten im RAM gespeichert, um die höchste Leistung für leseintensive oder latenzempfindliche Anwendungen zu bieten. Weitere Informationen finden Sie unter Übersicht über die In-Memory-Ebene.
- Zugriff und Netzwerk konfigurieren:Weisen Sie die entsprechenden IAM-Rollen (Identity and Access Management) zu und sorgen Sie für die Netzwerkverbindung.
- Monitoring und Fehlerberichte aktivieren:Konfigurieren Sie die Beobachtbarkeit für die neue Umgebung, einschließlich Logging, Messwerte und Benachrichtigungen.
- Benchmark-Baseline-Leistung ermitteln:Erfassen Sie die aktuelle Systemleistung, um eine Referenz für die Validierung nach der Migration zu haben.
- Sicherungen erstellen:Erstellen Sie eine vollständige Sicherung Ihrer Aerospike-Daten.
- Testmigration durchführen:Validieren Sie die Einrichtung in einer Staging-Umgebung, bevor Sie eine Produktionsmigration durchführen.
Daten migrieren
Führen Sie die folgenden Schritte aus, um Ihre Daten von Aerospike zu Bigtable zu migrieren.
Änderungsstream initiieren
Wenn Sie den Aerospike-Änderungsstream aktivieren, beginnt der Aerospike-Kafka-Quell-Connector (ausgehend), die Aerospike-Datensatzaktualisierungen in einem Kafka-Thema zu veröffentlichen. Achten Sie darauf, dass Kafka genügend Speicherkapazität hat, um die Änderungen zu puffern, und konfigurieren Sie den Connector so, dass Daten im JSON-Format ausgegeben werden.
Hier sehen Sie eine Beispielkonfiguration für einen Kafka-Connector:
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
Für die Kommunikation mit Kafka über den Aerospike Kafka-Quell-Connector (ausgehend) ist Aerospike Cross-Datacenter Replication (XDR) erforderlich, mit der Clusteränderungen asynchron über Links mit höherer Latenz repliziert werden. XDR ist nur in der Aerospike Enterprise Edition verfügbar. Wenn Sie die Aerospike Community Edition verwenden, wechseln Sie zur Enterprise Edition oder führen Sie eine Offlinemigration nur mit dem AerospikeBackupToBigtable-Dataflow-Job durch.
Eine Beispielkonfiguration für XDR in Aerospike sieht so aus:
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
Daten aus Aerospike exportieren
Nachdem Sie den Änderungsstream gestartet haben, erstellen Sie eine Sicherung des vorhandenen Aerospike-Datasets. Verwenden Sie das asbackup-Befehlszeilentool, um Back-ups eines Aerospike-Datenbankclusters zu erstellen. Einige Aktualisierungen werden möglicherweise sowohl in der Sicherung als auch im Änderungsstream angezeigt. Das ist normal und hat keine Auswirkungen auf die Migration. Wenn Sie parallele Importe während der Wiederherstellung zulassen möchten, teilen Sie Back-ups in mehrere Dateien auf.
Daten in Bigtable importieren
So importieren Sie gesicherte Daten in Bigtable:
- Laden Sie die Sicherung in einen Cloud Storage-Bucket hoch.
- Führen Sie den Dataflow-Job
AerospikeBackupToBigtableaus, um die Sicherung in Bigtable zu importieren. Wenn die Sicherung auf mehrere Dateien aufgeteilt ist, werden diese parallel verarbeitet. Stellen Sie zusätzliche Bigtable-Ressourcen bereit, um die erhöhte Schreiblast zu bewältigen und den optimalen Durchsatz aufrechtzuerhalten.
Datensatzaktualisierungen auf Bigtable anwenden
Nachdem Sie die Sicherung in Bigtable importiert haben, wenden Sie die gepufferten Datensatzaktualisierungen in Kafka mithilfe des Kafka Connect Bigtable-Senken-Connectors auf Bigtable an.
Nachrichten in ein kompatibles Format übersetzen
Die Aerospike-Migrations-Tools umfassen den Replicator SMT, der in Kafka Connect ausgeführt wird. Der Replikator übersetzt Nachrichten, die vom Aerospike Kafka-Quellconnector (ausgehend) veröffentlicht werden, in ein Format, das mit der Zielsenke kompatibel ist, die die Datensätze in Bigtable schreibt. Die Übersetzung ist erforderlich, da die Senke Daten in einem bestimmten Format erwartet, das sich davon unterscheidet, wie Aerospike Änderungen streamt.
Die folgende Tabelle hilft Ihnen, die für einen bestimmten Durchsatz erforderlichen Maschinenressourcen zu schätzen:
| Eintragsstruktur | Durchsatz | P99-Latenz |
|---|---|---|
| Flach | Bis zu 3.700 Datensätze pro Sekunde und vCPU | 300 ms |
| Verschachtelte Daten | Bis zu 2.600 Datensätze pro Sekunde und vCPU | 300 ms |
Bei diesen Schätzungen wird davon ausgegangen, dass die JSON-serialisierten Datensätze 1 KB groß sind. Die Parsing-Zeit steigt mit der Komplexität der Nachrichtenstrukturen. Das bedeutet, dass das Parsen von verschachtelten Objekten, die in Aerospike-Datensätzen gespeichert sind, länger dauert.
Mit dem Messwert consumer_lag können Sie prüfen, wie viele Nachrichten sich in der Verarbeitungswarteschlange befinden, und die Replikationsverzögerung messen. Wenn die Senke den Rückstand an Nachrichten im Thema abarbeitet, verringert sich die Consumer-Verzögerung, bis sie sich bei null stabilisiert. Dann verarbeitet die Senke Aerospike-Updates nahezu in Echtzeit und Sie sind bereit für die Umstellung. Mit sink-record-active-count können Sie die Anzahl der bereits verarbeiteten Nachrichten prüfen.
Nachrichten mit dem Kafka Connect Bigtable-Sink-Connector aufnehmen
Der Kafka Connect Bigtable-Senken-Connector nimmt Nachrichten von Kafka in Bigtable auf. Wenn Sie den Connector konfigurieren, legen Sie insert.mode auf REPLACE_IF_NEWEST fest, damit der Datensatz, der in die Zielzeile in Bigtable geschrieben wird, der aktuellste ist. Weitere Informationen finden Sie unter Kafka Connect Bigtable-Sink-Connector konfigurieren.
Die folgende Tabelle enthält Informationen zur Latenz und den Rechenressourcen, die für verschiedene Arbeitslasten erforderlich sind:
| Eintragsstruktur | Durchsatz | P99-Latenz |
|---|---|---|
| Flach | Bis zu 3.700 Datensätze pro Sekunde und vCPU | 74 ms |
| Verschachtelte Daten | Bis zu 3.700 Datensätze pro Sekunde und vCPU | 100 ms |
Bei diesen Schätzungen wird davon ausgegangen, dass die JSON-serialisierten Datensätze 1 KB groß sind. Die angegebene Latenz ist die Verarbeitungszeit im Senkenknoten. Gehen Sie von einem zusätzlichen Overhead von etwa 600 ms für eine Schreibanfrage an Bigtable aus.
Zu Bigtable wechseln
Stellen Sie die Anwendung so um, dass Bigtable als primäre Datenbank verwendet wird.
Um die Read-Your-Writes-Konsistenz zu gewährleisten, müssen Sie die Anwendung vorübergehend herunterfahren, bis die Replikationsverzögerung null erreicht. So wird sichergestellt, dass keine Mutationen verloren gehen und dass Datenlesevorgänge den aktuellen Status widerspiegeln.
Eine Mutation, die kurz vor der Umstellung in Aerospike angewendet wurde, wurde möglicherweise noch nicht in Bigtable repliziert, was zu veralteten Lesevorgängen führt. Um dieses Szenario zu vermeiden, sollte die Anwendung offline bleiben, bis die Messwerte consumer_lag und sink-record-active-count den Wert 0 erreichen. Nachdem alle ausstehenden Änderungen weitergegeben wurden, starten Sie die Anwendung mit Bigtable als primäre Datenbank neu.
Durch eine Live-Migration können Ausfallzeiten vermieden werden, es gelten jedoch die folgenden Einschränkungen:
- In Bigtable angewendete Mutationen werden nicht in Aerospike repliziert.
- Mutationen, die von Aerospike stammen, werden möglicherweise mit einer Verzögerung in Bigtable angezeigt.
- Verzögerte Mutationen aus Aerospike können neuere Aktualisierungen in Bigtable überschreiben.
Deployment prüfen
Prüfen Sie nach der Bereitstellung die Anwendungsleistung anhand von Messwerten wie Fehlerraten, Latenz und Kosten. Sie können auch Datenintegritätsprüfungen durchführen.
Monitoring und Beobachtbarkeit
Behalten Sie während der Migration die folgenden Messwerte im Blick:
- Gesamtverzögerung: wird als Kafka-Consumer-Verzögerung plus
sink-record-active-countberechnet. Diese Messwerte geben an, wie weit Bigtable hinter Aerospike zurückliegt. Ein stabiler Verzögerungswert ist erforderlich, bevor Sie den Traffic zu Bigtable umleiten. - CPU- und Arbeitsspeichernutzung: Überwachen Sie die CPU- und Arbeitsspeichernutzung aller Pipelinekomponenten für Änderungsstreams.
- Kafka-Speicherkapazität: Kapazität für selbstverwaltete Kafka-Bereitstellungen überwachen. Wenn der Speicher voll ist, können keine neuen Ereignisse gepuffert werden, was zu einem Migrationsfehler führt.
- Fehlerraten der Anwendung: Überwachen Sie die Fehlerraten und die Fehlerausgaben aller Pipelineelemente des Änderungsstreams.
Beschränkungen
In den folgenden Abschnitten werden die Einschränkungen beschrieben, die bei der Migration von Daten von Aerospike zu Bigtable zu berücksichtigen sind.
Datenkonsistenz während der Migration
Wenn Sie das asbackup-Tool zum Generieren der Aerospike-Sicherung verwenden, werden Datensätze, die während der Sicherung geändert wurden, möglicherweise ausgeschlossen, da der Sicherungsprozess keine atomaren Sicherungen unterstützt. Diese Einschränkung hat keine Auswirkungen auf die Richtigkeit, da alle Änderungen im Änderungsstream angezeigt werden.
Beim Import der Sicherung in Bigtable wird jede Zeile mit einem Zeitstempel für die letzte Aktualisierungszeit (Last Update Time, LUT) von 0 geschrieben.
Aktualisierungen aus dem Änderungsstream werden auf das importierte Back-up angewendet. Für Zeilen, die aus dem Stream geschrieben werden, wird der LUT-Wert als Bigtable-Zeilenzeitstempel verwendet. Durch die Senkenkonfiguration wird das Update mit einem neueren Zeitstempel durch ein älteres überschrieben. So wird sichergestellt, dass jede Änderung, die aus dem Stream wiedergegeben wird, die entsprechende Zeile überschreibt.
Verwendung von LUTs
Beim Migrationsprozess werden Änderungen mit Aerospike XDR repliziert und Konflikte mit LUT behoben. Da LUTs auf der Systemuhr des Knotens basieren, sind sie möglicherweise nicht streng monoton. Daher kann es vorkommen, dass ein veralteter Datensatz eine neuere LUT hat und einen aktuelleren Datensatz überschreibt. Außerdem behält der Aerospike-Kafka-Quellconnector (ausgehend) die genaue Nachrichtenreihenfolge beim Veröffentlichen in Kafka möglicherweise nicht bei. Daher dient die LUT als maßgebliche Versionsmarkierung, sodass nur Datensätze mit der neuesten LUT auf Bigtable angewendet werden.
Wenn ein Datensatz aktualisiert wird, nachdem Sie den Änderungsstream gestartet, aber bevor Sie die Sicherung generiert haben, enthält die Sicherung möglicherweise die neuere Version, während der Stream eine ältere Version enthält. Diese ältere Version kann die neuere Version vorübergehend überschreiben. Wenn jedoch das nachfolgende Streamereignis mit der richtigen LUT eintrifft, wird die letzte Version wiederhergestellt. Um Inkonsistenzen zu vermeiden, sollten Sie mit der Umstellung warten, bis die Replikation stabil ist und die älteste unverarbeitete Nachricht in der Pipeline neuer als das Backup ist.
Datenvalidierung
In der Migrationspipeline werden keine Prüfsummen für Daten bei der Übertragung berechnet. Wenn Sie End-to-End-Datenintegritätsprüfungen benötigen, müssen Sie die Validierung implementieren.
Fehlerbehebung
In den folgenden Abschnitten werden häufige Fehler beschrieben, die während der Migration auftreten können, und es wird erläutert, wie Sie diese beheben können.
Fehler beim Import von Backups
Beim Importieren der Aerospike-Sicherung in Bigtable können die folgenden Fehler auftreten:
| Fehlertyp | Ursache | Lösung |
|---|---|---|
| Beschädigte Sicherungsdatei | Sicherungsdateien sind nicht lesbar oder enthalten beschädigte Datensätze. Der Importjob schlägt fehl. | Prüfen Sie die betroffenen Dateien auf Integritätsprobleme. Wenn die Daten nicht wiederhergestellt werden können, erstellen Sie eine neue Sicherung und wiederholen Sie den Import. |
| Fehler beim Schreiben in Bigtable | Es treten Probleme mit der Bigtable-Verbindung oder dem Bigtable-Dienst auf. Der Import schlägt nicht fehl. | Fehlerhafte Datensätze werden in eine Fehler-Ausgabedatei im JSON-Format exportiert. Wenden Sie sie manuell noch einmal an oder versuchen Sie es noch einmal mit dem vollständigen Importjob. |
| Nicht unterstützte Daten | Die Sicherung enthält Einträge, die nicht in Bigtable importiert werden können. Der Import schlägt nicht fehl. | Nicht unterstützte Daten wie UDFs werden in Joblogs als Warnungen gemeldet. Prüfen Sie die Protokolle, um nicht unterstützte Einträge zu ermitteln. |
Nachdem der Import des Back-ups abgeschlossen und ungültige Datensätze behoben wurden, können Sie den Änderungsstream anwenden.
Fehler bei Änderungsstreams
Beim Anwenden des Änderungsstreams können Fehler auf den folgenden Ebenen auftreten:
- Replicator-SMT-Fehler:SMT kann die von Aerospike erstellten Daten nicht transformieren.
- Senkenfehler:Ereignisse können nicht auf Bigtable angewendet werden.
In beiden Fällen werden fehlgeschlagene Ereignisse an ein dediziertes Kafka-Thema weitergeleitet. Sie können die Ereignisse für das Audit-Log erfassen oder mit benutzerdefinierter Wiederherstellungslogik verarbeiten.
Nächste Schritte
- Mehr über das Bigtable-Schema erfahren
- Informationen zum Starten der Migration zu Google Cloud
- Informieren Sie sich über Ihre Strategien für die Übertragung großer Datasets.