
Lakehouse untuk Apache Iceberg adalah platform lakehouse data terkelola di Google Cloud. Intinya adalah katalog runtime Lakehouse, layanan metastore serverless yang terkelola sepenuhnya yang berfungsi sebagai sumber tepercaya tunggal untuk data Anda. Dengan memusatkan metadata ini, beberapa mesin pemrosesan—termasuk Apache Spark, Apache Flink, Apache Hive, dan BigQuery—dapat berbagi tabel dengan lancar tanpa menduplikasi file.
Untuk menghubungkan mesin kueri Anda ke metastore, Anda mengonfigurasi klien menggunakan jenis katalog seperti katalog REST Apache Iceberg. Tindakan ini akan membuat endpoint pengelolaan dalam katalog runtime Lakehouse untuk menangani metadata tabel, sekaligus mengandalkan Cloud Storage untuk menyimpan metadata dan file data pokok.
Kemampuan utama
Sebagai komponen utama Lakehouse untuk Apache Iceberg, katalog runtime Lakehouse memberikan beberapa keuntungan untuk pengelolaan dan analisis data, termasuk arsitektur serverless, interoperabilitas mesin dengan API terbuka, pengalaman pengguna yang terpadu, serta analisis, streaming, dan AI berperforma tinggi saat Anda menggunakannya dengan BigQuery. Untuk mengetahui informasi selengkapnya tentang manfaat ini, lihat Apa itu Lakehouse?
Cara Lakehouse berintegrasi dengan Google Cloud
Untuk memahami cara Lakehouse mengelola data Anda, lihat cara arsitektur Lakehouse untuk Apache Iceberg terintegrasi dengan layanan Google Cloud . Apache Iceberg tidak menyimpan data dalam tabel monolitik. Sebagai gantinya, ia menggunakan arsitektur file metadata berlapis untuk mengatur file data ke dalam struktur tabel yang kohesif dengan dukungan transaksi ACID.
Diagram berikut menggambarkan cara mesin komputasi seperti Managed Service untuk Apache Spark menggunakan katalog runtime Lakehouse untuk mengelola metadata tabel guna membaca dan menulis file data Parquet yang mendasarinya secara langsung di Cloud Storage.
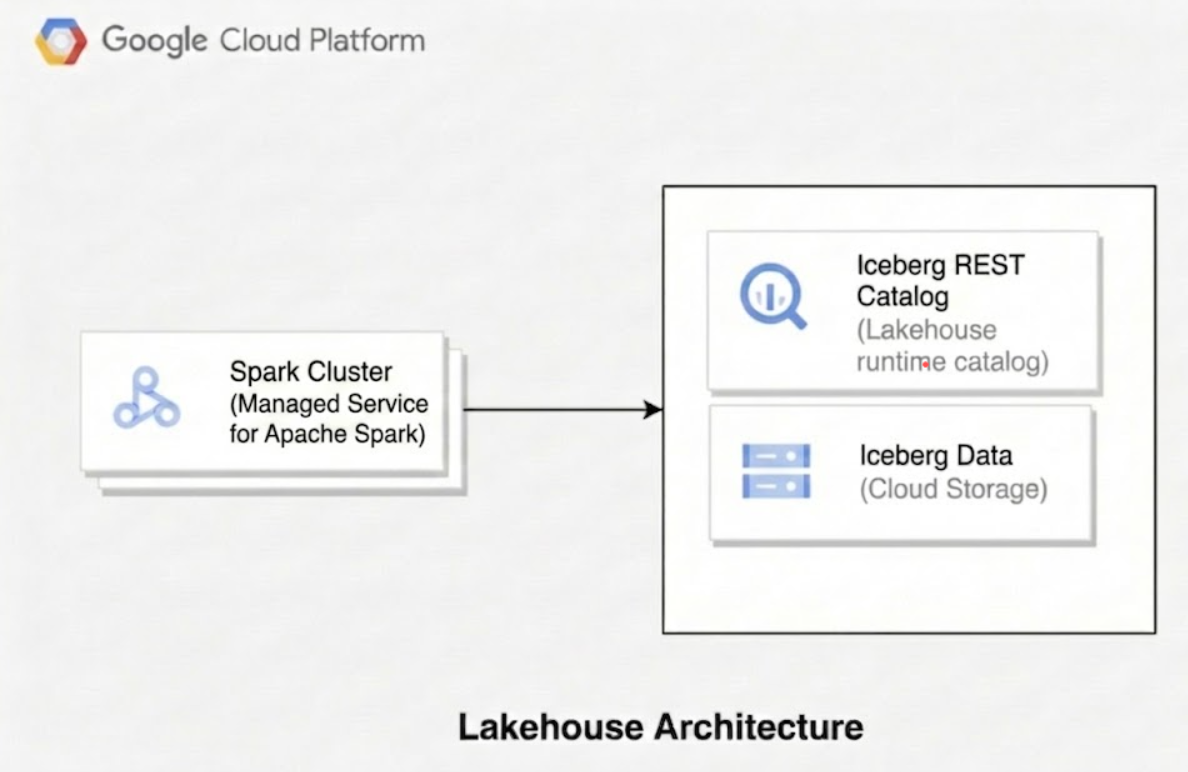
Saat Anda menggunakan Lakehouse untuk Apache Iceberg, arsitektur teknisnya terdiri dari tiga lapisan berbeda:
Lapisan katalog:
- Konsep inti Iceberg: Katalog menyimpan status tabel saat ini dengan mempertahankan penunjuk ke file metadata terbaru. Lapisan ini memfasilitasi kepatuhan ACID dan isolasi transaksi untuk memastikan bahwa operasi tulis serentak tidak saling mengganggu.
- Implementasi Lakehouse: Katalog runtime Lakehouse berfungsi sebagai layanan metastore regional tingkat teratas. Dalam layanan ini, Anda akan membuat katalog individual untuk mengelola hierarki data Anda. Mesin kueri klien terhubung ke katalog ini menggunakan jenis katalog endpoint tertentu, seperti endpoint katalog REST Apache Iceberg. Metastore mengelola commit transaksi, penyediaan kredensial untuk delegasi akses penyimpanan, dan pengelolaan pointer di seluruh katalog Anda.
Lapisan metadata:
- Konsep inti Iceberg: Lapisan ini melacak struktur tabel, snapshot, dan lokasi file menggunakan hierarki tiga jenis file:
- File metadata: Menyimpan skema tabel, spesifikasi partisi, dan log penunjuk snapshot.
- Daftar manifes: Merepresentasikan satu snapshot tabel dengan mengelompokkan kumpulan file manifes.
- File manifes: Melacak data di tingkat file individual, menyimpan jalur file, informasi partisi, dan statistik tingkat kolom, misalnya, jumlah baris serta nilai minimum dan maksimum, yang digunakan untuk pengoptimalan kueri dan penghapusan partisi.
- Implementasi lakehouse: Dalam penampung katalog,
Anda mengatur data ke dalam namespace logis (mirip dengan
set data) dan tabel. Untuk setiap tabel, katalog runtime Lakehouse membuat dan mengelola hierarki metadata Iceberg yang mendasarinya, dimulai dengan file
metadata.jsonroot yang menunjuk ke daftar manifes dan file manifes. Katalog runtime Lakehouse menyimpan file ini langsung di lokasi penyimpanan gudang data yang Anda tetapkan.
- Konsep inti Iceberg: Lapisan ini melacak struktur tabel, snapshot, dan lokasi file menggunakan hierarki tiga jenis file:
Lapisan data:
- Konsep inti Iceberg: Komponen ini adalah penyimpanan dasar tempat catatan data mentah aktual berada, biasanya dalam format file terbuka berbasis kolom atau baris yang dioptimalkan seperti Parquet, ORC, atau Avro.
- Implementasi lakehouse: Saat Anda mengonfigurasi lokasi warehouse Cloud Storage (
bl://ataugs://), file data fisik yang dirujuk oleh tabel Anda akan disimpan dengan aman dalam bucket Anda. Katalog runtime Lakehouse mengelola akses melalui delegasi akses penyimpanan (penyediaan kredensial), yang menyediakan token akses berumur pendek langsung ke mesin klien. Hal ini memungkinkan mesin membaca dan menulis file data secara aman tanpa memerlukan izin IAM langsung yang luas pada bucket yang mendasarinya.
Cara Lakehouse menerapkan Apache Iceberg REST Catalog API
Katalog runtime Lakehouse menerapkan Apache Iceberg REST Catalog API open source untuk mengelola namespace dan tabel. API ini juga menyediakan extensions API khusus untuk pengelolaan katalog.
Mesin kueri klien berinteraksi dengan metastore menggunakan API katalog REST standar ini. Untuk mengetahui detail tentang resource dan endpoint Google Cloud, lihat Referensi Lakehouse REST API.
Anda dapat membuat, mengonfigurasi, dan mengelola resource ini menggunakan konsolGoogle Cloud , gcloud CLI, REST API, atau Terraform. Untuk mengetahui informasi selengkapnya, lihat halaman berikut:
- Mengelola resource katalog REST Iceberg
- Mengelola tabel katalog REST Lakehouse Iceberg
- Menggunakan Terraform dengan Lakehouse
Kompatibilitas dan konfigurasi mesin kueri
Untuk menganalisis dan mengelola data dalam katalog runtime Lakehouse, Anda dapat menghubungkan berbagai mesin kueri open source dan perusahaan. Bergantung pada arsitektur yang ada dan persyaratan beban kerja, Anda dapat memilih dari beberapa mesin yang didukung dan mengonfigurasi endpoint katalog yang sesuai.
Mesin yang didukung
Katalog runtime Lakehouse kompatibel dengan beberapa mesin kueri, termasuk (tetapi tidak terbatas pada) Apache Spark, Apache Flink, Apache Hive, dan Trino. Tabel berikut menyediakan link ke dokumentasi untuk setiap mesin:
| Engine | Dokumentasi |
|---|---|
| Apache Spark | Panduan memulai: Menggunakan Spark dan endpoint katalog REST Iceberg |
| Apache Hive | Menggunakan Spark dan katalog Hive |
| Apache Flink | Gunakan dengan Apache Flink |
| Trino | Gunakan dengan Trino |
Jenis katalog dan konfigurasi endpoint
Saat mengonfigurasi mesin klien untuk terhubung ke metastore katalog runtime Lakehouse, Anda memilih endpoint katalog tertentu, seperti endpoint katalog REST Apache Iceberg atau endpoint Apache Hive. Opsi terbaik bergantung pada kasus penggunaan Anda, seperti yang ditunjukkan dalam tabel berikut:
| Kasus penggunaan | Rekomendasi |
|---|---|
| Pengguna katalog runtime Lakehouse baru yang ingin mesin open source-nya mengakses data di Cloud Storage dan memerlukan interoperabilitas dengan mesin lain, termasuk BigQuery dan AlloyDB untuk PostgreSQL. | Gunakan endpoint katalog REST Apache Iceberg. |
| Pengguna yang menjalankan workload Apache Hive atau Spark yang bergantung pada antarmuka Hive Metastore dan menginginkan layanan metastore yang terkelola sepenuhnya. | Gunakan endpoint katalog Apache Hive. |
| Pengguna katalog runtime Lakehouse yang sudah ada dan memiliki tabel saat ini yang dibuat dengan katalog Apache Iceberg kustom untuk endpoint BigQuery. | Terus gunakan endpoint katalog Apache Iceberg kustom untuk BigQuery, tetapi gunakan katalog REST Apache Iceberg untuk alur kerja baru. Tabel yang dibuat dengan endpoint katalog Apache Iceberg kustom untuk BigQuery terlihat dengan endpoint katalog REST Apache Iceberg melalui federasi katalog BigQuery. |
Batasan katalog runtime lakehouse
Batasan umum berikut berlaku untuk tabel dalam katalog runtime Lakehouse saat menjalankan kueri melalui BigQuery. Endpoint katalog individual (seperti Apache Iceberg REST atau Apache Hive) mungkin memiliki batasan tambahan khusus endpoint.
Pengelolaan tabel
- Tabel Apache Iceberg V2 (GA) dan tabel V3 (Pratinjau) didukung. Tabel Iceberg V1 tidak didukung. Sebelum menggunakan tabel V1 yang ada dengan katalog runtime Lakehouse, Anda harus mengupgradenya ke versi yang didukung. Untuk mengetahui informasi selengkapnya, lihat Mengupgrade tabel Iceberg V1 ke V2.
- Anda tidak dapat membuat atau mengubah tabel dengan endpoint katalog REST Apache Iceberg menggunakan pernyataan bahasa definisi data (DDL) atau bahasa pengolahan data (DML) BigQuery. Anda dapat mengubah tabel ini menggunakan BigQuery API (dengan alat command line bq atau library klien), tetapi tindakan ini berisiko membuat perubahan yang tidak kompatibel dengan mesin eksternal.
- Tabel dalam katalog runtime Lakehouse tidak mendukung
operasi penggantian nama atau
pernyataan Spark SQL
ALTER TABLE ... RENAME TO. - Tabel dalam katalog runtime Lakehouse tidak mendukung pengelompokan.
- Tabel dalam katalog runtime Lakehouse tidak mendukung nama kolom fleksibel.
Katalog runtime Lakehouse tidak mendukung tampilan database atau metastore.
Katalog runtime Lakehouse tidak mendukung tampilan Apache Iceberg.
Membuat kueri
- Performa kueri untuk tabel dalam katalog runtime Lakehouse dari mesin BigQuery mungkin lambat dibandingkan dengan mengkueri data dalam tabel BigQuery standar. Secara umum, kecepatan kueri harus setara dengan membaca data dari Cloud Storage.
- Uji coba BigQuery dari kueri yang menggunakan tabel dalam katalog runtime Lakehouse mungkin melaporkan batas bawah 0 byte data, meskipun baris ditampilkan. Hasil ini terjadi karena jumlah data yang diproses dari tabel tidak dapat ditentukan hingga kueri lengkap dijalankan. Menjalankan kueri akan menimbulkan biaya untuk pemrosesan data ini.
- Anda tidak dapat mereferensikan tabel dalam katalog runtime Lakehouse dalam kueri tabel karakter pengganti.
API dan metadata
- Anda tidak dapat menggunakan metode
tabledata.listuntuk mengambil data dari tabel dalam katalog runtime Lakehouse. Sebagai gantinya, Anda dapat menyimpan hasil kueri ke tabel BigQuery, lalu menggunakan metodetabledata.listpada tabel tersebut. - Tampilan statistik penyimpanan tabel untuk tabel dalam katalog runtime Lakehouse tidak didukung.
Kuota dan batas
- Tabel dalam katalog runtime Lakehouse di BigQuery tunduk pada kuota dan batas yang sama seperti tabel standar.
Perbedaan dengan metastore BigLake (klasik)
Perbedaan utama antara katalog runtime Lakehouse dan metastore BigLake (klasik) meliputi hal berikut:
- Katalog runtime Lakehouse mendukung integrasi langsung dengan mesin open source seperti Spark, yang membantu mengurangi redundansi saat Anda menyimpan metadata dan menjalankan tugas. Tabel dalam katalog runtime Lakehouse dapat diakses langsung dari beberapa mesin open source dan BigQuery.
- Katalog runtime Lakehouse mendukung endpoint katalog REST Apache Iceberg, sedangkan metastore BigLake (klasik) tidak.