
Lakehouse for Apache Iceberg è una piattaforma data lakehouse gestita su Google Cloud. Al centro si trova il catalogo runtime Lakehouse, un servizio di metastore completamente gestito e serverless che funge da unica fonte di verità per i tuoi dati. Centralizzando questi metadati, più motori di elaborazione, tra cui Apache Spark, Apache Flink, Apache Hive e BigQuery, possono condividere senza problemi le tabelle senza duplicare i file.
Per connettere i motori di query al metastore, configura un client utilizzando un tipo di catalogo come il catalogo REST Apache Iceberg. In questo modo viene creato un endpoint di gestione all'interno del catalogo runtime Lakehouse per gestire i metadati delle tabelle, mentre Cloud Storage viene utilizzato per archiviare i metadati e i file di dati sottostanti.
Funzionalità chiave
In quanto componente chiave di Lakehouse for Apache Iceberg, il catalogo runtime Lakehouse offre diversi vantaggi per la gestione e l'analisi dei dati, tra cui un'architettura serverless, l'interoperabilità dei motori con le API aperte, un'esperienza utente unificata e analisi, streaming e AI ad alte prestazioni quando lo utilizzi con BigQuery. Per saperne di più su questi vantaggi, vedi Che cos'è Lakehouse?
Come Lakehouse si integra con Google Cloud
Per capire come Lakehouse gestisce i tuoi dati, scopri come l' architettura di Lakehouse for Apache Iceberg si integra con i Google Cloud servizi. Apache Iceberg non archivia i dati in tabelle monolitiche. Utilizza invece un'architettura a livelli di file di metadati per organizzare i file di dati in una struttura di tabella coesa con il supporto delle transazioni ACID.
Il seguente diagramma illustra come i motori di calcolo come Managed Service for Apache Spark utilizzano il catalogo runtime Lakehouse per gestire i metadati delle tabelle per leggere e scrivere i file di dati Parquet sottostanti direttamente in Cloud Storage.
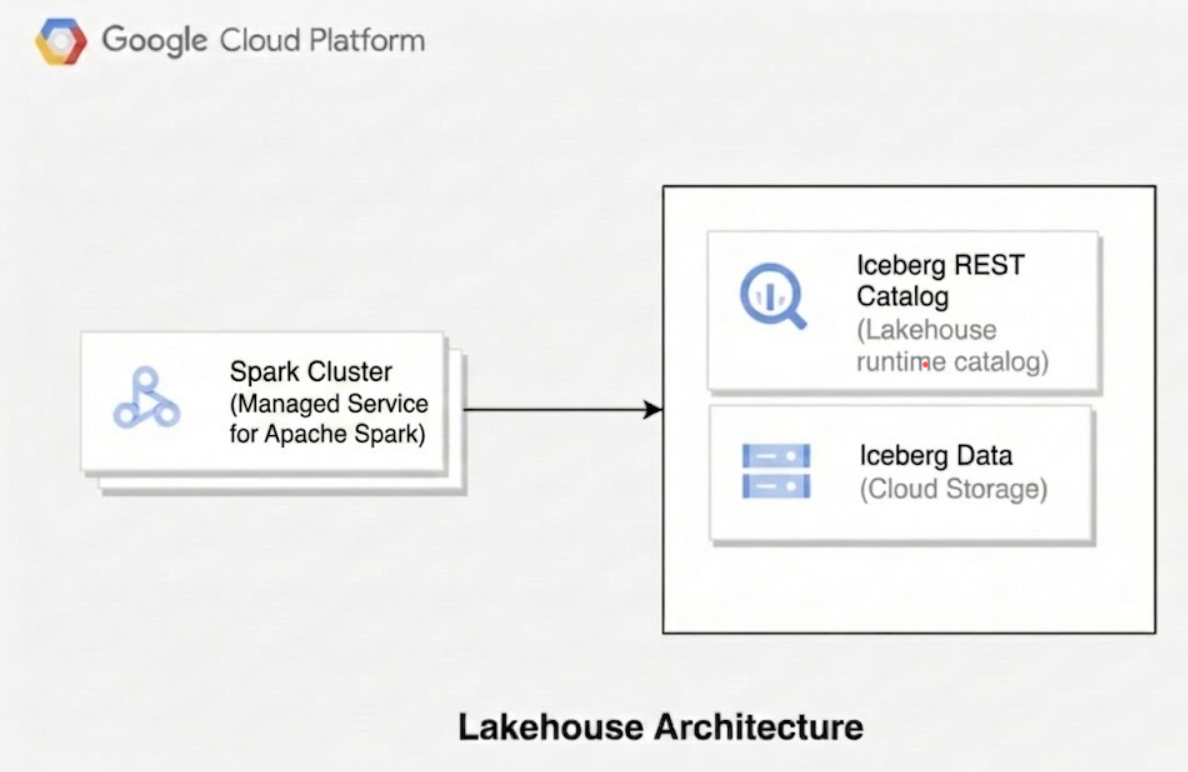
Quando utilizzi Lakehouse for Apache Iceberg, l'architettura tecnica è costituita da tre livelli distinti:
Livello del catalogo:
- Concetto principale di Iceberg: il catalogo memorizza lo stato attuale della tabella mantenendo un puntatore all'ultimo file di metadati. Questo livello facilita la conformità ACID e l'isolamento delle transazioni per garantire che le scritture simultanee non interferiscano tra loro.
- Implementazione di Lakehouse: il catalogo runtime Lakehouse funge da servizio di metastore regionale di primo livello. All'interno di questo servizio, crei singoli cataloghi per gestire la gerarchia dei dati. I motori di query client si connettono a questi cataloghi utilizzando tipi di catalogo di endpoint specifici, come l'endpoint catalogo REST Apache Iceberg. Il metastore gestisce i commit delle transazioni, la vendita delle credenziali per la delega dell'accesso allo spazio di archiviazione e la gestione dei puntatori nei cataloghi.
Livello dei metadati:
- Concetto principale di Iceberg: questo livello tiene traccia della struttura della tabella,
degli snapshot e delle posizioni dei file utilizzando una gerarchia di tre tipi di file:
- File di metadati: memorizzano lo schema della tabella, la specifica di partizionamento e un log dei puntatori degli snapshot.
- Elenchi di manifest: rappresentano un singolo snapshot della tabella raggruppando una raccolta di file manifest.
- File manifest: tengono traccia dei dati a livello di singolo file, memorizzando i percorsi dei file, le informazioni sulle partizioni e le statistiche a livello di colonna, ad esempio i conteggi delle righe e i valori minimi e massimi, che vengono utilizzati per l'ottimizzazione delle query e l'eliminazione delle partizioni.
- Implementazione di Lakehouse: all'interno di un container di catalogo,
organizzi i dati in spazi dei nomi logici (simili ai
set di dati) e tabelle. Per ogni tabella, il catalogo runtime Lakehouse genera e gestisce la gerarchia dei metadati Iceberg sottostante, a partire da un file
metadata.jsonradice che punta agli elenchi di manifest e ai file manifest. Il catalogo runtime Lakehouse salva questi file direttamente nella posizione di archiviazione del data warehouse designata.
- Concetto principale di Iceberg: questo livello tiene traccia della struttura della tabella,
degli snapshot e delle posizioni dei file utilizzando una gerarchia di tre tipi di file:
Livello dati:
- Concetto principale di Iceberg: questo componente è lo spazio di archiviazione sottostante in cui risiedono i record di dati non elaborati effettivi, in genere in formati di file aperti colonnari o basati su righe ottimizzati come Parquet, ORC o Avro.
- Implementazione di Lakehouse: quando configuri le posizioni del data warehouse di Cloud
Storage (
bl://ogs://), i file di dati fisici a cui fanno riferimento le tabelle vengono archiviati in modo sicuro all'interno dei bucket. Il catalogo runtime Lakehouse gestisce l'accesso tramite la delega dell'accesso allo spazio di archiviazione (vendita delle credenziali), vendendo token di accesso di breve durata direttamente ai motori client. In questo modo, i motori possono leggere e scrivere i file di dati in modo sicuro senza richiedere autorizzazioni IAM dirette e ampie sui bucket sottostanti.
Come Lakehouse implementa l'API del catalogo REST Apache Iceberg
Il catalogo runtime Lakehouse implementa l'API del catalogo REST Apache Iceberg open source per gestire spazi dei nomi e tabelle. Fornisce inoltre un'API di estensioni specificamente per la gestione dei cataloghi.
I motori di query client interagiscono con il metastore utilizzando queste API del catalogo REST standard. Per informazioni dettagliate sulle risorse e sugli endpoint di Google Cloud, consulta la documentazione di riferimento dell'API REST di Lakehouse.
Puoi creare, configurare e gestire queste risorse utilizzando la Google Cloud console, gcloud CLI, l'API REST o Terraform. Per saperne di più, consulta le pagine seguenti:
- Gestire le risorse del catalogo REST Iceberg
- Gestire le tabelle del catalogo REST Iceberg di Lakehouse
- Utilizzare Terraform con Lakehouse
Compatibilità e configurazione del motore di query
Per analizzare e gestire i dati nel catalogo runtime Lakehouse, puoi connettere diversi motori di query open source ed aziendali. A seconda dell'architettura esistente e dei requisiti dei workload, puoi scegliere tra diversi motori supportati e configurare l'endpoint del catalogo appropriato.
Motori supportati
Il catalogo runtime Lakehouse è compatibile con diversi motori di query, tra cui (a titolo esemplificativo) Apache Spark, Apache Flink, Apache Hive e Trino. La tabella seguente fornisce i link alla documentazione di ogni motore:
| Motore | Documentazione |
|---|---|
| Apache Spark | Guida rapida: utilizzare con Spark e l'endpoint del catalogo REST Iceberg |
| Apache Hive | Utilizzare con Spark e il catalogo Hive |
| Apache Flink | Utilizzare con Apache Flink |
| Trino | Utilizzare con Trino |
Tipi di catalogo e configurazione dell'endpoint
Quando configuri i motori client per la connessione al metastore del catalogo runtime Lakehouse, seleziona un endpoint catalogo specifico, ad esempio l'endpoint catalogo REST Apache Iceberg o l'endpoint Apache Hive. L'opzione migliore dipende dal tuo caso d'uso, come mostrato nella tabella seguente:
| Caso d'uso | Consiglio |
|---|---|
| Nuovi utenti del catalogo runtime Lakehouse che vogliono che il motore open source acceda ai dati in Cloud Storage e che hanno bisogno dell'interoperabilità con altri motori, tra cui BigQuery e AlloyDB per PostgreSQL. | Utilizza l' endpoint del catalogo REST Apache Iceberg. |
| Utenti che eseguono workload Apache Hive o Spark che dipendono dall'interfaccia Hive Metastore e vogliono un servizio di metastore completamente gestito. | Utilizza l' endpoint del catalogo Apache Hive. |
| Utenti esistenti del catalogo runtime Lakehouse che hanno tabelle correnti create con l'endpoint del catalogo Apache Iceberg personalizzato per BigQuery. | Continua a utilizzare l'endpoint del catalogo Apache Iceberg personalizzato per BigQuery, ma utilizza il catalogo REST Apache Iceberg per i nuovi flussi di lavoro. Le tabelle create con l'endpoint del catalogo Apache Iceberg personalizzato per BigQuery sono visibili con l'endpoint del catalogo REST Apache Iceberg tramite la federazione dei cataloghi BigQuery. |
Limitazioni del catalogo runtime Lakehouse
Le seguenti limitazioni generali si applicano alle tabelle nel catalogo runtime Lakehouse quando esegui query su di esse tramite BigQuery. I singoli endpoint del catalogo (come Apache Iceberg REST o Apache Hive) potrebbero avere limitazioni aggiuntive specifiche dell'endpoint.
Gestione delle tabelle
- Sono supportate le tabelle Apache Iceberg V2 (GA) e V3 (anteprima). Le tabelle Iceberg V1 non sono supportate. Prima di utilizzare le tabelle V1 esistenti con il catalogo runtime Lakehouse, devi eseguirne l'upgrade a una versione supportata. Per saperne di più, vedi Eseguire l'upgrade delle tabelle Iceberg V1 a V2.
- Non puoi creare o modificare tabelle con l'endpoint del catalogo REST Apache Iceberg utilizzando le istruzioni DDL (Data Definition Language) o DML (Data Manipulation Language) di BigQuery. Puoi modificare queste tabelle utilizzando l'API BigQuery (con lo strumento a riga di comando bq o le librerie client), ma in questo modo rischi di apportare modifiche incompatibili con il motore esterno.
- Le tabelle nel catalogo runtime Lakehouse non supportano
le operazioni di ridenominazione o l'istruzione Spark SQL
ALTER TABLE ... RENAME TO. - Le tabelle nel catalogo runtime Lakehouse non supportano il clustering.
- Le tabelle nel catalogo runtime Lakehouse non supportano i nomi di colonna flessibili.
Il catalogo runtime Lakehouse non supporta le viste di database o metastore.
Il catalogo runtime Lakehouse non supporta le viste Apache Iceberg.
Fare query
- Le prestazioni delle query per le tabelle nel catalogo runtime Lakehouse dal motore BigQuery potrebbero essere lente rispetto all'esecuzione di query sui dati nelle tabelle BigQuery standard. In generale, la velocità delle query dovrebbe essere equivalente alla lettura dei dati da Cloud Storage.
- Un'esecuzione di prova di BigQuery di una query che utilizza una tabella nel catalogo runtime Lakehouse potrebbe segnalare un limite inferiore di 0 byte di dati, anche se vengono restituite righe. Questo risultato si verifica perché la quantità di dati elaborati dalla tabella non può essere determinata finché non viene eseguita la query completa. L'esecuzione della query comporta un costo per l'elaborazione di questi dati.
- Non puoi fare riferimento a una tabella nel catalogo runtime Lakehouse in una query di tabella con funzione carattere jolly.
API e metadati
- Non puoi utilizzare il
tabledata.listmetodo per recuperare i dati dalle tabelle nel catalogo runtime Lakehouse. Puoi invece salvare i risultati delle query in una tabella BigQuery e poi utilizzare il metodotabledata.listsu quella tabella. - La visualizzazione delle statistiche di archiviazione delle tabelle per le tabelle nel catalogo runtime Lakehouse non è supportata.
Quote e limiti
- Le tabelle nel catalogo runtime Lakehouse in BigQuery sono soggette alle stesse quote e agli stessi limiti delle tabelle standard.
Differenze rispetto a BigLake Metastore (versione classica)
Le principali differenze tra il catalogo runtime Lakehouse e BigLake Metastore (versione classica) includono le seguenti:
- Il catalogo runtime Lakehouse supporta un'integrazione diretta con motori open source come Spark, il che contribuisce a ridurre la ridondanza quando archivi i metadati ed esegui i job. Le tabelle nel catalogo runtime Lakehouse sono accessibili direttamente da più motori open source e BigQuery.
- Il catalogo runtime Lakehouse supporta l'endpoint del catalogo REST Apache Iceberg, mentre BigLake Metastore (versione classica) non lo supporta.