
검색 증강 생성(RAG)을 사용하여 조직의 데이터를 기반으로 그라운딩되고 정확한 응답을 제공하는 생성형 AI 채팅 애플리케이션을 빌드합니다. 이 가이드에서는 고유한 요구사항에 맞게 맞춤설정하고 애플리케이션으로 배포할 수 있는 Cloud SQL을 사용한 생성형 AI RAG 애플리케이션 템플릿을 설명합니다.
예를 들어 이 템플릿을 구현하여 다음과 같은 비즈니스 요구사항을 해결할 수 있습니다.
| 예 | 비즈니스 요구 | 구현 |
|---|---|---|
| 고객 지원 챗봇 | 기업은 즉각적인 고객 지원을 제공해야 합니다. | Cloud Run에서 채팅 인터페이스를 호스팅합니다. Vertex AI는 임베딩을 처리하고 Cloud SQL에 벡터로 저장된 기술 문서를 기반으로 응답을 생성합니다. |
| 내부 HR 어시스턴트 | 직원은 혜택, 회사 정책, 내부 절차에 관한 정보를 찾아야 합니다. | Cloud Run에서 HR 어시스턴트를 호스팅합니다. 직원이 도구를 쿼리하면 Vertex AI는 Cloud SQL에서 관련 정책 정보를 검색하여 정확하고 소스 그라운딩된 답변을 생성합니다. |
| 법률 문서 연구원 | 법무팀은 대규모 문서 저장소에서 관련 판례 또는 계약 조항을 빠르게 찾아야 합니다. | Cloud Run에서 연구 포털을 호스팅합니다. Vertex AI는 Cloud SQL에 벡터로 저장된 법률 문서를 사용하여 관련 선례를 요약하고 계약에서 특정 언어를 식별합니다. |
| 시맨틱 제품 검색 | 이커머스 회사는 정확한 키워드 대신 자연어 설명을 사용하여 제품 검색을 용이하게 하려고 합니다. | Cloud Run에서 검색 인터페이스를 호스팅합니다. Vertex AI는 사용자 설명을 처리하여 Cloud SQL에 벡터로 저장된 제품 카탈로그에서 가장 시맨틱 관련성이 높은 제품을 반환합니다. |
아키텍처
다음 이미지는 애플리케이션의 구성요소와 연결을 보여줍니다.
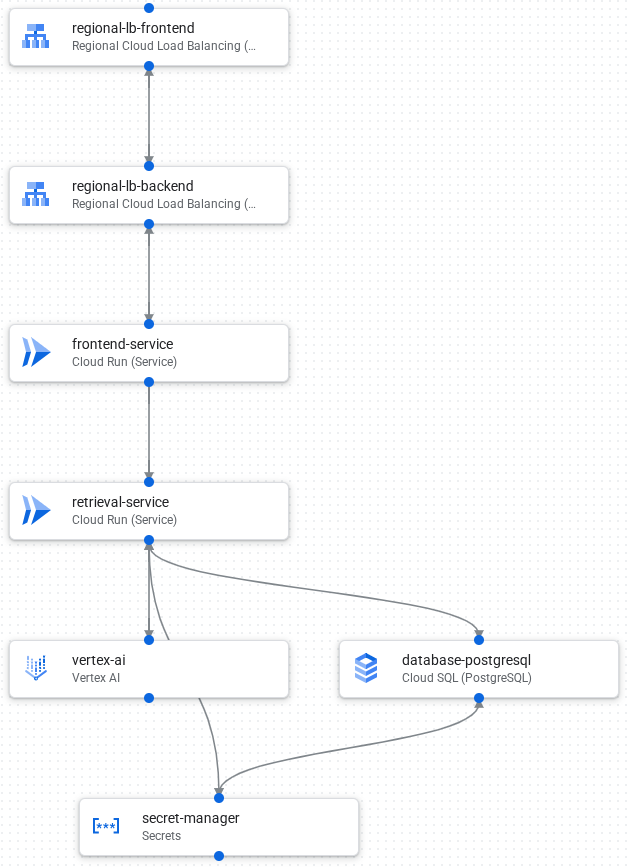
다음은 애플리케이션의 요청 처리 흐름입니다.
- Cloud SQL의 PostgreSQL 데이터베이스에 데이터를 로드합니다.
- Vertex AI는 텍스트 필드의 임베딩을 만들고 데이터베이스에 벡터로 저장합니다.
- Cloud Load Balancing 프런트엔드는 외부 요청을 수신하고 트래픽을 Cloud Load Balancing 백엔드로 분산합니다.
- Cloud Load Balancing 백엔드는 트래픽을 Cloud Run 프런트엔드 서비스로 분산합니다.
- 프런트엔드 서비스는 생성형 AI 호출을 위해 검색 서비스와 통신합니다.
- 검색 서비스는 Secret Manager를 사용하여 Vertex AI 및 Cloud SQL에 액세스하는 데 필요한 API 키와 사용자 인증 정보에 안전하게 액세스합니다.
- 검색 서비스는 요청을 임베딩으로 변환하고 Cloud SQL 데이터베이스에서 유사한 벡터를 검색합니다.
- 검색 서비스는 검색 결과를 원본 프롬프트와 함께 Vertex AI로 전송하여 응답을 생성합니다.
다음 단계
- 이 템플릿을 복제하고 맞춤설정하는 방법을 알아보려면 빠른 시작: Google 템플릿 맞춤설정 및 배포를 참고하세요.
- 애플리케이션 템플릿을 설계하여 자체 구성을 정의합니다.
- 아키텍처 프레임워크를 사용하여 일반적인 아키텍처 권장사항을 식별합니다.Google Cloud