
Crea un'applicazione di chat di AI generativa che utilizza la Retrieval-Augmented Generation (RAG) per fornire risposte basate su dati reali e accurate in base ai dati della tua organizzazione. Questa guida descrive il modello di applicazione RAG di AI generativa con Cloud SQL, che puoi personalizzare in base alle tue esigenze specifiche ed eseguire il deployment come applicazione.
Ad esempio, puoi implementare questo modello per soddisfare le seguenti esigenze aziendali:
| Esempio | Esigenza aziendale | Implementazione |
|---|---|---|
| Chatbot di assistenza clienti | Le aziende devono fornire assistenza clienti immediata. | Ospita l'interfaccia di chat su Cloud Run. Vertex AI elabora gli incorporamenti e genera risposte basate sulla documentazione tecnica archiviata come vettori in Cloud SQL. |
| Assistente HR interno | I dipendenti devono trovare informazioni su vantaggi, norme aziendali e procedure interne. | Ospita l'assistente RU su Cloud Run. Quando i dipendenti eseguono query sullo strumento, Vertex AI recupera le informazioni sulle norme pertinenti da Cloud SQL per generare risposte accurate e basate su dati reali. |
| Ricercatore di documenti legali | I team legali devono trovare rapidamente la giurisprudenza o le clausole contrattuali pertinenti in grandi repository di documenti. | Ospita il portale di ricerca su Cloud Run. Vertex AI riassume i precedenti pertinenti e identifica il linguaggio specifico nei contratti utilizzando i documenti legali archiviati come vettori in Cloud SQL. |
| Ricerca semantica dei prodotti | Le aziende di e-commerce vogliono facilitare le ricerche di prodotti utilizzando descrizioni in linguaggio naturale anziché parole chiave esatte. | Ospita l'interfaccia di ricerca su Cloud Run. Vertex AI elabora le descrizioni degli utenti per restituire i prodotti semanticamente più pertinenti dai cataloghi di prodotti archiviati come vettori in Cloud SQL. |
Architettura
L'immagine seguente mostra i componenti e le connessioni dell'applicazione:
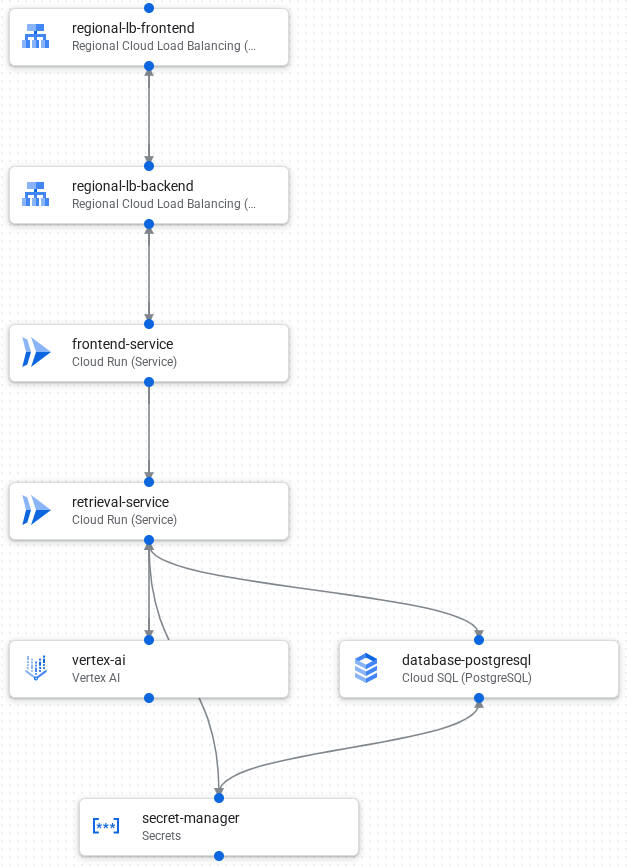
Di seguito è riportato il flusso di elaborazione delle richieste dell'applicazione:
- Carica i dati in un database PostgreSQL in Cloud SQL.
- Vertex AI crea gli incorporamenti dei campi di testo e li archivia come vettori nel database.
- Un frontend di Cloud Load Balancing riceve le richieste esterne e distribuisce il traffico al backend di Cloud Load Balancing.
- Il backend di Cloud Load Balancing distribuisce il traffico al servizio di frontend di Cloud Run.
- Il servizio di frontend comunica con un servizio di recupero per una chiamata di AI generativa.
- Il servizio di recupero utilizza Secret Manager per accedere in modo sicuro alle chiavi API e alle credenziali necessarie per accedere a Vertex AI e Cloud SQL.
- Il servizio di recupero converte la richiesta in un incorporamento e cerca vettori simili nel database Cloud SQL.
- Il servizio di recupero invia i risultati della ricerca, insieme al prompt originale, a Vertex AI per creare una risposta.
Passaggi successivi
- Per scoprire come duplicare e personalizzare questo modello, consulta la guida rapida Personalizzare ed eseguire il deployment di un modello Google.
- Definisci le tue configurazioni progettando modelli di applicazioni.
- Identifica le best practice di architettura generali con l'Google Cloud Architecture Framework.