
Bangun aplikasi chat AI generatif yang menggunakan retrieval-augmented generation (RAG) untuk memberikan respons yang berdasar dan akurat berdasarkan data organisasi Anda. Panduan ini menjelaskan template aplikasi AI generatif RAG dengan Cloud SQL, yang dapat Anda sesuaikan agar sesuai dengan kebutuhan unik Anda dan di-deploy sebagai aplikasi.
Misalnya, Anda dapat menerapkan template ini untuk memenuhi kebutuhan bisnis berikut:
| Contoh | Kebutuhan bisnis | Penerapan |
|---|---|---|
| Chatbot dukungan pelanggan | Perusahaan perlu memberikan dukungan pelanggan instan. | Menghosting antarmuka chat di Cloud Run. Vertex AI memproses embedding dan menghasilkan respons berdasarkan dokumentasi teknis yang disimpan sebagai vektor di Cloud SQL. |
| Asisten HR internal | Karyawan perlu menemukan informasi tentang manfaat, kebijakan perusahaan, dan prosedur internal. | Menghosting asisten HR di Cloud Run. Saat karyawan mengajukan kueri ke alat ini, Vertex AI akan mengambil informasi kebijakan yang relevan dari Cloud SQL untuk menghasilkan jawaban yang akurat dan di-grounding pada sumber. |
| Peneliti dokumen hukum | Tim hukum perlu menemukan yurisprudensi atau klausul kontrak yang relevan dengan cepat di seluruh repositori dokumen besar. | Menghosting portal riset di Cloud Run. Vertex AI meringkas preseden yang relevan dan mengidentifikasi bahasa tertentu dalam kontrak menggunakan dokumen hukum yang disimpan sebagai vektor di Cloud SQL. |
| Penelusuran produk semantik | Perusahaan e-commerce ingin memfasilitasi penelusuran produk menggunakan deskripsi bahasa alami, bukan kata kunci yang tepat. | Menghosting antarmuka penelusuran di Cloud Run. Vertex AI memproses deskripsi pengguna untuk menampilkan produk yang paling relevan secara semantik dari katalog produk yang disimpan sebagai vektor di Cloud SQL. |
Arsitektur
Gambar berikut menunjukkan komponen dan koneksi dalam aplikasi:
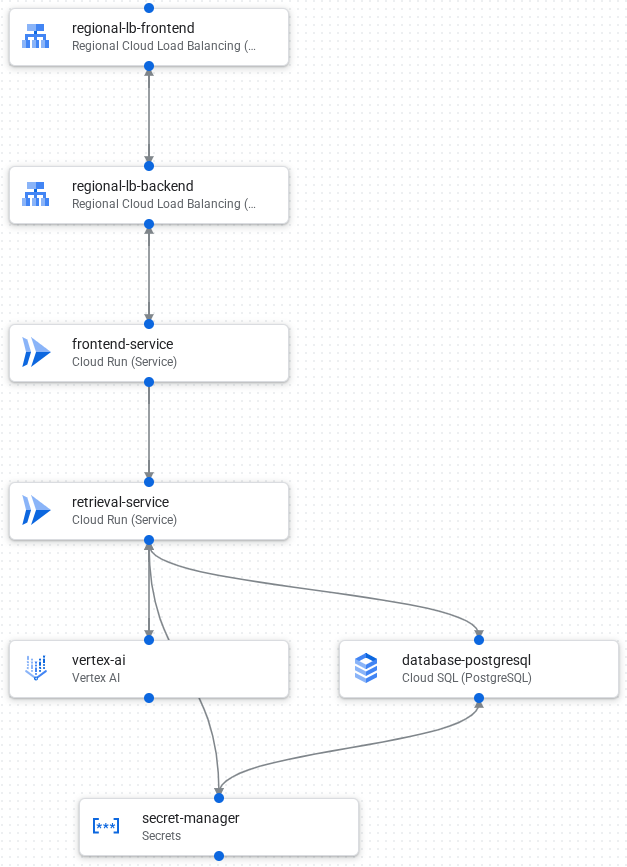
Berikut adalah alur pemrosesan permintaan aplikasi:
- Memuat data ke database PostgreSQL di Cloud SQL.
- Vertex AI membuat embedding kolom teks dan menyimpannya sebagai vektor dalam database.
- Frontend Cloud Load Balancing menerima permintaan eksternal dan mendistribusikan traffic ke backend Cloud Load Balancing.
- Backend Cloud Load Balancing mendistribusikan traffic ke layanan frontend Cloud Run.
- Layanan frontend berkomunikasi dengan layanan pengambilan untuk panggilan AI generatif.
- Layanan pengambilan menggunakan Secret Manager untuk mengakses kunci API dan kredensial yang diperlukan untuk mengakses Vertex AI dan Cloud SQL secara aman.
- Layanan pengambilan mengonversi permintaan menjadi embedding dan menelusuri vektor serupa di database Cloud SQL.
- Layanan pengambilan mengirimkan hasil dari penelusuran, beserta perintah asli, ke Vertex AI untuk membuat respons.
Langkah berikutnya
- Untuk mempelajari cara menduplikasi dan menyesuaikan template ini, lihat Panduan memulai: Menyesuaikan dan men-deploy template Google.
- Tentukan konfigurasi Anda sendiri dengan mendesain template aplikasi.
- Identifikasi praktik terbaik arsitektur umum dengan Google Cloud Framework Arsitektur.