
Entwickeln Sie eine Chat-Anwendung mit generativer KI, die Retrieval-Augmented Generation (RAG) verwendet, um fundierte und genaue Antworten auf Grundlage der Daten Ihrer Organisation zu liefern. In diesem Leitfaden wird die Anwendungsvorlage Generative AI RAG mit Cloud SQL beschrieben, die Sie an Ihre individuellen Anforderungen anpassen und als Anwendung bereitstellen können.
Sie können diese Vorlage beispielsweise verwenden, um die folgenden geschäftlichen Anforderungen zu erfüllen:
| Beispiel | Geschäftliche Anforderung | Implementierung |
|---|---|---|
| Kundensupport-Chatbot | Unternehmen müssen sofortigen Kundensupport bieten. | Hosten Sie die Chatoberfläche in Cloud Run. Vertex AI verarbeitet Einbettungen und generiert Antworten basierend auf technischer Dokumentation, die als Vektoren in Cloud SQL gespeichert ist. |
| Interner HR-Assistent | Mitarbeiter müssen Informationen zu Leistungen, Unternehmensrichtlinien und internen Verfahren finden können. | Hosten Sie den HR-Assistenten in Cloud Run. Wenn Mitarbeiter das Tool abfragen, ruft Vertex AI relevante Richtlinieninformationen aus Cloud SQL ab, um genaue, quellenbasierte Antworten zu generieren. |
| Rechercheur für Rechtsdokumente | Rechtsteams müssen schnell relevantes Fallrecht oder Vertragsbedingungen in großen Dokumentarchiven finden. | Hosten Sie das Forschungsportal in Cloud Run. Vertex AI fasst relevante Präzedenzfälle zusammen und identifiziert bestimmte Formulierungen in Verträgen anhand von Rechtsdokumenten, die als Vektoren in Cloud SQL gespeichert sind. |
| Semantische Produktsuche | E-Commerce-Unternehmen möchten Produktsuchen mit Beschreibungen in natürlicher Sprache anstelle von genauen Keywords ermöglichen. | Die Suchoberfläche in Cloud Run hosten. Vertex AI verarbeitet Nutzerbeschreibungen, um die semantisch relevantesten Produkte aus Produktkatalogen zurückzugeben, die als Vektoren in Cloud SQL gespeichert sind. |
Architektur
Das folgende Bild zeigt die Komponenten und Verbindungen in der Anwendung:
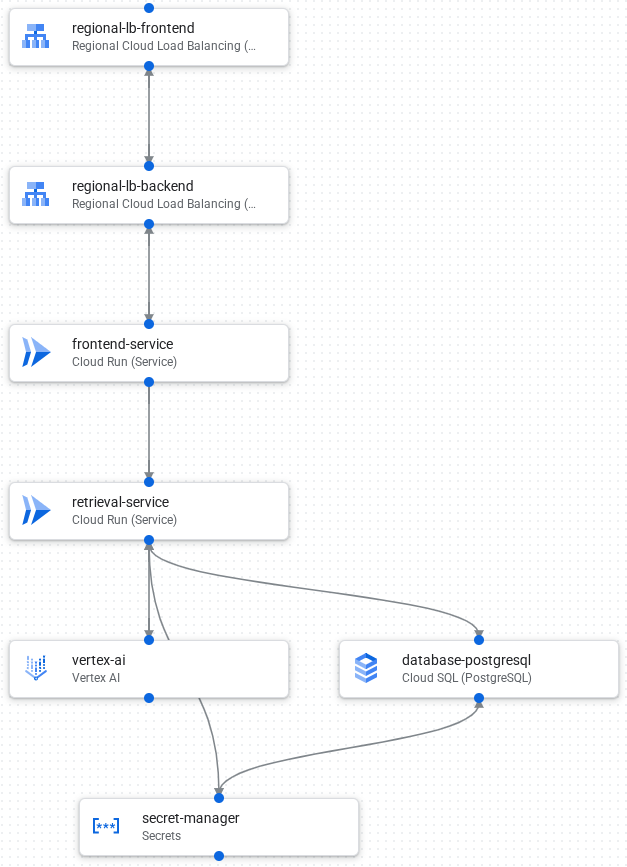
Im Folgenden wird der Ablauf der Anfrageverarbeitung der Anwendung beschrieben:
- Daten in eine PostgreSQL-Datenbank in Cloud SQL laden.
- Vertex AI erstellt Einbettungen von Textfeldern und speichert sie als Vektoren in der Datenbank.
- Ein Cloud Load Balancing-Frontend empfängt externe Anfragen und verteilt Traffic an das Cloud Load Balancing-Backend.
- Das Cloud Load Balancing-Backend verteilt den Traffic auf den Cloud Run-Frontend-Dienst.
- Der Frontend-Dienst kommuniziert mit einem Abrufdienst zwecks eines Aufrufs basierend auf generativer KI.
- Der Abrufdienst verwendet Secret Manager, um sicher auf API-Schlüssel und Anmeldedaten zuzugreifen, die für den Zugriff auf Vertex AI und Cloud SQL erforderlich sind.
- Der Abrufdienst konvertiert die Anfrage in eine Einbettung und sucht in der Cloud SQL-Datenbank nach ähnlichen Vektoren.
- Der Abrufdienst sendet Ergebnisse aus der Suche zusammen mit dem Original-Prompt an Vertex AI, um eine Antwort zu erstellen.
Nächste Schritte
- Weitere Informationen zum Bereitstellen oder Duplizieren dieser Vorlage
- Vorlagen anpassen
- Allgemeine Best Practices für die Architektur im Google Cloud Architecture Framework identifizieren