
AlloyDB Omni הוא חבילת תוכנה של מסד נתונים שאפשר להוריד, כדי לפרוס גרסה יעילה של AlloyDB ל-PostgreSQL בסביבות מחשוב שאתם מנהלים. AlloyDB Omni ושירות AlloyDB המנוהל במלואו ב- Google Cloud משתמשים באותם רכיבי ליבה. AlloyDB משתמש בשכבת אחסון מפוצלת שמותאמת לענן, ואילו AlloyDB Omni נפרס באחסון לפי בחירתכם.
הניידות של AlloyDB Omni מאפשרת להריץ אותו בסביבות רבות, כולל:
- מרכזי הנתונים הפרטיים שלכם
- כל ענן ציבורי
- המחשב הנייד
- מכונות וירטואליות מבוססות-ענן
AlloyDB Omni מציע שיפורים רבים – בנוסף ל-PostgreSQL הרגיל – שתומכים במדרגיות, בזמינות, במהימנות, בביצועים, ב-AI ובשפה טבעית. מידע נוסף זמין במאמר בנושא תוספות ל-PostgreSQL רגיל ב-AlloyDB Omni.
תרחישים לדוגמה לשימוש ב-AlloyDB Omni
AlloyDB Omni מתאים במיוחד לתרחישים הבאים:
- אתם צריכים גרסה של PostgreSQL עם יכולת התאמה לעומס וביצועים גבוהים, שאתם חייבים להריץ במקום (on-premises) בגלל דרישות רגולטוריות או דרישות של ריבונות נתונים.
- אתם צריכים מסד נתונים שממשיך לפעול גם כשהוא מנותק מהאינטרנט.
- אתם רוצים לבצע מיגרציה ממסד נתונים מדור קודם בלי להתחייב לשירות ענן מנוהל כמו AlloyDB ל-PostgreSQL.
תכונות עיקריות
- שרת מסד נתונים שתואם ל-PostgreSQL ב-100%.
- תמיכה ב-AlloyDB AI, שעוזרת לכם לבנות אפליקציות AI גנרטיביות ברמת הארגון באמצעות הנתונים התפעוליים שלכם.
- שילובים עם סביבת ה-AI, כולל Vertex AI Model Garden וכלים של AI גנרטיבי בקוד פתוח. Google Cloud
תמיכה בתכונות של טייס אוטומטי מ-AlloyDB ל-PostgreSQL ב-Google Cloud , שמאפשרת ל-AlloyDB Omni לנהל את עצמו ולכוונן את עצמו.
לדוגמה, AlloyDB Omni תומך בניהול זיכרון אוטומטי ובניקוי אוטומטי של נתונים לא עדכניים.
מנוע מבוסס-עמודות של AlloyDB Omni, ששומר נתונים רלוונטיים בפורמט עמודות בזיכרון כדי להאיץ שאילתות של ניתוח נתונים, דיווח ועומסי עבודה של עיבוד היברידי של טרנזקציות וניתוח נתונים (HTAP).
בבדיקות ביצועים, עומסי עבודה (workloads) עם טרנזקציות ב-AlloyDB Omni מהירים יותר מפי שניים, ושאילתות ניתוח נתונים מהירות יותר עד פי 100, מאשר ב-PostgreSQL רגיל.
אפשרויות פריסה של AlloyDB Omni
אפשר להתקין את AlloyDB Omni באמצעות אחת מאפשרויות הפריסה הבאות:
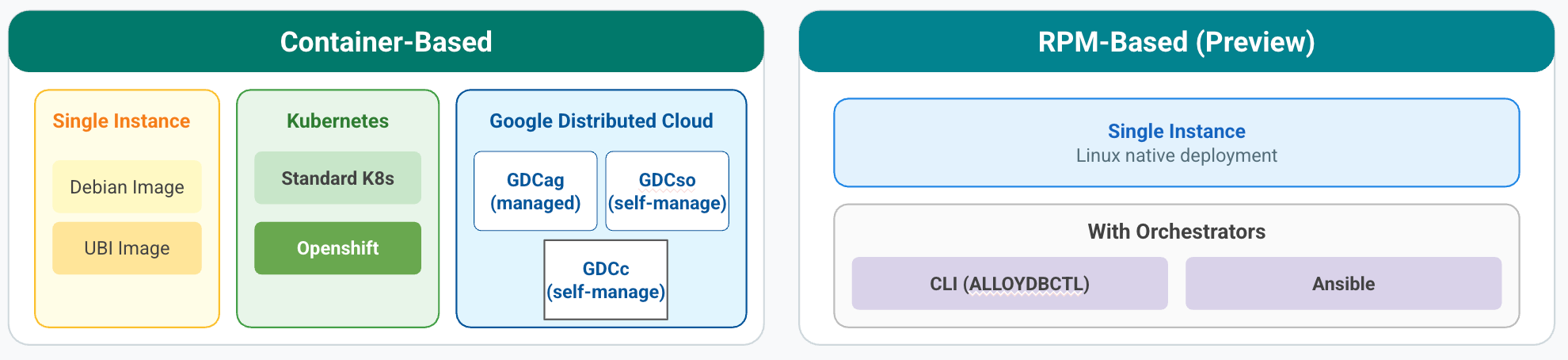
AlloyDB Omni באמצעות קונטיינרים: קונטיינר של מסד נתונים עצמאי. מריצים את AlloyDB Omni במערכת Linux עם אחסון SSD ועם זיכרון של לפחות 8GB לכל CPU.
AlloyDB Omni באמצעות כלי לתזמור קונטיינרים: חלק מקונטיינר בסביבת Kubernetes. האופרטור AlloyDB Omni Kubernetes הוא תוסף ל-Kubernetes API שמאפשר להריץ את AlloyDB Omni ברוב סביבות Kubernetes שתואמות ל-CNCF.
האופרטור AlloyDB Omni מפשט פעולות בסיסיות במסד הנתונים, ומאפשר לכם לבצע אוטומציה של פריסות של זמינות יחידה או זמינות גבוהה (HA) ופעולות ביום השני כמו גיבוי, שחזור, יתירות כשל והגדרה של תוכנית התאוששות מאסון (DR) בין אזורים.
AlloyDB Omni באמצעות RPM: חבילה עצמאית שפועלת ישירות במכונה וירטואלית או בשרת Bare Metal. AlloyDB Omni באמצעות RPM פועל כקבוצה של רכיבי תוכנה משולבים ישירות במערכת ההפעלה של המארח. הוא משתמש במערכת הקבצים הסטנדרטית של Linux לאחסון, כך שתוכלו להשתמש בתשתית האחסון הקיימת ובשיטות הניהול שלכם.
AlloyDB Omni באמצעות כלי התזמור RPM (גרסת Preview): פריסת Red Hat Package Manager (RPM) למכונות וירטואליות או לשרתי מתכת חשופה. האפשרות הזו כוללת פלטפורמת תזמור שמבצעת אוטומטית פריסה וניהול בסביבות שאינן Kubernetes. היא מרחיבה את הגמישות של הענן לבחירת התשתית שלכם, בלי לדרוש שכבות של קונטיינרים כמו Docker.
האפליקציות שלכם מתחברות למסד הנתונים של AlloyDB Omni ומתקשרות איתו, כמו שהן מתחברות לשרת מסד נתונים רגיל של PostgreSQL ומתקשרות איתו. גם בקרת הגישה של המשתמשים מבוססת על תקני PostgreSQL.
אפשר להגדיר את ההתנהגות של מסד הנתונים AlloyDB Omni באמצעות דגלים של מסד הנתונים, כולל רישום ביומן, ניקוי ושימוש במנוע עמודות. מידע נוסף מופיע במאמר אפשרויות להורדה ולהתקנה של AlloyDB Omni.
AlloyDB Omni כקונטיינר
Google מפיצה את AlloyDB Omni כקונטיינר שאפשר להריץ עם זמני ריצה של קונטיינרים כמו Docker ו-Podman. אפשר גם לפרוס קונטיינרים של AlloyDB Omni בסביבת Kubernetes עם הרבה פעולות בסיסיות אוטומטיות.
מבחינה תפעולית, קונטיינרים מציעים את היתרונות הבאים:
- ניהול שקוף של רכיבים תלויים: כל הרכיבים התלויים הנדרשים כלולים בחבילה של מאגר התגים ונבדקים על ידי Google כדי לוודא שהם תואמים באופן מלא ל-AlloyDB Omni.
- ניידות: אפשר לצפות ש-AlloyDB Omni יפעל באופן עקבי בסביבות שונות.
- בידוד אבטחה: אתם בוחרים למה יש ל-AlloyDB Omni בקונטיינר גישה במחשב המארח.
- ניהול משאבים: אתם יכולים להגדיר את כמות משאבי המחשוב שאתם רוצים שהקונטיינר של AlloyDB Omni ישתמש בהם.
- תיקון ושדרוג חלקים: כדי לתקן קונטיינר, מחליפים את התמונה הקיימת בתמונה חדשה.
AlloyDB Omni בסביבת RHEL
AlloyDB Omni מספק שתי אפשרויות פריסה לסביבת RHEL, בהתאם לדרישות האוטומציה וההתאמה שלכם.
AlloyDB Omni באמצעות RPM
אפשרות הפריסה של RPM היא התקנה עצמאית של Red Hat Package Manager (RPM) שנועדה לסביבות שבהן רוצים מסד נתונים של AlloyDB Omni שלא מבוסס על קונטיינר. האפשרות הזו תומכת ב-RHEL 9 וב-Rocky Linux 9.
- שילוב ישיר במערכת ההפעלה: פועל כקבוצה של רכיבי תוכנה משולבים ישירות במערכת ההפעלה של המארח.
- אחסון קיים: משתמש במערכת הקבצים הסטנדרטית של Linux (ext4 ו-xfs), שתומכת בתשתית אחסון קיימת ובשיטות ניהול קיימות.
- פשטות: מתאים במיוחד להגדרות של מופע יחיד שבהן נדרשת אינטגרציה עמוקה עם מערכת ההפעלה המארחת, ללא שכבות תזמור נוספות.
כלי התזמור של RPM
אפשרות הפריסה של מתזמר RPM (בשלב טרום-השקה) משתמשת באותם חבילות RPM כמו AlloyDB Omni באמצעות RPM, אבל מוסיפה פלטפורמת תזמור כדי לאפשר ניהול אוטומטי בסביבות שאינן Kubernetes.
- גמישות כמו בענן: הרחבת האוטומציה לתשתית מקומית, טיפול באתחול, במעבר לגיבוי כשל ובניהול מחזור החיים.
- מסגרות אוטומציה: משתלבות עם כלים פופולריים כמו Ansible, ומאפשרות לצוותים להשתמש במערכי מיומנויות קיימים. אפשר גם להשתמש בכלים ייעודיים של שורת הפקודה.
- תכונות Enterprise: מיועדות במיוחד לתמיכה בזמינות גבוהה (HA) ובהתאוששות מאסון (DR) באמצעות מנהל אשכולות מרכזי.
גיבוי נתונים ותוכנית התאוששות מאסון (DR)
AlloyDB Omni כולל מערכת גיבוי ושחזור רציפה שמאפשרת לכם ליצור אשכול חדש של מסד נתונים על סמך כל נקודת זמן במהלך תקופת שמירת נתונים שניתנת להתאמה. כך תוכלו לשחזר נתונים שאבדו בטעות.
בנוסף, AlloyDB Omni יכול ליצור ולשמור גיבויים מלאים של נתוני אשכול מסד הנתונים, לפי דרישה או לפי לוח זמנים קבוע. בכל שלב, אפשר לשחזר מגיבוי לאשכול מסדי נתונים של AlloyDB Omni שמכיל את כל הנתונים מאשכול מסד הנתונים המקורי בזמן שבו נוצר הגיבוי.
כשיטה נוספת לתוכנית התאוששות מאסון (DR), אתם יכולים ליצור אשכולות משניים של מסדי נתונים במרכזי נתונים נפרדים כדי להשיג שכפול חוצה מרכזי נתונים. AlloyDB Omni מעביר נתונים באופן אסינכרוני מאשכול מסד נתונים ראשי ייעודי לכל אחד מהאשכולות המשניים שלו. בכל פעם שצריך, אפשר להפוך אשכול משני של מסד נתונים לאשכול ראשי של מסד נתונים AlloyDB Omni.
רכיבים של AlloyDB Omni
AlloyDB Omni מורכב משתי קבוצות של רכיבי ארכיטקטורה: רכיבי PostgreSQL עם שיפורים של AlloyDB Omni ורכיבים ספציפיים ל-AlloyDB Omni.
בתרשים הבא מוצגים שני סוגי הרכיבים, כולל שכבת התשתית שבה הרכיבים נמצאים, ותכונות של כל רכיב.
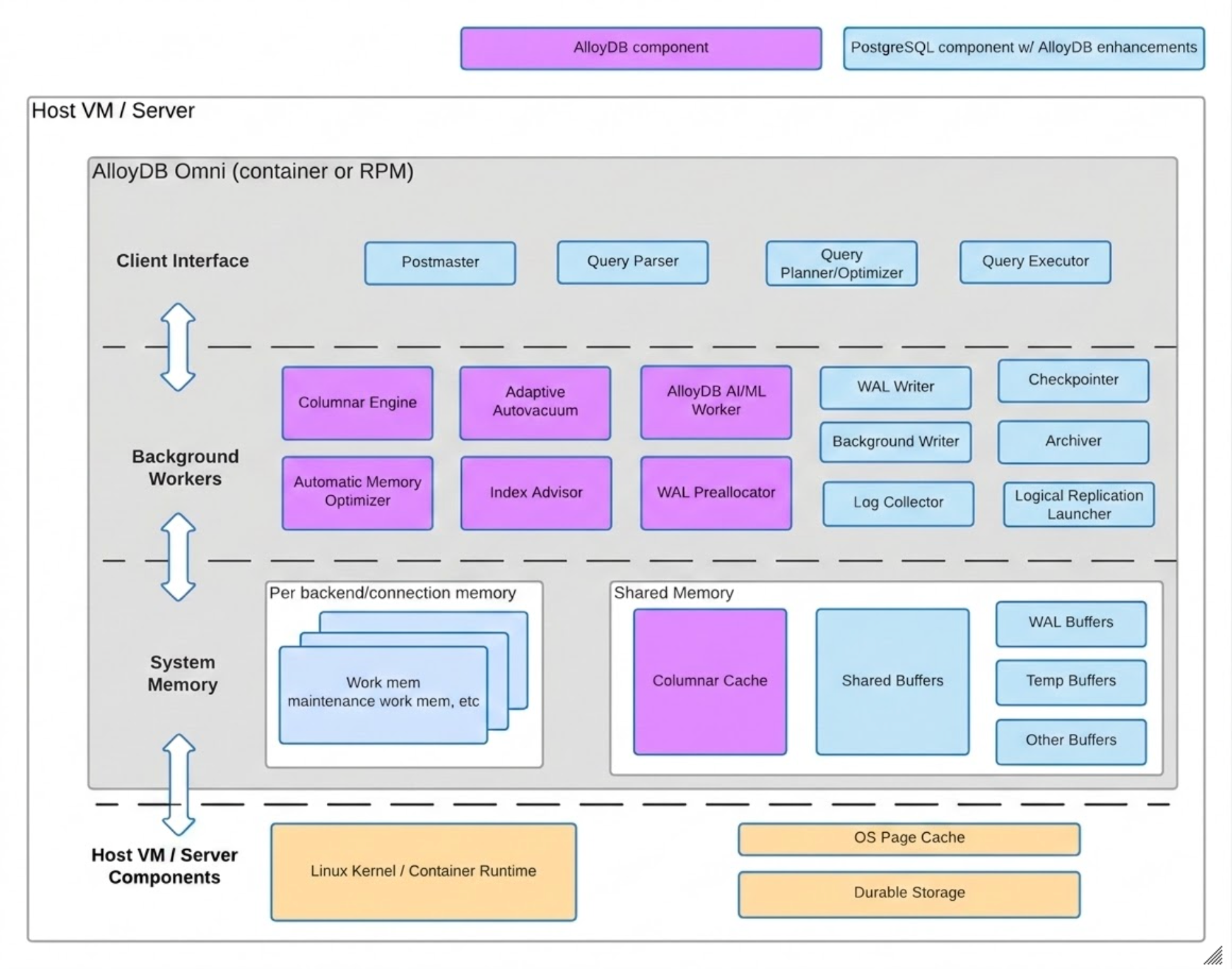
אחסון הנתונים
AlloyDB Omni מאחסן נתונים בדפים בגודל קבוע שמאוחסנים במערכת הקבצים הבסיסית. כששאילתה צריכה לגשת לנתונים, קודם כול AlloyDB Omni בודק את מאגר הנתונים הזמני. אם הדפים שמכילים את הנתונים הנדרשים לא נמצאים במאגר הזמני, AlloyDB Omni קורא את הדפים הנדרשים ממערכת הקבצים.
הגישה לנתונים ממאגר הנתונים מהירה משמעותית מקריאה ממערכת הקבצים. חשוב להגדיל את גודל מאגר הנתונים הזמני לנתונים שאפליקציה ניגשת אליהם. אפשר גם להוסיף שכבת מטמון מהירה במיוחד כדי לשפר עוד יותר את ביצועי השאילתות.
ניהול המשאבים
ב-AlloyDB Omni נעשה שימוש בניהול זיכרון דינמי אוטומטי כדי לאפשר למאגר הנתונים הזמני לגדול ולקטון באופן דינמי בתוך הגבולות שהוגדרו, בהתאם לדרישות הזיכרון של המערכת. לכן, אין צורך לשנות את הגודל של מאגר הנתונים הזמני. כשמאבחנים בעיות בביצועים, כדאי קודם לבדוק מדדים כמו שיעור הפגיעה במאגר הנתונים הזמני ושיעור הקריאה, כדי לקבוע אם האפליקציה נהנית ממאגר הנתונים הזמני. אם לא, זה מצביע על כך שמערך הנתונים של האפליקציה לא מתאים למאגר הנתונים הזמני, ואולי כדאי לשנות את הגודל למכונה גדולה יותר עם יותר זיכרון.
התהליך של אחזור, סינון, צבירה, מיון והקרנה של נתונים דורש משאבי מעבד בשרת מסד הנתונים. כדי לצמצם את כמות משאבי המעבד שנדרשים לתהליך הזה, צריך לצמצם את כמות הנתונים שמעבדים. כדאי לעקוב אחרי השימוש במעבד בשרת מסד הנתונים כדי לוודא שהשימוש במצב יציב הוא בסביבות 70%. כך נשאר מספיק מקום בשרת לעליות פתאומיות בשימוש או לשינויים בדפוסי הגישה לאורך זמן. שימוש קרוב ל-100% יוצר תקורה בגלל תזמון התהליכים והחלפת ההקשר, ועלול ליצור צווארי בקבוק בחלקים אחרים של המערכת. שימוש גבוה במעבד הוא עוד מדד חשוב שאפשר להשתמש בו כשמקבלים החלטות לגבי מפרטי המכונה.
פעולות קלט/פלט לשנייה (IOPS) הוא גורם חשוב בביצועים של אפליקציות מסד נתונים. הוא מודד כמה פעולות קלט או פלט לשנייה יכול מכשיר האחסון הבסיסי לספק למסד הנתונים. כדי להימנע מחריגה ממגבלות ה-IOPS של אחסון מסד הנתונים, צריך לצמצם את פעולות הקריאה והכתיבה לאחסון. מגדילים את כמות הנתונים שנכנסת למאגר או לשכבת המטמון.
מנוע מבוסס-עמודות
המנוע המובנה מבוסס-העמודות מאיץ את העיבוד של שאילתות ניתוח נתונים, שבדרך כלל כוללות סריקות מלאות של טבלאות, צירופים מורכבים וצבירות.
מאגר עמודות בזיכרון: מכיל נתונים של טבלאות ותצוגות חומריות של עמודות נבחרות בפורמט מבוסס-עמודות. כברירת מחדל, מאגר העמודות צורך 30% מהזיכרון הזמין. כדי לשנות את כמות הזיכרון שניתן להשתמש בה בחנות העמודות, צריך להגדיר את הפרמטר
google_columnar_engine.memory_size_in_mbב-postgresql.confשבו נעשה שימוש במופע AlloyDB Omni.כלי לתכנון שאילתות מבוסס-עמודות ומנוע הפעלה: תומך בשימוש במאגר עמודות בשאילתות.
למידע נוסף, אפשר לעיין במאמר מידע על מנוע מבוסס-העמודות של AlloyDB ל-PostgreSQL.
ניהול זיכרון אוטומטי
מנהל הזיכרון האוטומטי עוקב באופן רציף אחרי צריכת הזיכרון ומבצע אופטימיזציה שלה בכל מופע של AlloyDB Omni. כשמריצים את עומסי העבודה, המודול הזה משנה את גודל מטמון מאגר הנתונים הזמני המשותף בהתאם ללחץ הזיכרון.
כברירת מחדל, מנהל הזיכרון האוטומטי מגדיר את המגבלה העליונה ל-80% מזיכרון המערכת, ומקצה 10% מזיכרון המערכת למטמון המאגר המשותף. כדי לשנות את המגבלה העליונה של גודל מטמון המאגר המשותף, צריך להגדיר את הפרמטר shared_buffers ב-postgresql.conf שבו נעשה שימוש במופע AlloyDB Omni.
Adaptive autovacuum
התכונה 'ניתוח אוטומטי של פעולות' מנתחת פעולות על סמך עומס העבודה של מסד הנתונים, ומתאימה אוטומטית את תדירות הניתוח. ההתאמה האוטומטית הזו עוזרת למסד הנתונים לשמור על ביצועים אופטימליים, גם כשהעומס משתנה, בלי הפרעה מתהליך ה-vacuum.
כדי לקבוע את התדירות והעוצמה של פעולות הניקוי, התכונה 'ניקוי אוטומטי דינמי' מתבססת על הגורמים הבאים:
- גודל מסד הנתונים
- מספר הטופלים המתים במסד הנתונים
- גיל הנתונים במסד הנתונים
- מספר העסקאות לשנייה לעומת מהירות השאיבה המשוערת
- ניצול משאבים
AI/ML worker
ב-AlloyDB Omni, תהליך הרקע של AI/ML מספק את היכולות שנדרשות כדי להפעיל מודלים של Vertex AI ישירות ממסד הנתונים. תהליך הרקע של AI/ML פועל כתהליך שנקרא omni ml worker.
מישור הבקרה של כלי התזמור
אפשרות הפריסה של מתזמן ה-RPM משתמשת במנהל אשכול מרכזי כדי לבצע אוטומציה של פעולות ברמת האשכול, כולל אתחול ויתירות כשל.
ממשקי ניהול
אפשרות הפריסה של מתזמן ה-RPM מספקת כלי שירות של שורת פקודה (alloydbctl) ותפקידי Ansible לניהול של אשכול אחד או יותר בהיקף גדול.
אופטימיזציה של הביצועים
אפשרות הפריסה של כלי התיאום RPM כוללת תמיכה משולבת ב-PgBouncer לאיגום חיבורים וב-HAProxy לאיזון עומסים בנקודות קצה לקריאה-כתיבה ולקריאה בלבד.
המאמרים הבאים
כדי להתחיל, בוחרים באחת מאפשרויות הפריסה הבאות של AlloyDB Omni: