
כדי לשמור על פעולות רציפות של מסד הנתונים AlloyDB Omni ולצמצם את זמן ההשבתה, חשוב לוודא שההגדרה של Patroni לזמינות גבוהה אמינה ואיכותית. בדף הזה מופיע מדריך מקיף לבדיקת אשכול Patroni, שכולל תרחישי כשל שונים, עקביות שכפול ומנגנוני מעבר לגיבוי.
בדיקת ההגדרה של Patroni
מתחברים לאחד ממופעי patroni (
alloydb-patroni1, alloydb-patroni2אוalloydb-patroni3) ועוברים לתיקיית patroni של AlloyDB Omni.cd /alloydb/
בודקים את היומנים של Patroni.
docker compose logs alloydbomni-patroni
הערכים האחרונים צריכים לשקף מידע על צומת Patroni. אמור להופיע פלט שדומה לזה שמופיע בהמשך.
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lock
מתחברים לכל מופע שמריץ Linux שיש לו קישוריות לרשת למופע Patroni הראשי,
alloydb-patroni1, ומקבלים מידע על המופע. יכול להיות שתצטרכו להתקין את הכליjqעל ידי הרצת הפקודהsudo apt-get install jq -y.curl -s http://alloydb-patroni1:8008/patroni | jq .
אמור להופיע פלט דומה לזה שמוצג כאן.
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
התקשרות לנקודת הקצה של Patroni HTTP API בצומת Patroni חושפת פרטים שונים על המצב וההגדרה של מופע PostgreSQL מסוים שמנוהל על ידי Patroni, כולל מידע על מצב האשכול, ציר הזמן, מידע על WAL ובדיקות תקינות שמציינות אם הצמתים והאשכול פועלים בצורה תקינה.
בדיקת ההגדרה של HAProxy
במכונה עם דפדפן וקישוריות לרשת של צומת HAProxy, עוברים לכתובת הבאה:
http://haproxy:7000. לחלופין, אפשר להשתמש בכתובת ה-IP החיצונית של מופע HAProxy במקום בשם המארח שלו.אמור להופיע מסך שדומה לזה שמופיע בצילום המסך הבא.
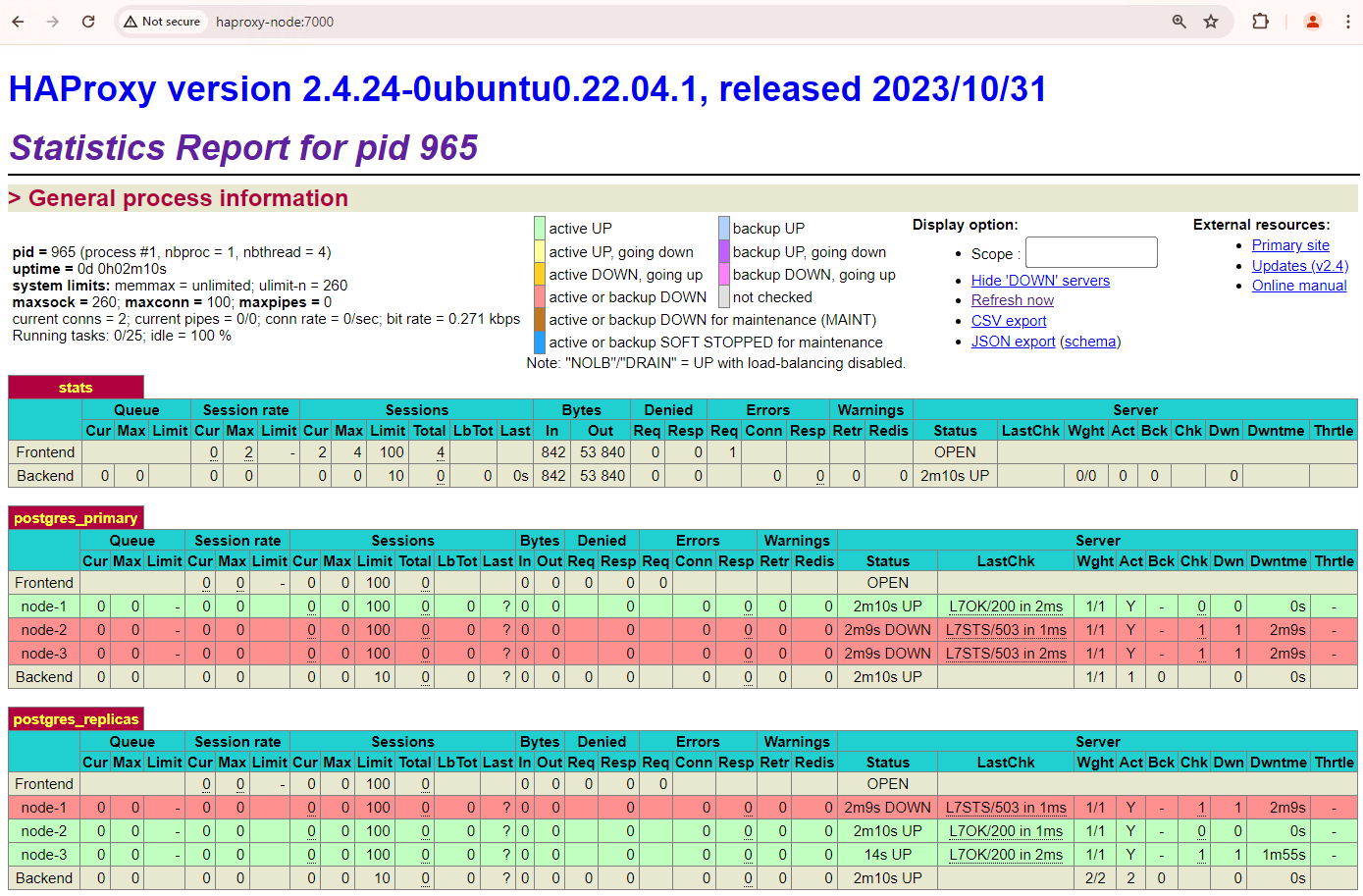
איור 1. דף הסטטוס של HAProxy שבו מוצגים סטטוס תקינות והשהיה של צמתי Patroni.
בלוח הבקרה של HAProxy אפשר לראות את סטטוס התקינות ואת זמן האחזור של צומת Patroni הראשי,
patroni1, ושל שני העותקים,patroni2ו-patroni3.אפשר להריץ שאילתות כדי לבדוק את נתוני השכפול באשכול. מלקוח כמו pgAdmin, מתחברים לשרת מסד הנתונים הראשי דרך HAProxy ומריצים את השאילתה הבאה.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;אמור להופיע תרשים דומה לתרשים הבא, שבו רואים שמתבצע סטרימינג של
patroni2ושלpatroni3מ-patroni1.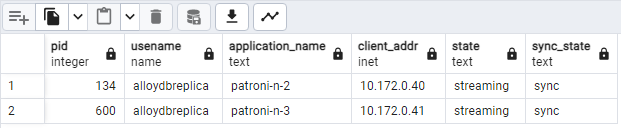
איור 2. פלט של pg_stat_replication שבו מוצג מצב השכפול של צמתי Patroni.
בדיקת מעבר אוטומטי לגיבוי (failover)
בקטע הזה, באשכול של שלושה צמתים, נדמה הפסקת חשמל בצומת הראשי על ידי עצירה של קובץ ה-Patroni המצורף שפועל. אתם יכולים להפסיק את שירות Patroni בשרת הראשי כדי לדמות הפסקת חשמל, או לאכוף כללי חומת אש מסוימים כדי להפסיק את התקשורת עם הצומת הזה.
במופע הראשי של Patroni, עוברים לתיקייה AlloyDB Omni Patroni.
cd /alloydb/
עוצרים את הקונטיינר.
docker compose down
הפלט אמור להיראות כך: כך תוכלו לוודא שהקונטיינר והרשת נעצרו.
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default Removed
מרעננים את מרכז הבקרה של HAProxy ורואים איך הגיבוי האוטומטי מתבצע.
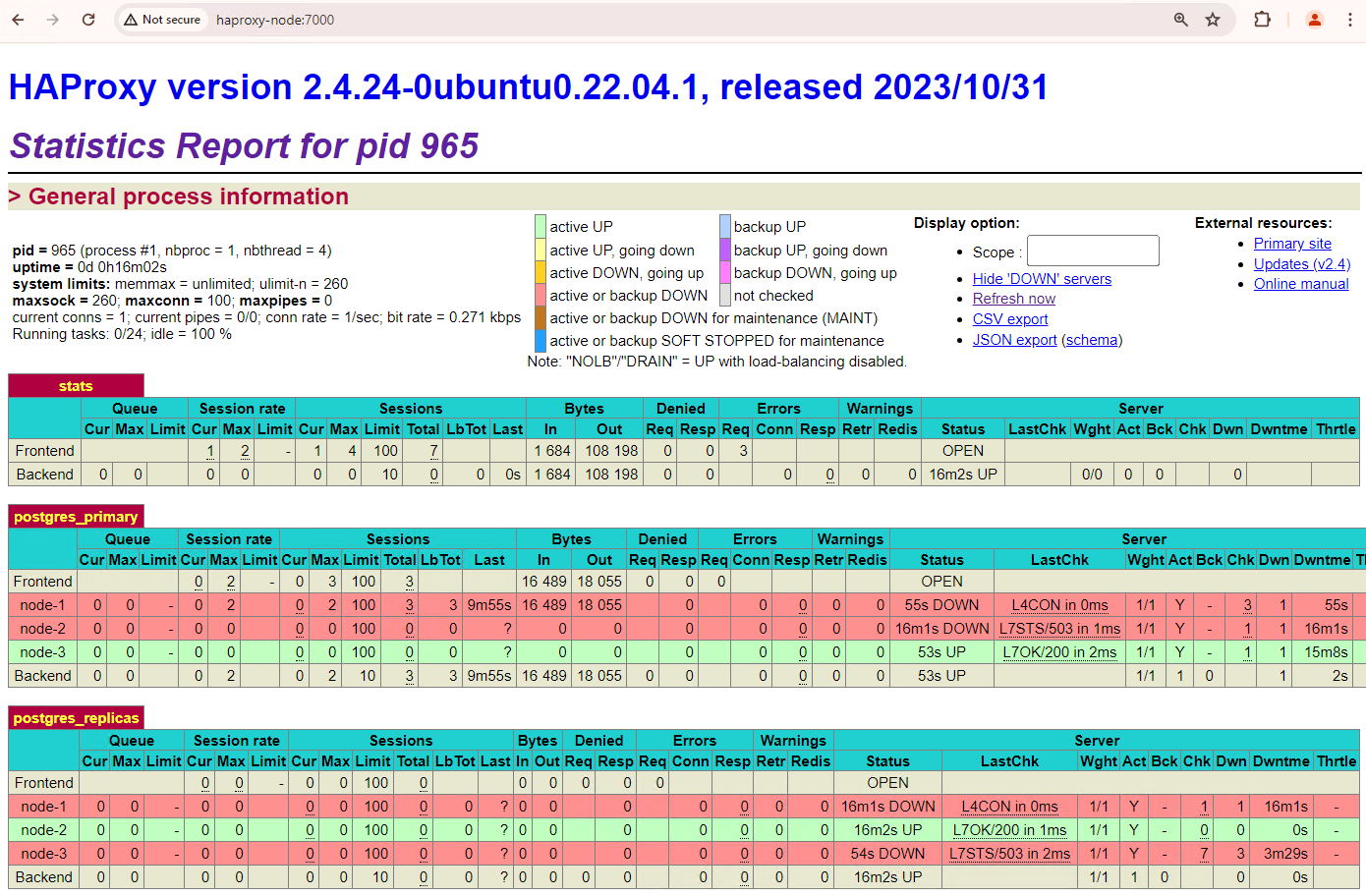
איור 3. לוח הבקרה של HAProxy שמציג את המעבר האוטומטי מהצומת הראשי לצומת ההמתנה.
מופע
patroni3הפך למופע הראשי החדש, ו-patroni2הוא העותק היחיד שנותר. הספק הראשי הקודם,patroni1, מושבת ובדיקות התקינות שלו נכשלות.Patroni מבצעת את המעבר לגיבוי ומנהלת אותו באמצעות שילוב של ניטור, קונצנזוס ותזמור אוטומטי. ברגע שהצומת הראשי לא מצליח לחדש את פרק הזמן לעיבוד שלו בתוך זמן קצוב לתפוגה מוגדר, או אם הוא מדווח על כשל, הצמתים האחרים באשכול מזהים את התנאי הזה באמצעות מערכת ההסכמה. הצמתים הנותרים מתואמים כדי לבחור את העותק המתאים ביותר לקידום כעותק הראשי החדש. אחרי שנבחר מועמד לשכפול, Patroni מקדם את הצומת הזה לדרגת ראשי על ידי החלת השינויים הנדרשים, כמו עדכון ההגדרה של PostgreSQL והפעלה מחדש של רשומות WAL שלא הופעלו. לאחר מכן, הצומת הראשי החדש מעדכן את מערכת הקונצנזוס עם הסטטוס שלו, והרפליקות האחרות מגדירות את עצמן מחדש כדי לעקוב אחרי הצומת הראשי החדש, כולל החלפת מקור השכפול ואולי גם השלמת פערים עם עסקאות חדשות. HAProxy מזהה את השרת הראשי החדש ומפנה את חיבורי הלקוח בהתאם, כדי להבטיח שיבוש מינימלי.
מלקוח כמו pgAdmin, מתחברים לשרת מסד הנתונים דרך HAProxy ובודקים את נתוני הרפליקציה באשכול אחרי יתירות כשל.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;אמור להופיע תרשים דומה לזה שבהמשך, שבו רואים שרק
patroni2מוצג בסטרימינג.
איור 4. פלט של pg_stat_replication שמציג את מצב השכפול של צמתי Patroni אחרי מעבר לגיבוי.
האשכול עם שלושת הצמתים יכול לשרוד הפסקת חשמל נוספת. אם מפסיקים את הצומת הראשי הנוכחי,
patroni3, מתבצעת העברה אוטומטית נוספת.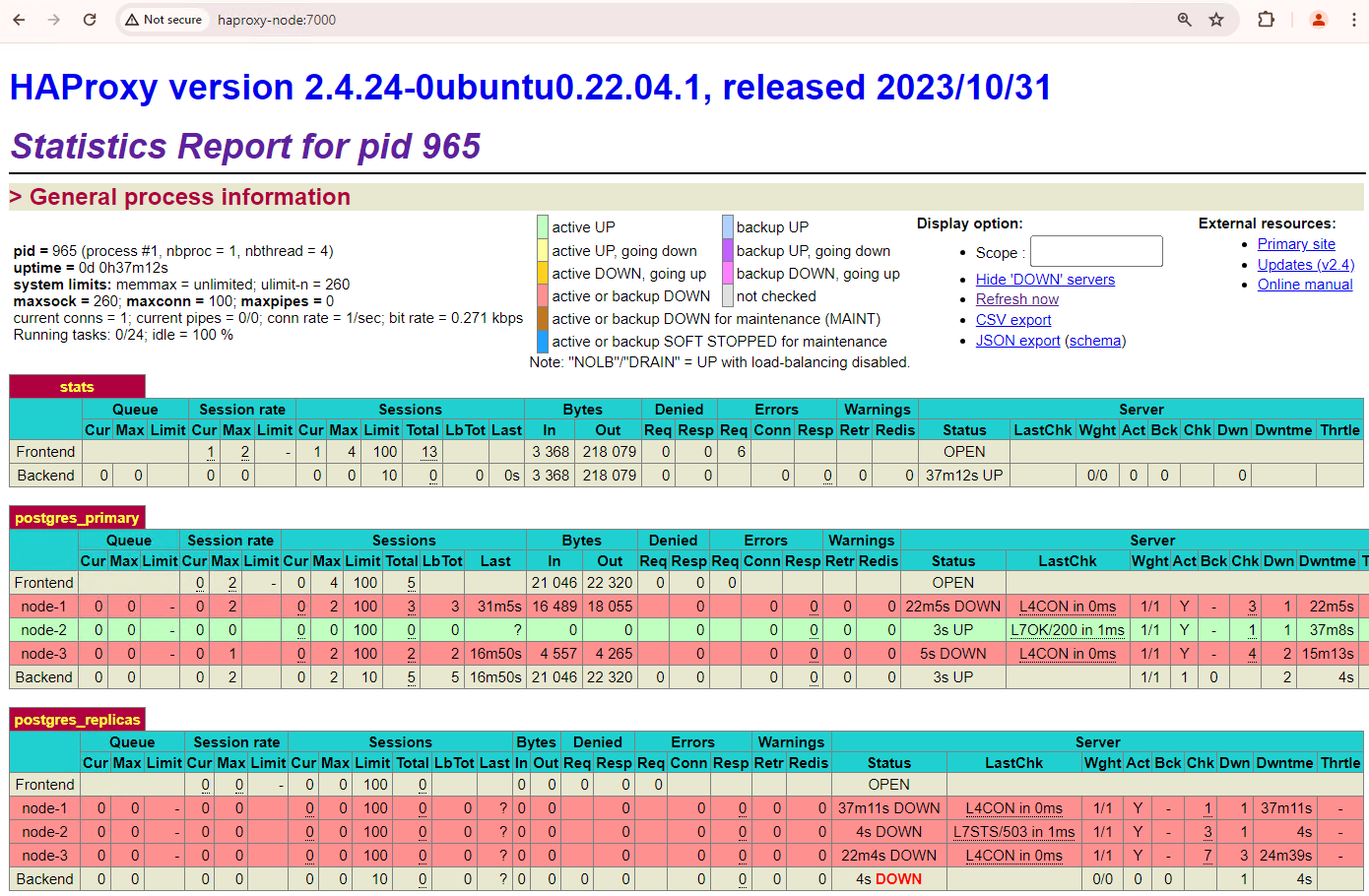
איור 5. מרכז הבקרה של HAProxy שבו מוצג המעבר לגיבוי כשל מהצומת הראשי,
patroni3, לצומת ההמתנה,patroni2.
שיקולים לגבי חזרה למצב ראשוני
חזרה למצב ראשוני היא התהליך להחזרת צומת המקור הקודם אחרי מעבר לגיבוי. בדרך כלל לא מומלץ להשתמש במעבר אוטומטי לגיבוי באשכול מסדי נתונים עם זמינות גבוהה, בגלל כמה בעיות קריטיות, כמו שחזור לא מלא, סיכון לתרחישי פיצול מוח ופיגור בשכפול.
באשכול Patroni, אם מפעילים את שני הצמתים שבהם בוצע סימול של הפסקת פעילות, הם יצטרפו מחדש לאשכול כעותקים משוכפלים במצב המתנה.
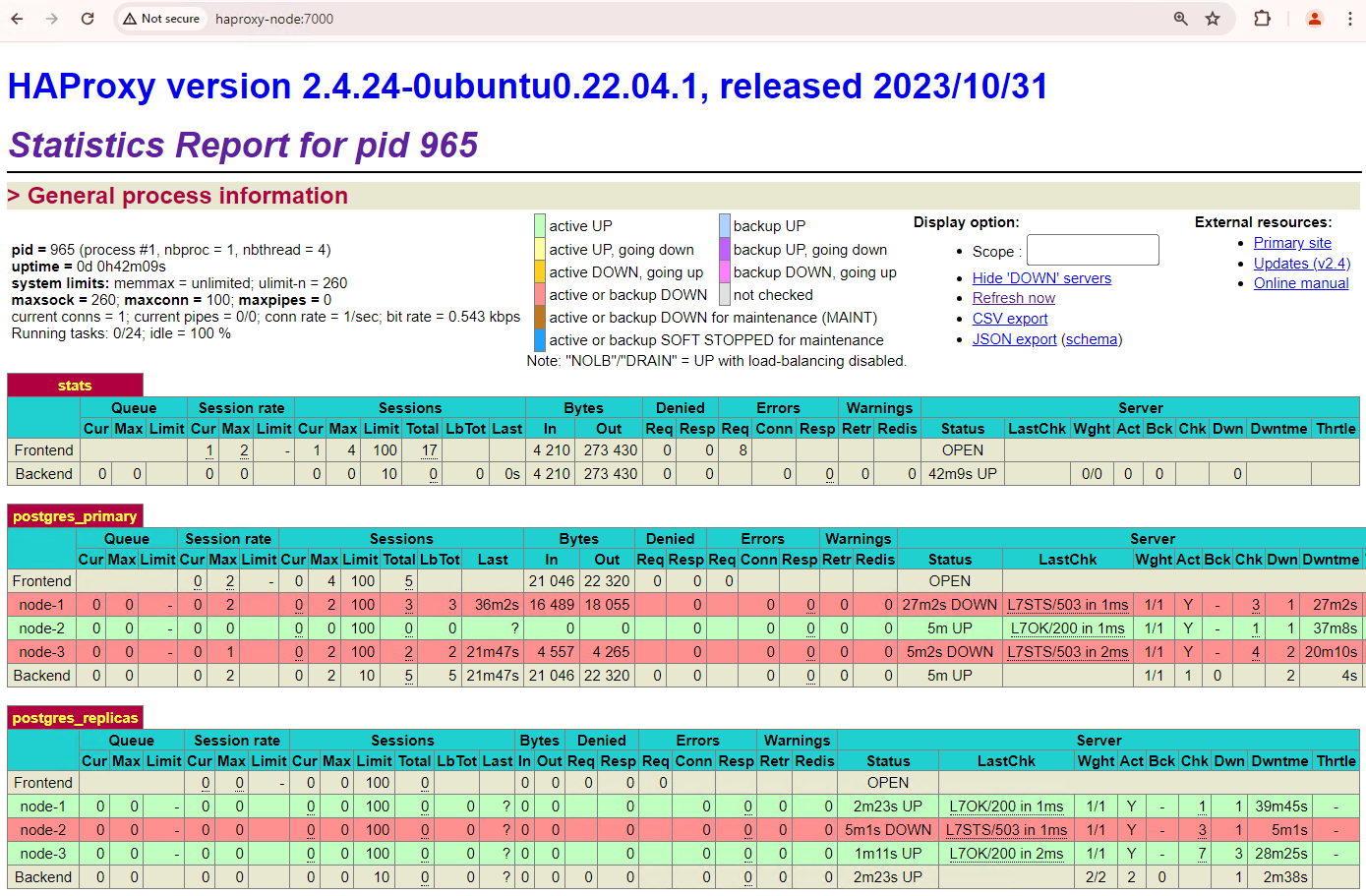
איור 6. לוח הבקרה של HAProxy שבו מוצגת השחזור של patroni1 ושל patroni3 כצמתים במצב המתנה.
עכשיו patroni1 ו-patroni3 משכפלים מהשרת הראשי הנוכחי patroni2.

איור 7. פלט של pg_stat_replication שמציג את מצב השכפול של צמתי Patroni אחרי חזרה למצב הקודם.
אם רוצים לחזור באופן ידני לשרת הראשי המקורי, אפשר לעשות זאת באמצעות ממשק שורת הפקודה patronictl. אם תבחרו במעבר ידני לגיבוי, תוכלו להבטיח תהליך שחזור אמין, עקבי ומאומת ביסודיות, ולשמור על התקינות והזמינות של מערכות מסדי הנתונים.