
תרחישים לדוגמה
ארכיטקטורת ההפניה הזו תומכת בתרחישים הבאים:
- יש לכם מסדי נתונים שיכולים לעמוד בהשבתה מסוימת ובאובדן נתונים מאז הגיבוי האחרון.
- אתם רוצים להגן על מסד הנתונים שלכם ב-AlloyDB Omni מפני שגיאות משתמש, השחתה או כשלים פיזיים ברמת מסד הנתונים (בניגוד לצילום מצב של שרת או תמונת מכונה וירטואלית).
- אתם רוצים לשחזר את מסד הנתונים במקום או מרחוק, ואולי עד לנקודת זמן ספציפית.
איך פועלת ארכיטקטורת ההפניה
ארכיטקטורת ההפניה של זמינות רגילה כוללת גיבוי ושחזור של מסדי נתונים של AlloyDB Omni, בין אם הם פועלים כמופע עצמאי בשרת מארח, כמכונה וירטואלית (התקנה של AlloyDB Omni) או באשכול Kubernetes (התקנה של AlloyDB Omni ב-Kubernetes).
Standard Availability הוא יישום בסיסי שמצמצם את הצורך בשירותים או בחומרה נוספים, אבל ככל שמסד הנתונים גדול יותר, כך גדל היעד לזמן השחזור (RTO). ככל שיש יותר נתונים לגיבוי, כך נדרש יותר זמן לשחזור ולשחזור של מסד הנתונים. אובדן הנתונים תלוי בסוג הגיבוי. אם רק קובצי הנתונים מגובים באופן תקופתי, אז כשמשחזרים, יש אובדן נתונים מאז הגיבוי האחרון.
צמצום RPO
התכונה continuous archiving של PostgreSQL מאפשרת להשיג יעד נמוך להתאוששות מאסון (RPO) ולאפשר שחזור מערכת מנקודה מסוימת בזמן באמצעות גיבויים. התהליך הזה כולל ארכיון של קובצי Write-Ahead Logging (WAL) וסטרימינג של נתוני WAL, יכול להיות למיקום אחסון מרוחק.
אם קובצי WAL מאוחסנים בארכיון רק כשהם מלאים או במרווחי זמן ספציפיים, אובדן מלא של מסד הנתונים (כולל קובצי WAL נוכחיים) מגביל את השחזור לקובץ ה-WAL האחרון שאוחסן בארכיון, מה שאומר שצריך להתחשב ביעד להתאוששות מאסון (RPO) באובדן נתונים פוטנציאלי. לעומת זאת, העברת נתוני WAL רציפה ממזערת את הסיכון לאובדן נתונים.
כשמבצעים גיבויים רציפים, אפשר לבצע שחזור מערכת מנקודה מסוימת בזמן (PITR). שחזור מערכת מנקודה מסוימת בזמן (PITR) מאפשר שחזור למצב שהיה לפני שגיאה, כמו מחיקה בטעות של טבלה או עדכונים שגויים של קבוצות. עם זאת, שיטת השחזור הזו משפיעה על יעד להתאוששות מאסון (RPO) אלא אם נעשה שימוש במסד נתונים עזר זמני.
שיטות גיבוי
אתם יכולים להגדיר גיבויים ברמת AlloyDB Omni Postgres שיאוחסנו באחסון מקומי או באחסון מרוחק. אחסון מקומי אמנם מאפשר גיבוי ושחזור מהירים יותר, אבל אחסון מרחוק בדרך כלל עמיד יותר לטיפול בכשלים כשמארח שלם או מכונה וירטואלית נכשלים.
גיבויים ב-non-Kubernetes
בפריסות שאינן Kubernetes, אפשר לתזמן גיבויים באמצעות הכלים הבאים של PostgreSQL:
- pgBackRest. למידע נוסף, ראו הגדרת pgBackRest ל-AlloyDB Omni.
- Barman. מידע נוסף זמין במאמר בנושא הגדרת Barman ל-AlloyDB Omni.
לחלופין, במסדי נתונים קטנים, אפשר לבצע גיבוי לוגי של מסד הנתונים (באמצעות pg_dump למסד נתונים יחיד או pg_dumpall לאשכול כולו). אפשר לשחזר באמצעות pg_restore.
גיבויים ב-Kubernetes באמצעות האופרטור AlloyDB Omni
ב-AlloyDB Omni שנפרס באשכול Kubernetes, אפשר להגדיר גיבויים רציפים באמצעות תוכנית גיבוי לכל אשכול מסדי נתונים. מידע נוסף זמין במאמר בנושא גיבוי ושחזור ב-Kubernetes.
אתם יכולים לאחסן גיבויים של AlloyDB Omni באופן מקומי או מרחוק ב-Cloud Storage, כולל אפשרויות שסופקו על ידי ספקי ענן. מידע נוסף מופיע באיור 1, שבו מוצגים יעדי גיבוי פוטנציאליים.
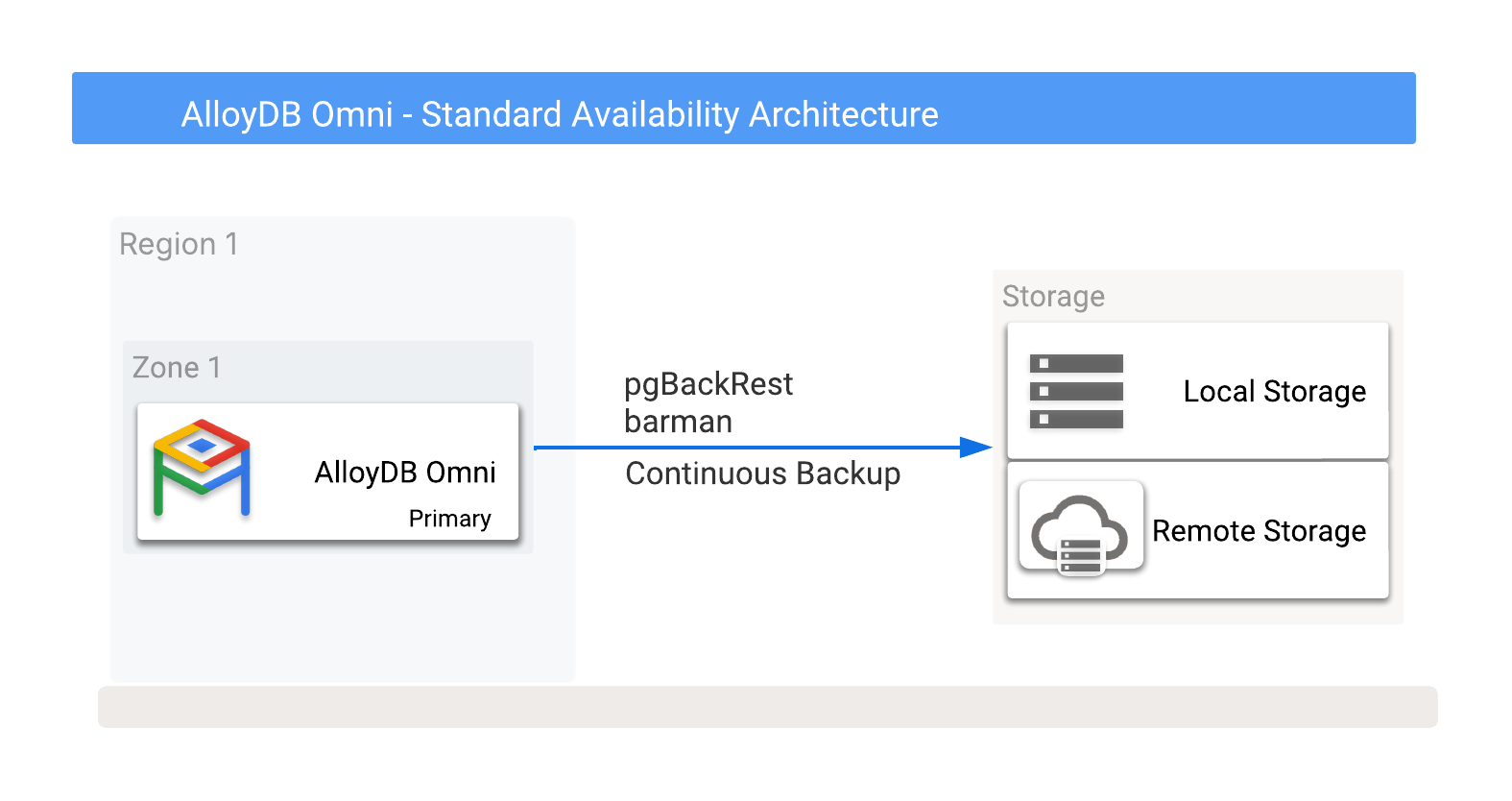
איור 1. AlloyDB Omni עם אפשרויות גיבוי.
אפשר לגבות את הנתונים לאפשרויות אחסון מקומיות או מרוחקות. גיבויים מקומיים בדרך כלל מהירים יותר כי הם מסתמכים רק על קצב העברת נתונים של קלט/פלט, בעוד שלגיבויים מרוחקים יש בדרך כלל חביון גבוה יותר ורוחב פס נמוך יותר ברשת. עם זאת, גיבויים מרוחקים מספקים הגנה אופטימלית, כולל כשלים אזוריים.
אפשר גם לפצל גיבויים מקומיים לאחסון מקומי או לאחסון שיתופי. אפשרויות האחסון המקומי מושפעות מהיעדר אפשרויות לשחזור לאחר אסון במקרה של כשל במארח מסד הנתונים, אבל אחסון שיתופי מאפשר להעביר את האחסון הזה לשרת אחר ואז להשתמש בו לשחזור. המשמעות היא שאחסון שיתופי עשוי להציע RTO מהיר יותר.
בפריסות של אחסון מקומי ואחסון משותף, יכול להיות שסוגי הגיבוי הבאים יתוזמנו או יבוצעו באופן ידני לפי דרישה:
- גיבויים מלאים: גיבויים מלאים של כל קובצי מסד הנתונים שנדרשים לשחזור הנתונים.
- גיבויים דיפרנציאליים: גיבויים של השינויים בקבצים מאז הגיבוי המלא האחרון.
- גיבויים מצטברים: גיבויים של שינויים בקבצים מאז הגיבוי האחרון מכל סוג שהוא.
שחזור מערכת מנקודה מסוימת בזמן (PITR)
גיבויים רציפים של קובצי ה-WAL (Write-Ahead Logging) של PostgreSQL תומכים בשחזור לנקודת זמן מסוימת. אם אחרי אירוע כשל, קובצי ה-WAL שלמים וניתן להשתמש בהם, אפשר להשתמש בקבצים האלה כדי לשחזר בלי אובדן נתונים.
כדי לשלוט בכתיבה של קובצי ה-WAL, אפשר להגדיר את הפרמטרים הבאים:
| פרמטר | תיאור |
|---|---|
|
ההגדרה קובעת באיזו תדירות כלי הכתיבה של WAL מבצע flush של WAL לדיסק, אלא אם הכתיבה מופעלת מוקדם יותר על ידי טרנזקציה שמבצעת commit באופן אסינכרוני. ערך ברירת המחדל הוא 200ms. הגדלת הערך הזה מפחיתה את תדירות הכתיבה, אבל עלולה להגדיל את כמות הנתונים שאובדים אם השרת קורס. |
|
ההגדרה קובעת כמה נתוני WAL יכולים להצטבר לפני שכותב ה-WAL יבצע פעולת ניקוי לדיסק. ערך ברירת המחדל הוא 1MB. אם הערך הוא אפס, נתוני ה-WAL תמיד מועברים לכונן באופן מיידי. |
|
המדיניות הזו מציינת אם הפעולה commit מחזירה תגובה למשתמש לפני שנתוני ה-WAL נכתבים בדיסק. הגדרת ברירת המחדל היא on, שמבטיחה שהטרנזקציה תהיה עמידה. במילים אחרות, הפעולה commit נכתבת בדיסק לפני שמוחזר למשתמש קוד הצלחה. אם ההגדרה היא off, יש עד פי שלושה wal_writer_delay לפני שהטרנזקציה נכתבת בדיסק. |
מעקב אחר השימוש ב-WAL
אפשר להשתמש בשיטות הבאות כדי לבדוק את השימוש ב-WAL:
| שיטת התצפית | תיאור |
|---|---|
|
בתצוגה הרגילה יש עמודות wal_write
ו-wal_sync, שבהן מאוחסנים הערכים של מספר הכתיבות ומספר הסנכרונים של WAL. אם פרמטר ההגדרה track_wal_io_timing
מופעל, גם הערכים של wal_write_time
ו-wal_sync_time מאוחסנים. צילום תמונות מצב רגיל של התצוגה הזו יכול לעזור להציג את פעילות הכתיבה והסנכרון של WAL לאורך זמן. |
pg_current_wal_lsn() |
הפונקציה הזו מחזירה את המיקום הנוכחי של מספר רצף היומן (lsn). כשמשייכים אותו לחותמת זמן ואוספים אותו כצילומי מצב לאורך זמן, אפשר לקבל את הערך של בייט לשנייה של WAL שנוצר באמצעות הפונקציה pg_wal_lsn_diff(lsn1, lsn2).
הפונקציה הזו היא מדד שימושי להבנת קצב העסקאות והביצועים של קובצי ה-WAL. |
הזרמת נתוני WAL למיקום מרוחק
כשמשתמשים ב-Barman, אפשר גם להגדיר את נתוני ה-WAL להזרמה בזמן אמת למיקום מרוחק כדי לוודא שלא יהיה אובדן נתונים או שיהיה אובדן נתונים מינימלי בשחזור. למרות ההזרמה בזמן אמת, יש סיכוי קטן לאבד עסקאות מחויבות, כי הכתיבה של ההזרמה לשרת Barman המרוחק היא אסינכרונית כברירת מחדל. עם זאת, אפשר להגדיר הזרמת WAL באמצעות מצב סינכרוני שמאחסן את ה-WAL ושולח תגובת סטטוס בחזרה למסד הנתונים של המקור. חשוב לזכור שהגישה הזו עלולה להאט את העסקאות אם הן צריכות לחכות לסיום הכתיבה הזו לפני שהן ממשיכות.
לוחות זמנים לגיבויים
ברוב הסביבות, הגיבויים מתוזמנים בדרך כלל על בסיס שבועי. לוח הזמנים הבא הוא לוח זמנים שבועי טיפוסי של גיבויים:
- יום ראשון: גיבוי מלא
- יום שני, יום שלישי: גיבוי
- יום רביעי: גיבוי דיפרנציאלי
- יום חמישי, יום שישי: גיבוי מצטבר
- שבת: גיבוי דיפרנציאלי
לפי לוח הזמנים הזה, כדי לשמור על חלון התאוששות מתגלגל של שבוע אחד, צריך מקום אחסון לגיבוי של עד שלושה גיבויים מלאים, בנוסף לגיבויים המצטברים או הדיפרנציאליים הנדרשים. הגישה הזו תומכת בשחזור במקרה של כשל שמתרחש במהלך הגיבוי המלא ביום ראשון, והשחזור של מסד הנתונים נדרש כדי להגיע ליום ראשון הקודם לפני תחילת הגיבוי.
כדי למזער את זמן ההשבתה עם פוטנציאל לזמן שחזור ארוך יותר, אפשר להפעיל מסדי נתונים נוספים במצב שחזור רציף. התהליך כולל הפעלה מחדש של גיבויים ועדכון רציף של הסביבה המשנית על ידי ארכיון והפעלה מחדש של קובצי WAL חדשים. ה-RPO בפועל, שמשקף אובדן נתונים פוטנציאלי, תלוי בתדירות העסקאות, בגודל קובץ ה-WAL ובשימוש בסטרימינג של WAL.
שחזור בסביבה שאינה Kubernetes
בפריסות שאינן Kubernetes, שחזור של מסד נתונים של AlloyDB Omni כולל עצירה של קונטיינר Docker ואז שחזור של הנתונים, או שחזור של הנתונים למיקום אחר והפעלת מופע חדש של Docker באמצעות הנתונים המשוחזרים. אחרי שהקונטיינר מופעל מחדש, אפשר לגשת למסד הנתונים עם הנתונים המשוחזרים.
מידע נוסף על אפשרויות השחזור זמין במאמרים שחזור אשכול AlloyDB Omni באמצעות pgBackRest ושחזור אשכול AlloyDB Omni באמצעות Barman.
שחזור ב-Kubernetes באמצעות Operator
כדי לשחזר מסד נתונים ב-Kubernetes, האופרטור מציע שחזור לאותו אשכול ולמרחב שמות של Kubernetes, מגיבוי עם שם או משיבוט מנקודת זמן מסוימת (PIT). כדי לשכפל מסד נתונים לאשכול Kubernetes אחר, משתמשים ב-pgBackRest. מידע נוסף זמין במאמרים בנושא גיבוי ושחזור ב-Kubernetes וסקירה כללית על שיבוט של אשכול מסדי נתונים מגיבוי של Kubernetes.
הטמעה
כשבוחרים ארכיטקטורת הפניה לזמינות, חשוב לקחת בחשבון את היתרונות, המגבלות והחלופות הבאים.
יתרונות
- קל לשימוש ולניהול, ומתאים למסדי נתונים לא קריטיים עם RTO/RPO גמישים.
- נדרשת חומרה נוספת מינימלית
- גיבויים תמיד נדרשים לתוכנית מלאה להתאוששות מאסון
- אפשר לשחזר לכל נקודה בזמן בחלון השחזור
מגבלות
- דרישות אחסון שעשויות להיות גדולות יותר מהמסד עצמו, בהתאם לדרישות השמירה.
- ההתאוששות יכולה להיות איטית, וזמן ההתאוששות (RTO) עשוי להיות ארוך יותר.
- יכולה לגרום לאובדן נתונים מסוים, בהתאם לזמינות של נתוני ה-WAL הנוכחיים אחרי כשל במסד הנתונים, מה שעשוי להשפיע לרעה על RPO.
חלופות
- כדאי לשקול את ארכיטקטורת הזמינות המשופרת או פרימיום כדי לשפר את הזמינות ואת אפשרויות ההתאוששות מאסון.
המאמרים הבאים
- סקירה כללית של תרשים עזר לארכיטקטורת הזמינות של AlloyDB Omni
- זמינות משופרת של AlloyDB Omni.
- זמינות של AlloyDB Omni Premium.
- התקנה של AlloyDB Omni ב-Kubernetes.
- הגדרת pgBackRest ל-AlloyDB Omni
- הגדרת Barman ל-AlloyDB Omni.
- גיבוי ושחזור ב-Kubernetes.
- שחזור אשכול AlloyDB Omni באמצעות pgBackRest.
- שחזור אשכול AlloyDB Omni באמצעות Barman.
- גיבוי ושחזור ב-Kubernetes.
- סקירה כללית על שיבוט של אשכול מסדי נתונים מגיבוי של Kubernetes