
Kasus penggunaan
Arsitektur referensi ketersediaan ini cocok untuk kasus penggunaan berikut:
- Aplikasi penting bisnis yang memerlukan RTO dan RPO yang lebih rendah.
- Anda ingin men-deploy replika di zona atau node lain yang memberikan ketersediaan tinggi untuk database Anda dan melindungi dari kegagalan instance, server, dan zona.
- Anda menginginkan perlindungan dari error pengguna dan kerusakan data (menggunakan cadangan).
Cara kerja arsitektur referensi
Ketersediaan yang Ditingkatkan ditambahkan ke Ketersediaan Standar dengan menambahkan instance replika baca dalam region untuk mengaktifkan ketersediaan tinggi (HA) yang mengurangi Batas Waktu Pemulihan (RTO). Pendekatan ini juga mengurangi Batas Titik Pemulihan (RPO) dengan mengizinkan perubahan transaksional streaming ke replika.
Ketersediaan tinggi di AlloyDB Omni menggunakan setidaknya dua instance database. Satu instance berfungsi sebagai database utama, yang mendukung operasi baca dan tulis. Instance yang tersisa berfungsi sebagai replika baca, yang beroperasi dalam mode hanya baca.
Berikut adalah konsep HA penting:
- Failover adalah prosedur selama pemadaman layanan yang tidak direncanakan saat instance utama gagal, atau tidak tersedia, dan replika standby diaktifkan untuk menggunakan mode utama (baca-tulis). Proses ini disebut promosi. Biasanya dalam skenario ini, saat server atau database utama kembali online, database harus dibuat ulang dan kemudian harus bertindak sebagai standby. Untuk memberikan waktu aktif yang tinggi, mekanisme diterapkan untuk membuat failover otomatis.
- A Switchover, juga dikenal sebagai pembalikan peran, adalah prosedur yang digunakan untuk mengalihkan mode antara database utama dan salah satu database standby, sehingga database utama menjadi standby dan standby menjadi utama. Switchover biasanya terjadi dengan cara yang terkontrol dan lancar, dan dapat dimulai karena berbagai alasan, misalnya, untuk mengizinkan waktu nonaktif dan patching database utama sebelumnya. Switchover yang lancar harus memungkinkan switch-back di masa mendatang tanpa perlu membuat ulang instance standby baru atau aspek lain dari konfigurasi replikasi.
Opsi ketersediaan tinggi
Dalam deployment non-Kubernetes, gunakan Patroni dan HAProxy. Untuk mengetahui informasi selengkapnya, lihat Arsitektur Ketersediaan Tinggi untuk AlloyDB Omni untuk PostgreSQL.
| Catatan: Patroni dan HAProxy adalah alat pihak ketiga non-komersial, dan kompatibel dengan AlloyDB Omni. |
|---|
Sebaiknya Anda memiliki setidaknya dua database standby sehingga kehilangan satu database tidak memengaruhi ketersediaan tinggi cluster. Dalam mode tersebut, Anda memiliki setidaknya satu pasangan HA jika terjadi failover atau selama pemeliharaan node yang direncanakan.
Untuk merencanakan ukuran dan bentuk deployment AlloyDB Omni, lihat Merencanakan penginstalan AlloyDB Omni di VM.
Load balancer
Mekanisme penting lainnya yang membantu prosedur switchover dan failover yang lebih lancar adalah keberadaan load balancer.
Untuk deployment non-Kubernetes, software HAProxy menyediakan load balancing. HAProxy menawarkan load balancing dengan mendistribusikan traffic jaringan ke beberapa server. HAProxy juga mempertahankan status health server backend yang terhubung dengannya dengan melakukan health check. Jika server gagal dalam health check, HAProxy akan berhenti mengirimkan traffic ke server tersebut hingga server tersebut lulus health check lagi.
Ketersediaan tinggi
Database replika baca yang di-deploy dalam region memberikan ketersediaan tinggi jika database utama gagal. Jika terjadi kegagalan database utama, database standby akan dipromosikan untuk menggantikan database utama dan aplikasi akan terus berjalan dengan sedikit atau tanpa pemadaman layanan.
Sebaiknya lakukan pemeriksaan rutin tahunan atau setengah tahunan dalam bentuk switchover untuk memastikan bahwa semua aplikasi yang mengandalkan database ini masih dapat terhubung dan merespons dalam jangka waktu yang sesuai.
Perlindungan tingkat zona dapat dicapai menggunakan salah satu jenis deployment dengan menempatkan salah satu replika baca standby di zona ketersediaan yang berbeda dari database utama.
Manfaat tambahan dari replika baca adalah kemampuan untuk mengalihkan operasi hanya baca ke database standby, yang dapat bertindak sebagai database pelaporan menggunakan data terbaru. Pendekatan ini mengurangi beban dan overhead pada database utama baca-tulis.
Konfigurasi pencadangan dan ketersediaan tinggi
Replika baca dapat disiapkan di beberapa zona yang memberikan ketersediaan tinggi. Meskipun memberikan RTO dan RPO yang rendah, replika baca tidak melindungi dari pemadaman layanan tertentu seperti kerusakan data logis seperti penghapusan tabel yang tidak disengaja atau update data yang salah. Oleh karena itu, pencadangan rutin harus dilakukan selain penyiapan HA. Lihat dokumentasi Arsitektur Ketersediaan Standar untuk mengetahui detailnya.
Gambar 1 menunjukkan konfigurasi HA yang direkomendasikan dengan dua database standby replika baca di dua zona ketersediaan yang berbeda.
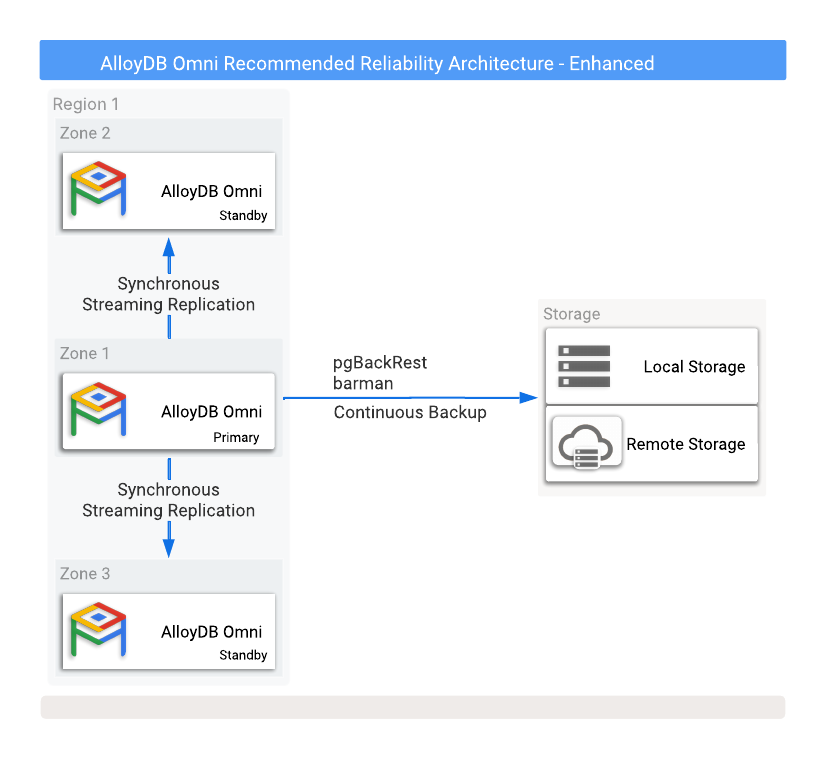
Gambar 1. AlloyDB Omni dengan opsi pencadangan dan ketersediaan tinggi.
Untuk melindungi dari kehilangan data jika instance utama gagal, konfigurasi replikasi dalam mode sinkron diperlukan. Meskipun metode ini memberikan perlindungan data yang kuat, metode ini dapat memengaruhi performa database utama karena semua commit harus ditulis ke database utama dan semua database standby yang disinkronkan. Koneksi jaringan latensi rendah antara instance database ini sangat penting untuk penyiapan ini.
Deployment HA non-Kubernetes
Deployment non-Kubernetes mandiri adalah konfigurasi manual yang memerlukan alat pihak ketiga yang lebih kompleks untuk disiapkan dan dipertahankan daripada deployment Kubernetes.
Saat Anda menggunakan deployment non-Kubernetes, ada beberapa parameter yang memengaruhi cara failover terdeteksi dan seberapa cepat failover terjadi setelah database utama tidak tersedia. Berikut adalah ringkasan singkat parameter tersebut:
Ttl: waktu maksimum yang diperlukan untuk mendapatkan kunci untuk database utama sebelum memulai failover. Default-nya adalah 30 detik.Loop_wait: jumlah waktu yang harus ditunggu sebelum memeriksa ulang. Default-nya adalah 10 detik.Retry_timeout: waktu tunggu sebelum menurunkan instance utama karena kegagalan jaringan. Default-nya adalah 10 detik.
Untuk mengetahui informasi selengkapnya, lihat Arsitektur Ketersediaan Tinggi untuk AlloyDB Omni untuk PostgreSQL.
Penerapan
Saat memilih arsitektur referensi ketersediaan, perhatikan manfaat, batasan, dan alternatif berikut.
Manfaat
- Melindungi dari kegagalan instance.
- Melindungi dari kegagalan server.
- Melindungi dari kegagalan zona.
- RTO berkurang secara drastis dari Ketersediaan Standar.
Batasan
- Tidak ada perlindungan tambahan untuk bencana regional.
- Potensi dampak performa pada database utama karena replikasi sinkron.
- Mengonfigurasi streaming WAL PostgreSQL dalam mode sinkron menawarkan nol kehilangan data (
RPO=0) selama operasi normal atau failover umum. Namun, pendekatan ini tidak melindungi dari kehilangan data dalam situasi kegagalan ganda tertentu, seperti saat semua instance standby hilang atau tidak dapat dijangkau dari database utama, dan hal ini segera diikuti dengan memulai ulang database utama.
Alternatif
- Arsitektur Ketersediaan Standar untuk opsi pencadangan dan pemulihan.
- Arsitektur Ketersediaan Premium untuk pemulihan dari bencana tingkat region, replika baca tambahan, dan jangkauan pemulihan dari bencana yang diperluas.
Langkah berikutnya
- Ringkasan arsitektur referensi ketersediaan AlloyDB Omni.
- Ketersediaan Standar AlloyDB Omni.
- Ketersediaan Premium AlloyDB Omni.
- Merencanakan penginstalan AlloyDB Omni di VM.
- Arsitektur Ketersediaan Tinggi untuk AlloyDB Omni untuk PostgreSQL.