
Questo documento fornisce una panoramica della configurazione dell'alta affidabilità (HA) per le istanze AlloyDB per PostgreSQL. Per configurare una nuova istanza per l'alta disponibilità o abilitare l'alta disponibilità su un'istanza esistente, consulta Visualizzare le impostazioni di cluster e istanze settings.
Una configurazione di alta disponibilità garantisce la continuità delle operazioni anche dopo eventi di errore. Sebbene le istanze a livello di zona possano subire tempi di inattività prolungati durante gli eventi di errore, con l'alta disponibilità i dati rimangono disponibili per le applicazioni client.
Istanze principali e secondarie
Un'istanza principale AlloyDB configurata con l'alta affidabilità include un nodo attivo e un nodo di riserva, che si trovano in zone diverse. Per l'archiviazione, AlloyDB utilizza un persister di log regionale per archiviare i log write-ahead (WAL) del database e il servizio di archiviazione regionale di AlloyDB per archiviare i blocchi di dati. L'indirizzo IP dell'istanza instrada il traffico al nodo attivo utilizzando un bilanciatore del carico.
Durante l'elaborazione delle scritture, il database AlloyDB scrive prima i WAL nel persister di log regionale sul nodo attivo e poi trasferisce in modo asincrono i log ai server di elaborazione dei log regionali di AlloyDB, che materializzano i log in blocchi di dati per l'archiviazione a lungo termine. AlloyDB pulisce quindi i log elaborati correttamente.
Il seguente diagramma mostra l'architettura di alta affidabilità.
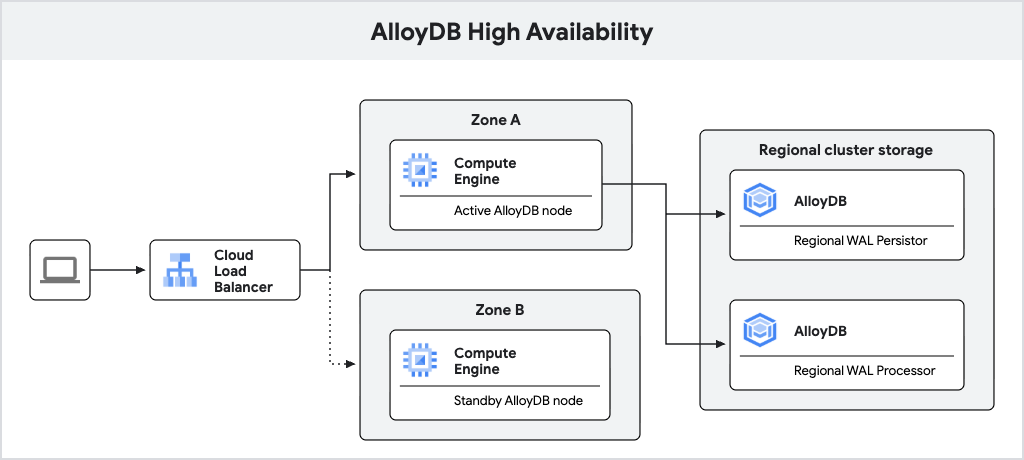
Figura 1. Architettura di alta affidabilità.
Failover
Se il nodo attivo non è più disponibile, AlloyDB esegue automaticamente il failover dell'istanza principale al nodo di riserva, che diventa il nuovo nodo attivo. Il bilanciatore del carico riconosce il nuovo nodo attivo e inizia a instradare il traffico verso di esso. Dopo un failover, il nuovo nodo attivo rimane attivo anche dopo che il nodo originale torna online. Non si verifica alcuna perdita di dati durante il failover a causa delle scritture WAL sincrone nel persister di log regionale.
Il seguente diagramma mostra il flusso di traffico dopo il failover.
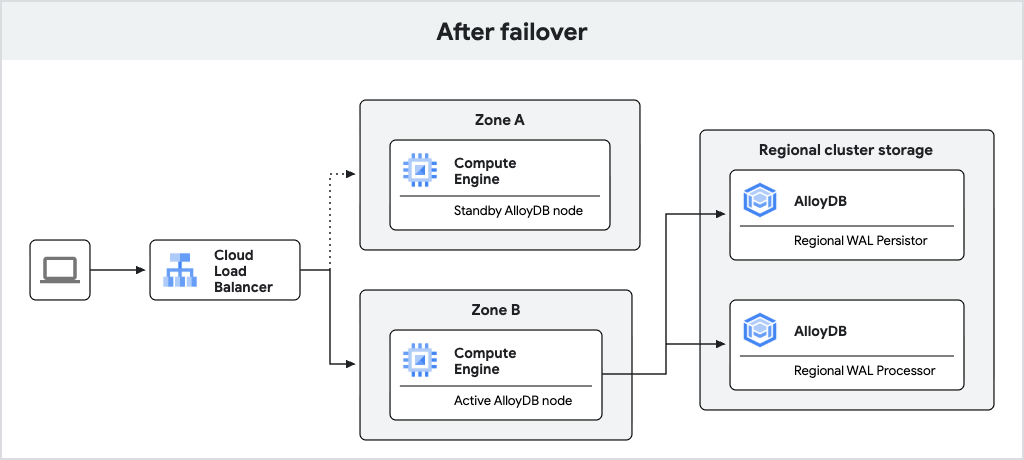
Figura 2. Flusso di traffico dopo il failover.
Un failover si verifica nella seguente sequenza di eventi:
- Il nodo o la zona attiva non funziona. Il sistema di monitoraggio dell'integrità di AlloyDB controlla periodicamente se il nodo attivo è integro. Se il sistema di monitoraggio dell'integrità non supera più controlli, avvia il failover. Il rilevamento può richiedere fino a 30 secondi.
- Il database viene avviato sul nodo di riserva e inizia ad accettare le connessioni. In genere, questa operazione richiede meno di 30 secondi.
- Il nodo di riserva viene promosso a principale. Utilizzando l'indirizzo IP statico dell'istanza, il nuovo nodo principale inizia a pubblicare i dati e le query client vanno a buon fine dopo una riconnessione.
- AlloyDB ricrea un nodo di riserva nella zona precedentemente attiva. Questo nodo di riserva è quindi pronto per i failover futuri.
Requisiti
Affinché AlloyDB consenta il failover, la configurazione deve soddisfare i seguenti requisiti:
- L'istanza principale deve essere in uno stato operativo normale (non arrestata o in manutenzione).
- La zona di riserva e il nodo di riserva devono essere integri.
Nuova architettura
Le istanze AlloyDB appena create con PostgreSQL 18 offrono un failover migliorato grazie alla funzionalità di hot standby.
Con la funzionalità di hot standby, AlloyDB esegue il nodo di riserva come replica. Durante il failover, questa replica può passare più rapidamente alla modalità di lettura/scrittura, riducendo i tempi di inattività. Inoltre, la replica consente di utilizzare cache attive, il che contribuisce a garantire prestazioni delle query coerenti dopo il failover.
Il seguente diagramma mostra l'architettura di alta affidabilità con l'hot standby incluso.
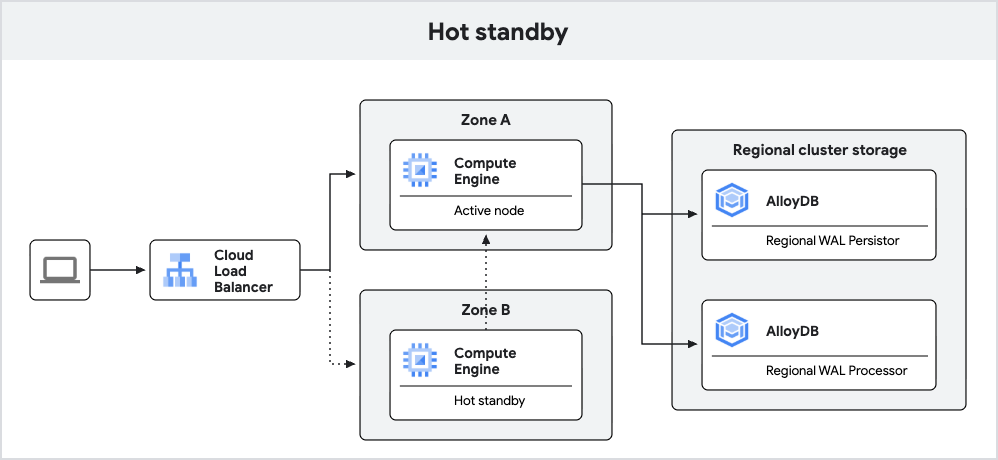
Figura 3. Hot standby.
Pool di lettura
Le istanze del pool di lettura con due o più nodi sono ad alta disponibilità. I nodi sono distribuiti uniformemente tra le zone, creando resilienza agli eventi di errore. In caso di eventi di errore, ad esempio un errore del nodo o della zona, un bilanciatore del carico regionale instrada il traffico ai nodi integri rimanenti, garantendo l'assenza di tempi di inattività per i client.
I pool di lettura rimangono online durante il failover di un'istanza principale. La replica WAL dall'istanza principale viene messa in pausa temporaneamente durante il failover e riprende automaticamente dopo il ripristino dell'istanza principale.
Passaggi successivi
- Eseguire manualmente il failover di un'istanza principale o secondaria.
- Testare l'alta affidabilità di un'istanza principale.
- Ridurre i costi utilizzando le istanze di base.