
En este documento, se proporciona una descripción general de la configuración de alta disponibilidad (HA) para las instancias de AlloyDB para PostgreSQL. Si quieres configurar una instancia nueva para HA o habilitar HA en una instancia existente, consulta Cómo ver la configuración del clúster y la instancia.
Una configuración de HA garantiza la continuidad de las operaciones incluso después de eventos de falla. Si bien las instancias zonales pueden experimentar un tiempo de inactividad prolongado durante los eventos de falla, con la HA, tus datos siguen estando disponibles para las aplicaciones cliente.
Instancias principales y secundarias
Una instancia principal de AlloyDB configurada con alta disponibilidad incluye un nodo activo y un nodo en espera, que se encuentran en diferentes zonas. Para el almacenamiento, AlloyDB usa un persistidor de registros regional para almacenar los registros de escritura anticipada (WAL) de la base de datos y el servicio de almacenamiento regional de AlloyDB para almacenar bloques de datos. La dirección IP de la instancia dirige el tráfico al nodo activo a través de un balanceador de cargas.
Cuando se procesan escrituras, la base de datos de AlloyDB primero escribe el WAL en su persistencia de registros regional en el nodo activo y, luego, transfiere los registros de forma asíncrona a los servidores de procesamiento de registros regionales de AlloyDB, que materializan los registros en bloques de datos para el almacenamiento a largo plazo. Luego, AlloyDB limpia los registros que se procesaron correctamente.
En el siguiente diagrama, se muestra la arquitectura de alta disponibilidad.
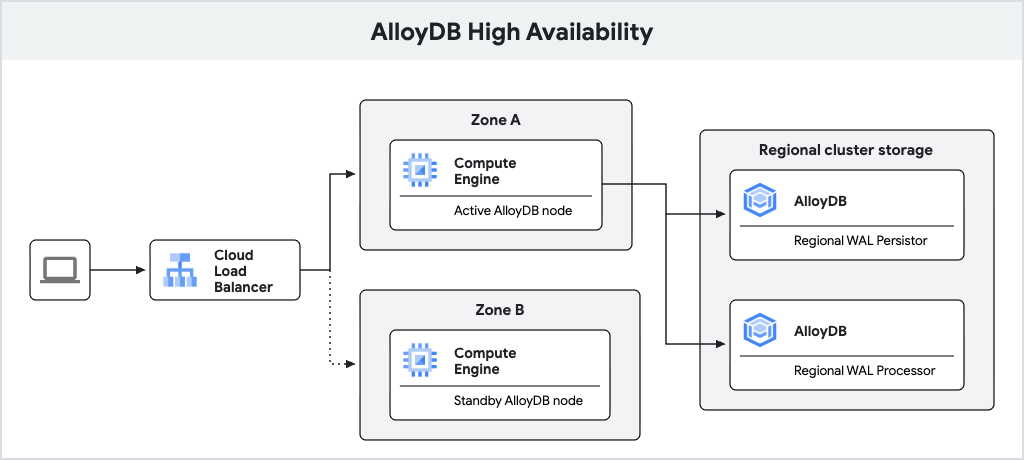
Figura 1. Arquitectura de alta disponibilidad
Conmutación por error
Si el nodo activo deja de estar disponible, AlloyDB realiza automáticamente la conmutación por error de la instancia principal a su nodo en espera, que se convierte en el nuevo nodo activo. El balanceador de cargas reconoce el nuevo nodo activo y comienza a enrutar el tráfico hacia él. Después de una conmutación por error, el nuevo nodo activo permanece activo incluso después de que el nodo original vuelva a estar en línea. No se produce pérdida de datos durante la conmutación por error debido a las escrituras síncronas del WAL en el persistidor de registros regional.
En el siguiente diagrama, se muestra el flujo de tráfico después de la conmutación por error.
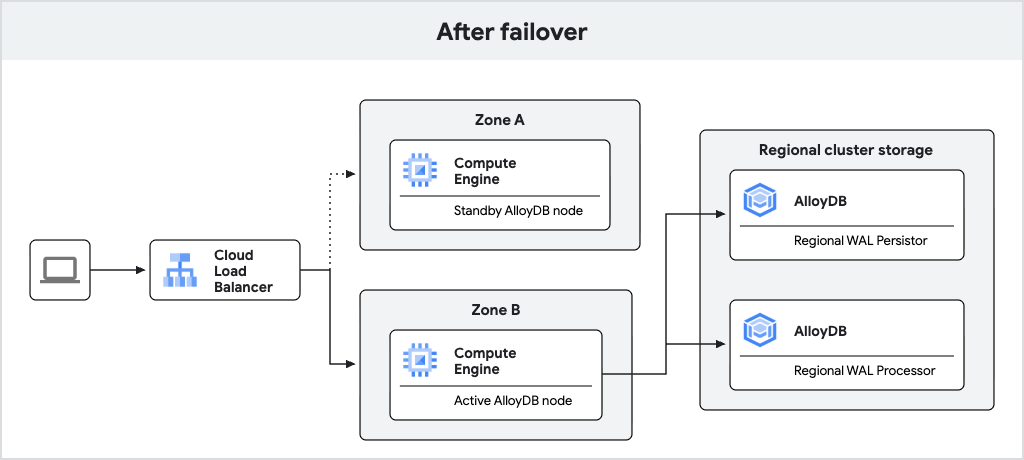
Fig. 2. Flujo de tráfico después de la conmutación por error.
La conmutación por error se produce en la siguiente secuencia de eventos:
- Falla el nodo o la zona activos. El sistema de supervisión del estado de AlloyDB verifica periódicamente si el nodo activo está en buen estado. Si el sistema de supervisión del estado falla en varias verificaciones, inicia la conmutación por error. Esta detección puede tardar hasta 30 segundos.
- La base de datos se inicia en el nodo en espera y comienza a aceptar conexiones. Este proceso suele tardar menos de 30 segundos.
- El nodo en espera cambia a principal. Con la dirección IP estática de la instancia, el nuevo nodo principal comienza a publicar datos, y las consultas del cliente se realizan correctamente después de una reconexión.
- AlloyDB recrea un nodo en espera en la zona que estaba activa anteriormente. Luego, este nodo en espera está listo para futuras conmutaciones por error.
Requisitos
Para que AlloyDB permita la conmutación por error, la configuración debe cumplir con estos requisitos:
- La instancia principal debe estar en un estado operativo normal (no detenido ni en mantenimiento).
- Tanto la zona de espera como el nodo de espera deben estar en buen estado.
Nueva arquitectura
Las instancias de AlloyDB creadas recientemente con PostgreSQL 18 proporcionan una conmutación por error mejorada con la función de espera activa.
Con la función de espera activa, AlloyDB ejecuta el nodo en espera como una réplica. Durante la conmutación por error, esta réplica puede pasar a un modo de lectura y escritura más rápido, lo que reduce el tiempo de inactividad. Además, la replicación habilita las cachés activas, lo que ayuda a garantizar un rendimiento de las consultas coherente después de la conmutación por error.
En el siguiente diagrama, se muestra la arquitectura de alta disponibilidad con el modo de espera activo incluido.
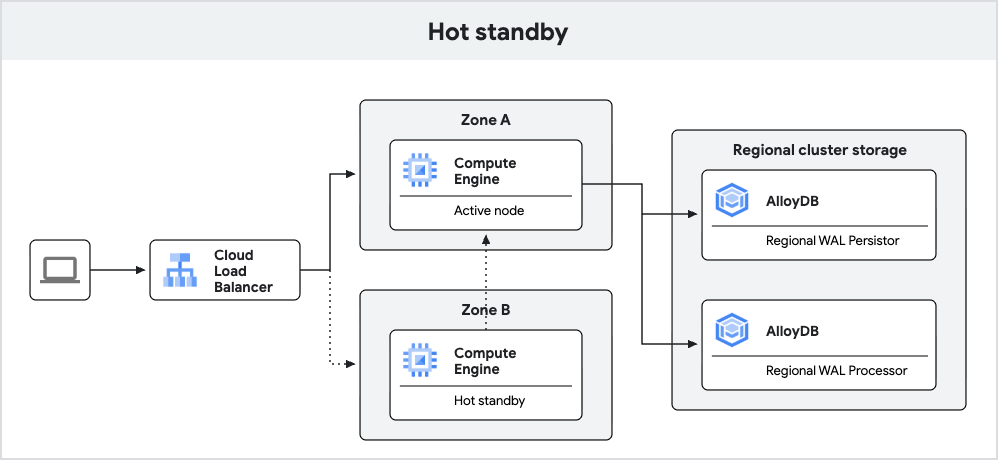
Fig. 3. Espera activa.
Grupos de lectura
Las instancias de grupo de lectura con dos o más nodos tienen alta disponibilidad. Los nodos se distribuyen de manera uniforme entre las zonas, lo que genera resiliencia ante eventos de falla. En caso de eventos de falla, como una falla de nodo o de zona, un balanceador de cargas regional dirige el tráfico a los nodos restantes en buen estado, lo que garantiza que no haya tiempo de inactividad para tus clientes.
Los grupos de lectura permanecen en línea durante una conmutación por error de la instancia principal. La replicación de WAL desde la instancia principal se pausa temporalmente durante la conmutación por error y se reanuda automáticamente después de que se recupera la instancia principal.
¿Qué sigue?
- Conmutar por error una instancia principal o secundaria de forma manual
- Prueba una instancia principal para alta disponibilidad.
- Reduce los costos con instancias básicas.