
Dieses Dokument bietet einen Überblick über die Hochverfügbarkeitskonfiguration (HA) für AlloyDB for PostgreSQL-Instanzen. Informationen zum Konfigurieren einer neuen Instanz mit Hochverfügbarkeit oder zum Aktivieren der Hochverfügbarkeit für eine vorhandene Instanz finden Sie unter Cluster- und Instanzeinstellungen ansehen.
Eine HA-Konfiguration sorgt dafür, dass der Betrieb auch nach Ausfallereignissen fortgesetzt wird. Bei zonalen Instanzen kann es bei Ausfällen zu längeren Ausfallzeiten kommen. Mit Hochverfügbarkeit bleiben Ihre Daten jedoch für Clientanwendungen verfügbar.
Primäre und sekundäre Instanzen
Eine primäre AlloyDB-Instanz, die für Hochverfügbarkeit konfiguriert ist, enthält einen aktiven Knoten und einen Standby-Knoten, die sich in verschiedenen Zonen befinden. Für die Speicherung verwendet AlloyDB einen regionalen Log-Persistor zum Speichern von Write-Ahead-Logs (WAL) der Datenbank und den regionalen Speicherdienst von AlloyDB zum Speichern von Datenblöcken. Die IP-Adresse der Instanz leitet Traffic über einen Load-Balancer an den aktiven Knoten weiter.
Bei der Verarbeitung von Schreibvorgängen schreibt die AlloyDB-Datenbank zuerst WAL in den regionalen Log-Persistor auf dem aktiven Knoten und überträgt die Logs dann asynchron an die regionalen Log-Verarbeitungsserver von AlloyDB, die die Logs in Datenblöcke für die langfristige Speicherung umwandeln. AlloyDB bereinigt dann die Logs, die erfolgreich verarbeitet wurden.
Das folgende Diagramm zeigt die Architektur für hohe Verfügbarkeit.
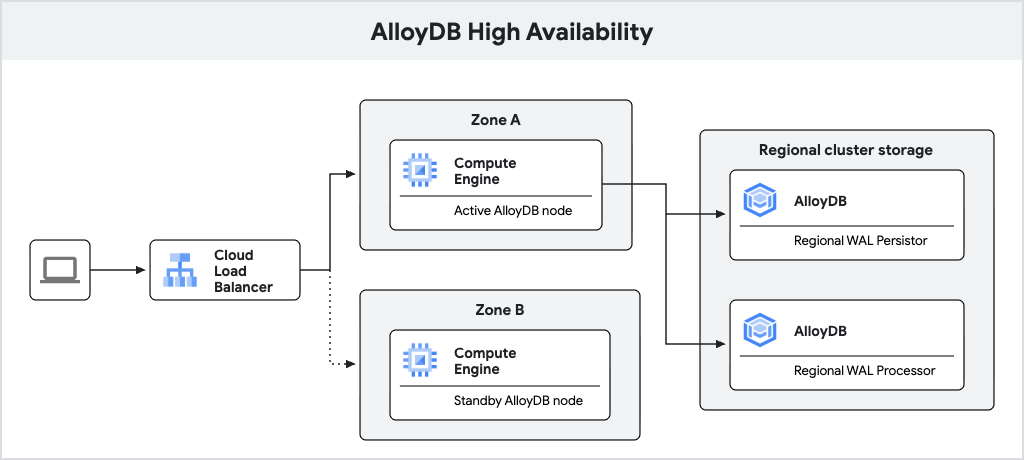
Abbildung 1: Hochverfügbarkeitsarchitektur
Failover
Wenn der aktive Knoten nicht mehr verfügbar ist, führt AlloyDB automatisch ein Failover der primären Instanz auf den Standby-Knoten durch, der zum neuen aktiven Knoten wird. Der Load-Balancer erkennt den neuen aktiven Knoten und beginnt, Traffic an ihn weiterzuleiten. Nach einem Failover bleibt der neue aktive Knoten aktiv, auch wenn der ursprüngliche Knoten wieder online ist. Beim Failover kommt es nicht zu Datenverlusten, da WAL-Schreibvorgänge synchron in den regionalen Log-Persistor erfolgen.
Das folgende Diagramm zeigt den Trafficfluss nach dem Failover.
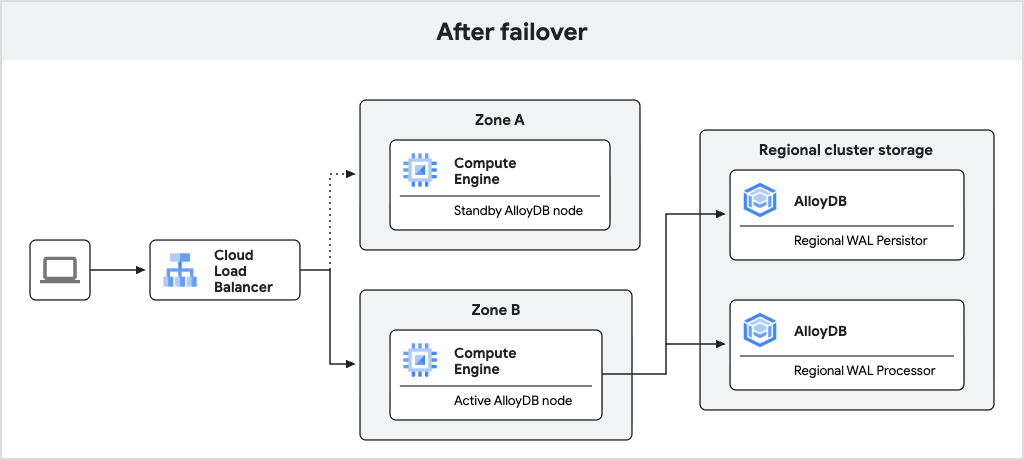
Abbildung 2 Datenverkehr nach dem Failover.
Ein Failover tritt in der folgenden Ereignisabfolge auf:
- Der aktive Knoten oder die aktive Zone schlägt fehl. Das AlloyDB-System zur Zustandsüberwachung prüft regelmäßig, ob der aktive Knoten fehlerfrei funktioniert. Wenn das System zur Überwachung des Zustands mehrere Prüfungen nicht besteht, wird ein Failover ausgelöst. Die Erkennung kann bis zu 30 Sekunden dauern.
- Die Datenbank wird auf dem Standby-Knoten gestartet und beginnt, Verbindungen anzunehmen. Das dauert in der Regel weniger als 30 Sekunden.
- Der Stand-by-Knoten wird zum primären Knoten hochgestuft. Über die statische IP-Adresse der Instanz beginnt der neue primäre Knoten mit der Bereitstellung von Daten und Clientanfragen werden nach einer erneuten Verbindung erfolgreich ausgeführt.
- AlloyDB erstellt einen Stand-by-Knoten in der zuvor aktiven Zone neu. Dieser Stand-by-Knoten ist dann für zukünftige Failover bereit.
Voraussetzungen
Damit AlloyDB ein Failover zulässt, muss die Konfiguration die folgenden Anforderungen erfüllen:
- Die primäre Instanz muss in einem normalen Betriebszustand sein, d. h. sie darf nicht angehalten werden oder gewartet werden.
- Die Standby-Zone und der Standby-Knoten müssen beide fehlerfrei sein.
Neue Architektur
Neu erstellte AlloyDB-Instanzen mit PostgreSQL 18 bieten ein verbessertes Failover mit der Hot Standby-Funktion.
Mit der Hot-Standby-Funktion wird der Stand-by-Knoten in AlloyDB als Replikat ausgeführt. Bei einem Failover kann dieses Replikat schneller in den Lese-/Schreibmodus wechseln, wodurch die Ausfallzeit verkürzt wird. Außerdem ermöglicht die Replikation warme Caches, was dazu beiträgt, dass die Abfrageleistung nach einem Failover konsistent bleibt.
Das folgende Diagramm zeigt die Architektur für Hochverfügbarkeit mit dem Hot-Standby-System.
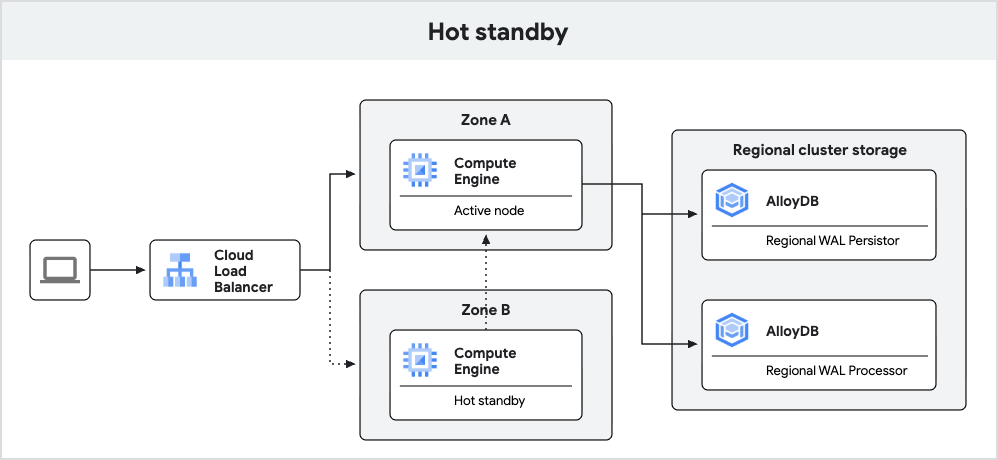
Abbildung 3 Hot-Standby.
Lesepools
Lesepoolinstanzen mit mindestens zwei Knoten sind hochverfügbar. Knoten werden gleichmäßig auf Zonen verteilt, um die Ausfallsicherheit zu erhöhen. Bei Ausfallereignissen wie einem Knoten- oder Zonenausfall leitet ein regionaler Load Balancer den Traffic an die verbleibenden fehlerfreien Knoten weiter, sodass es für Ihre Clients zu keinen Ausfallzeiten kommt.
Lesepools bleiben während eines Failovers der primären Instanz online. Die WAL-Replikation von der primären Instanz wird während des Failovers vorübergehend pausiert und automatisch fortgesetzt, nachdem die primäre Instanz wiederhergestellt wurde.
Nächste Schritte
- Manuelles Failover einer primären oder sekundären Instanz durchführen
- Primäre Instanz auf Hochverfügbarkeit testen
- Kosten mit einfachen Instanzen reduzieren