
במדריך הזה מוסבר איך להגדיר ולבצע חיפוש וקטורי ב-AlloyDB ל-PostgreSQL באמצעות מסוף Google Cloud . הדוגמאות נועדו להמחשה בלבד, כדי להציג את היכולות של חיפוש וקטורי.
מידע על שימוש בחיפוש וקטורים עם מסננים כדי לשפר את חיפושי הדמיון זמין במאמר חיפוש וקטורים עם מסננים ב-AlloyDB ל-PostgreSQL.
כדי ללמוד איך לבצע חיפוש וקטורי באמצעות הטמעות של Gemini Enterprise Agent Platform, אפשר לעיין במאמר קדימה, מתחילים: הטמעת וקטורים באמצעות AlloyDB AI.
מטרות
- יוצרים אשכול AlloyDB ומכונה ראשית.
- מתחברים למסד הנתונים ומתקינים את התוספים הנדרשים.
- תיצור טבלה של
productו-product inventory. - מכניסים נתונים לטבלאות
productו-product inventoryומבצעים חיפוש וקטורי בסיסי. - יוצרים אינדקס ScaNN בטבלת המוצרים.
- ביצוע חיפוש וקטורי בסיסי.
- ביצוע חיפוש וקטורי מורכב עם מסנן וצירוף.
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
כשמסיימים את המשימות שמתוארות במסמך הזה אפשר למחוק את המשאבים שיצרתם כדי להימנע מחיובים נוספים. מידע נוסף זמין בקטע הסרת המשאבים.
לפני שמתחילים
הפעלת החיוב וממשקי ה-API הנדרשים
נכנסים לדף Clusters במסוף Google Cloud .
מפעילים את ממשקי ה-API של Cloud שנדרשים כדי ליצור מכונת AlloyDB ל-PostgreSQL ולהתחבר אליה.
- בשלב אישור הפרויקט, לוחצים על הבא כדי לאשר את שם הפרויקט שרוצים לבצע בו שינויים.
בשלב Enable APIs (הפעלת ממשקי API), לוחצים על Enable (הפעלה) כדי להפעיל את ממשקי ה-API הבאים:
- AlloyDB API
- Compute Engine API
- Service Networking API
- Agent Platform API
יצירת אשכול ומכונה ראשית ב-AlloyDB
נכנסים לדף Clusters במסוף Google Cloud .
לוחצים על יצירת אשכול.
בשדה Cluster ID (מזהה האשכול), מזינים
my-cluster.מזינים סיסמה. חשוב לשים לב לסיסמה הזו כי תשתמשו בה במדריך הזה.
בוחרים אזור – לדוגמה,
us-central1 (Iowa).בוחרים את רשת ברירת המחדל.
אם יש לכם חיבור גישה פרטי, ממשיכים לשלב הבא. אם לא, לוחצים על הגדרת קישור ופועלים לפי השלבים הבאים:
- בקטע הקצאת טווח כתובות IP, לוחצים על שימוש בטווח כתובות IP שהוקצה באופן אוטומטי.
- לוחצים על המשך ואז על יצירת קישור.
בקטע זמינות אזורית, בוחרים באפשרות אזור יחיד.
בוחרים את
2 vCPU,16 GBסוג המכונה.בקטע קישוריות, בוחרים באפשרות הפעלת כתובת IP ציבורית.
לוחצים על יצירת אשכול. יכול להיות שיעברו כמה דקות עד ש-AlloyDB ייצור את האשכול ויציג אותו בדף סקירה כללית של האשכול הראשי.
בקטע Instances in your cluster (מופעים באשכול), מרחיבים את החלונית Connectivity (קישוריות). חשוב לשים לב למזהה ה-URI של החיבור כי תצטרכו להשתמש בו במדריך הזה.
ה-URI של החיבור הוא בפורמט
projects/<var>PROJECT_ID</var>/locations/<var>REGION_ID</var>/clusters/my-cluster/instances/my-cluster-primary.
מתן הרשאת משתמש ב-Agent Platform לסוכן שירות של AlloyDB
כדי לאפשר ל-AlloyDB להשתמש במודלים להטמעת טקסט של Agent Platform, צריך להוסיף הרשאות משתמש של Agent Platform לסוכן השירות של AlloyDB בפרויקט שבו נמצאים האשכול והמופע.
מידע נוסף על הוספת ההרשאות זמין במאמר איך מעניקים למשתמש בפלטפורמת הסוכנים הרשאה לסוכן השירות של AlloyDB.
התחברות למסד הנתונים באמצעות דפדפן אינטרנט
נכנסים לדף Clusters במסוף Google Cloud .
בעמודה שם משאב, לוחצים על שם האשכול,
my-cluster.בחלונית הניווט, לוחצים על AlloyDB Studio.
בדף Sign in to AlloyDB Studio (כניסה ל-AlloyDB Studio), פועלים לפי השלבים הבאים:
- בוחרים את מסד הנתונים
postgres. - בוחרים את המשתמש
postgres. - מזינים את הסיסמה שיצרתם בשלב יצירת אשכול והמופע הראשי שלו.
- לוחצים על אימות. בחלונית Explorer מוצגת רשימה של האובייקטים במסד הנתונים
postgres.
- בוחרים את מסד הנתונים
פותחים כרטיסייה חדשה על ידי לחיצה על + New SQL editor tab או על + New tab.
התקנת תוספים נדרשים
מריצים את השאילתה הבאה כדי להתקין את התוספים vector ו-alloydb_scann:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
הוספת נתוני מוצרים ומלאי מוצרים וביצוע חיפוש וקטורי בסיסי
מריצים את ההצהרה הבאה כדי ליצור טבלה
productשמבצעת את הפעולות הבאות:- שומר את פרטי המוצר הבסיסיים.
- כולל עמודת וקטור
embeddingשמחשבת ומאחסנת וקטור הטמעה לתיאור מוצר של כל מוצר.
CREATE TABLE product ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, category VARCHAR(255), color VARCHAR(255), embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005', description)) STORED );במידת הצורך, אפשר להשתמש ב-Logs Explorer כדי לראות יומנים ולפתור בעיות.
מריצים את השאילתה הבאה כדי ליצור טבלה
product_inventoryשמאחסנת מידע על מלאי זמין ומחירים תואמים. במדריך הזה נעשה שימוש בטבלאותproduct_inventoryו-productכדי להריץ שאילתות מורכבות של חיפוש וקטורים.CREATE TABLE product_inventory ( id INT PRIMARY KEY, product_id INT REFERENCES product(id), inventory INT, price DECIMAL(10,2) );מריצים את השאילתה הבאה כדי להוסיף נתוני מוצרים לטבלה
product:INSERT INTO product (id, name, description,category, color) VALUES (1, 'Stuffed Elephant', 'Soft plush elephant with floppy ears.', 'Plush Toys', 'Gray'), (2, 'Remote Control Airplane', 'Easy-to-fly remote control airplane.', 'Vehicles', 'Red'), (3, 'Wooden Train Set', 'Classic wooden train set with tracks and trains.', 'Vehicles', 'Multicolor'), (4, 'Kids Tool Set', 'Toy tool set with realistic tools.', 'Pretend Play', 'Multicolor'), (5, 'Play Food Set', 'Set of realistic play food items.', 'Pretend Play', 'Multicolor'), (6, 'Magnetic Tiles', 'Set of colorful magnetic tiles for building.', 'Construction Toys', 'Multicolor'), (7, 'Kids Microscope', 'Microscope for kids with different magnification levels.', 'Educational Toys', 'White'), (8, 'Telescope for Kids', 'Telescope designed for kids to explore the night sky.', 'Educational Toys', 'Blue'), (9, 'Coding Robot', 'Robot that teaches kids basic coding concepts.', 'Educational Toys', 'White'), (10, 'Kids Camera', 'Durable camera for kids to take pictures and videos.', 'Electronics', 'Pink'), (11, 'Walkie Talkies', 'Set of walkie talkies for kids to communicate.', 'Electronics', 'Blue'), (12, 'Karaoke Machine', 'Karaoke machine with built-in microphone and speaker.', 'Electronics', 'Black'), (13, 'Kids Drum Set', 'Drum set designed for kids with adjustable height.', 'Musical Instruments', 'Blue'), (14, 'Kids Guitar', 'Acoustic guitar for kids with nylon strings.', 'Musical Instruments', 'Brown'), (15, 'Kids Keyboard', 'Electronic keyboard with different instrument sounds.', 'Musical Instruments', 'Black'), (16, 'Art Easel', 'Double-sided art easel with chalkboard and whiteboard.', 'Arts & Crafts', 'White'), (17, 'Finger Paints', 'Set of non-toxic finger paints for kids.', 'Arts & Crafts', 'Multicolor'), (18, 'Modeling Clay', 'Set of colorful modeling clay.', 'Arts & Crafts', 'Multicolor'), (19, 'Watercolor Paint Set', 'Watercolor paint set with brushes and palette.', 'Arts & Crafts', 'Multicolor'), (20, 'Beading Kit', 'Kit for making bracelets and necklaces with beads.', 'Arts & Crafts', 'Multicolor'), (21, '3D Puzzle', '3D puzzle of a famous landmark.', 'Puzzles', 'Multicolor'), (22, 'Race Car Track Set', 'Race car track set with cars and accessories.', 'Vehicles', 'Multicolor'), (23, 'RC Monster Truck', 'Remote control monster truck with oversized tires.', 'Vehicles', 'Green'), (24, 'Train Track Expansion Set', 'Expansion set for wooden train tracks.', 'Vehicles', 'Multicolor');אופציונלי: מריצים את השאילתה הבאה כדי לוודא שהנתונים מוכנסים לטבלה
product:SELECT * FROM product;מריצים את השאילתה הבאה כדי להוסיף נתוני מלאי לטבלה
product_inventory:INSERT INTO product_inventory (id, product_id, inventory, price) VALUES (1, 1, 9, 13.09), (2, 2, 40, 79.82), (3, 3, 34, 52.49), (4, 4, 9, 12.03), (5, 5, 36, 71.29), (6, 6, 10, 51.49), (7, 7, 7, 37.35), (8, 8, 6, 10.87), (9, 9, 7, 42.47), (10, 10, 3, 24.35), (11, 11, 4, 10.20), (12, 12, 47, 74.57), (13, 13, 5, 28.54), (14, 14, 11, 25.58), (15, 15, 21, 69.84), (16, 16, 6, 47.73), (17, 17, 26, 81.00), (18, 18, 11, 91.60), (19, 19, 8, 78.53), (20, 20, 43, 84.33), (21, 21, 46, 90.01), (22, 22, 6, 49.82), (23, 23, 37, 50.20), (24, 24, 27, 99.27);מריצים את שאילתת החיפוש הווקטורית הבאה שמנסה למצוא מוצרים שדומים למילה
music. המשמעות היא שגם אם המילהmusicלא מוזכרת במפורש בתיאור המוצר, בתוצאה מוצגים מוצרים שרלוונטיים לשאילתה:SELECT * FROM product ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector LIMIT 3;תוצאת השאילתה היא:
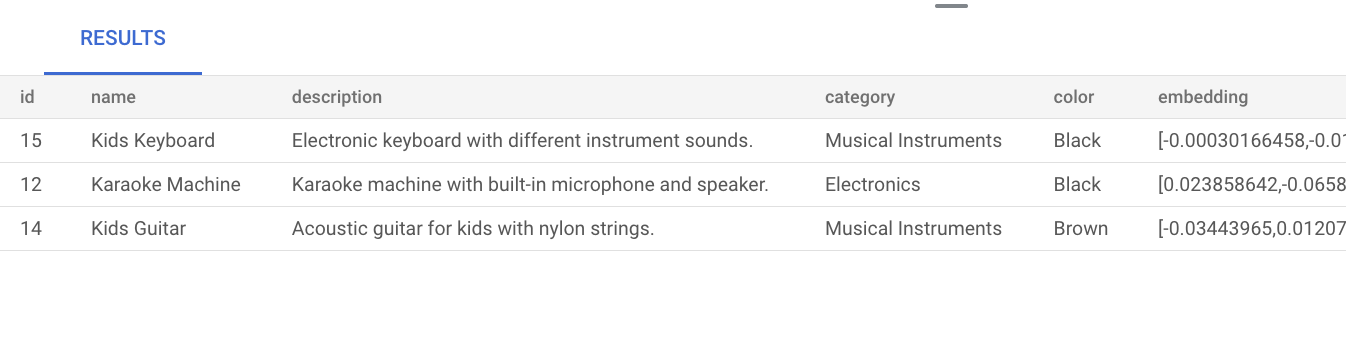
כשמבצעים חיפוש וקטורי בסיסי בלי ליצור אינדקס, נעשה שימוש בחיפוש מדויק של השכן הקרוב ביותר (KNN), שמספק אחזור יעיל. שימוש ב-KNN בקנה מידה גדול עלול להשפיע על הביצועים. כדי לשפר את הביצועים של השאילתות, מומלץ להשתמש באינדקס ScaNN לחיפוש של השכן הקרוב המשוער (ANN), שמספק אחזור גבוה עם חביון נמוך.
אם לא יוצרים אינדקס, ברירת המחדל של AlloyDB היא שימוש בחיפוש התאמה מדויקת של השכן הקרוב ביותר (KNN).
למידע נוסף על שימוש ב-ScaNN בקנה מידה גדול, אפשר לקרוא את המאמר קדימה, מתחילים: הטמעת וקטורים באמצעות AlloyDB AI.
יצירת אינדקס ScaNN עם כוונון ידני בטבלת מוצרים
מריצים את השאילתה הבאה כדי ליצור אינדקס product_index ScaNN בטבלה product:
CREATE INDEX product_index ON product
USING scann (embedding cosine)
WITH (mode='MANUAL', num_leaves=4);
מידע נוסף על יצירת אינדקס ScaNN
ביצוע חיפוש וקטורי
מריצים את שאילתת החיפוש הווקטורי הבאה שמנסה למצוא מוצרים שדומים לשאילתת השפה הטבעית music. למרות שהמילה music לא נכללת בתיאור המוצר, בתוצאה מוצגים מוצרים שרלוונטיים לשאילתה:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
אלה תוצאות השאילתה:

פרמטר השאילתה scann.num_leaves_to_search קובע את מספר צמתי העלה שמתבצע בהם חיפוש במהלך חיפוש דמיון. הערכים של הפרמטרים num_leaves ו-scann.num_leaves_to_search עוזרים להשיג איזון בין הביצועים לבין היכולת לאחזר מידע.
ביצוע חיפוש וקטורי שמשתמש במסנן ובצירוף
אתם יכולים להריץ שאילתות חיפוש וקטורי מסוננות ביעילות גם כשאתם משתמשים באינדקס ScaNN. מריצים את שאילתת החיפוש הווקטורי המורכבת הבאה, שמחזירה תוצאות רלוונטיות שעומדות בתנאי השאילתה, גם עם מסננים:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product p
JOIN product_inventory pi ON p.id = pi.product_id
WHERE pi.price < 80.00
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
איך להאיץ את החיפוש הווקטורי עם מסננים
אתם יכולים להשתמש בחנות התוכן של מנוע החיפוש כדי לשפר את הביצועים של חיפושים לפי דמיון וקטורי, במיוחד חיפושים של K-Nearest Neighbor (KNN), בשילוב עם סינון פרדיקטים סלקטיבי מאוד – לדוגמה, באמצעות LIKE – במסדי נתונים. בקטע הזה משתמשים בתוסף vector ובתוסף google_columnar_engine של AlloyDB.
מידע נוסף על אופן הפעולה של מנוע העמודות זמין במאמר בנושא מנוע העמודות של AlloyDB.
השיפורים בביצועים נובעים מהיעילות המובנית של מנוע העמודות בסריקת מערכי נתונים גדולים ובהחלת מסננים – כמו LIKEתנאים – בשילוב עם היכולת שלו, באמצעות תמיכה בווקטורים, לסנן מראש שורות. הפונקציונליות הזו מצמצמת את מספר קבוצות המשנה של הנתונים שנדרשות לחישובים הבאים של מרחק וקטורי KNN, ועוזרת לבצע אופטימיזציה של שאילתות אנליטיות מורכבות שכוללות סינון רגיל וחיפוש וקטורי.
החנות העמודתית מציעה שתי אפשרויות לניהול התוכן שלה:
- ניהול אוטומטי של תוכן מאגר העמודות: מופעי AlloyDB חדשים משתמשים כברירת מחדל בתהליך אוטומטי של המרת נתונים לעמודות. לחלופין, אפשר להפעיל באופן ידני את התכונה של יצירת עמודות אוטומטית.
- ניהול ידני של תוכן בחנות העמודות: אם אתם צריכים לנהל באופן ידני את העמודות בחנות העמודות עבור עומס העבודה, אתם יכולים להשבית את ההמרה האוטומטית לעמודות.
כדי להשוות את זמן הביצוע של חיפוש וקטורי KNN שסונן לפי LIKE
predicate לפני ואחרי שמפעילים את מנוע העמודות, פועלים לפי השלבים הבאים:
מפעילים את התוסף
vectorכדי לתמוך בסוגי נתונים וקטוריים ובפעולות. מריצים את ההצהרות הבאות כדי ליצור טבלה לדוגמה (items) עם מזהה, תיאור טקסט ועמודת הטמעה של וקטור עם 512 ממדים.CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE items ( id SERIAL PRIMARY KEY, description TEXT, embedding VECTOR(512) );כדי לאכלס את הנתונים, מריצים את ההצהרות הבאות כדי להוסיף מיליון שורות לטבלת הדוגמה
items.-- Simplified example of inserting matching (~0.1%) and non-matching data INSERT INTO items (description, embedding) SELECT CASE WHEN g % 1000 = 0 THEN 'product_' || md5(random()::text) || '_common' -- ~0.1% match ELSE 'generic_item_' || g || '_' || md5(random()::text) -- ~99.9% don't match END, random_vector(512) -- Assumes random_vector function exists FROM generate_series(1, 999999) g;מדידת ביצועי הבסיס של חיפוש הדמיון הווקטורי ללא מנוע עמודות.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;מריצים את הפקודה הבאה ב-CLI של Google Cloud כדי להפעיל את מנוע העמודות ואת התמיכה בווקטורים. כדי להשתמש ב-CLI של gcloud, אפשר להתקין ולהפעיל את ה-CLI של gcloud.
gcloud beta alloydb instances update INSTANCE_ID \ --cluster=CLUSTER_ID \ --region=REGION_ID \ --project=PROJECT_ID \ --database-flags=google_columnar_engine.enabled=on,google_columnar_engine.enable_vector_support=onמחליפים את מה שכתוב בשדות הבאים:
-
INSTANCE_ID: מזהה המכונה. -
CLUSTER_ID: מזהה האשכול. -
REGION_ID: האזור שבו נמצא האשכול. -
PROJECT_ID: מזהה הפרויקט שבו נמצא האשכול.
-
מוסיפים את הטבלה
itemsלמנוע העמודות:SELECT google_columnar_engine_add('items');מדידת הביצועים של חיפוש הדמיון הווקטורי באמצעות מנוע עמודות. מריצים מחדש את השאילתה שהרצתם קודם כדי למדוד את ביצועי הבסיס.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;כדי לבדוק אם השאילתה הופעלה באמצעות מנוע עמודות, מריצים את הפקודה הבאה:
explain (analyze) SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
הסרת המשאבים
נכנסים לדף Clusters במסוף Google Cloud .
לוחצים על שם האשכול,
my-cluster, בעמודה שם משאב.לוחצים על delete מחיקת האוסף.
בקטע Delete cluster my-cluster, מזינים
my-clusterכדי לאשר את מחיקת האשכול.לוחצים על Delete.
אם יצרתם חיבור פרטי כשיצרתם אשכול, עוברים אל הדף 'רשת' במסוף Google Cloud ולוחצים על מחיקת רשת VPC.
המאמרים הבאים
- תרחישים לדוגמה של שימוש בחיפוש וקטורי
- איך מתחילים להשתמש בהטמעות וקטורים באמצעות AlloyDB AI
- איך יוצרים אפליקציות מבוססות-AI גנרטיבי באמצעות AlloyDB AI
- יוצרים אינדקס ScaNN.
- שיפור האינדקסים של ScaNN.
- איך יוצרים עוזר חכם לשופינג באמצעות AlloyDB, pgvector וניהול נקודות קצה של מודלים
- איך מאיצים חיפוש וקטורי באמצעות מנוע מבוסס-עמודות