
Les fonctions optimisées vous permettent d'utiliser un modèle proxy plus petit et plus rapide pour traiter la plupart de vos requêtes, puis de revenir à un LLM plus grand uniquement lorsque cela est nécessaire. Cette approche réduit les coûts opérationnels et améliore la réactivité des requêtes. Les fonctions optimisées minimisent l'utilisation des LLM pour les tâches de classification ou de filtrage ligne par ligne, qui peuvent être mieux gérées par le modèle proxy.
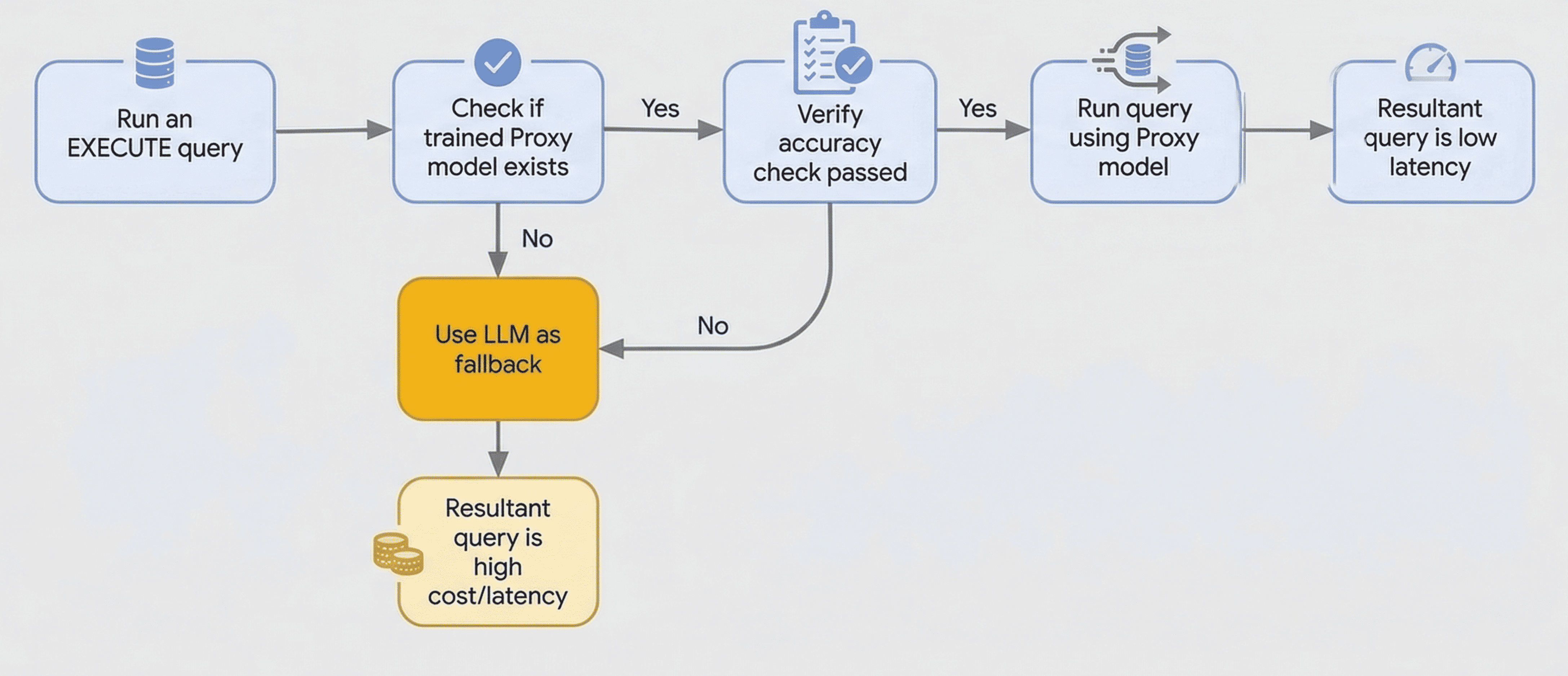
Les fonctions AlloyDB/AI, comme ai.if(), peuvent avoir une latence élevée en raison des appels à distance aux grands modèles de langage (LLM). Les fonctions optimisées résolvent ce problème de latence en utilisant des modèles proxy plus petits, entraînés localement, pour traiter vos requêtes. Ces modèles sont entraînés sur un échantillon de vos données, en utilisant la sortie du LLM comme source de référence.
Des vérifications de la précision sont effectuées au moment de l'exécution sur un échantillon de lignes à l'aide du LLM. Pour effectuer cette vérification, AlloyDB utilise le LLM pour générer des libellés pour les lignes d'échantillon et les compare aux prédictions du modèle proxy afin de vérifier l'exactitude. Si la vérification de la précision échoue, la requête revient à l'utilisation du LLM.
Lorsque vous utilisez une fonction optimisée, AlloyDB effectue les opérations suivantes :
- Entraînement d'un modèle proxy : AlloyDB entraîne un modèle proxy léger sur un échantillon de vos données. Cela se produit en arrière-plan lorsque vous utilisez l'instruction
PREPAREavec la fonctionai.if()pour entraîner le modèle pour les requêtes optimisées. - Exécute la requête : lorsque vous utilisez l'instruction
EXECUTE, AlloyDB utilise le modèle proxy entraîné pour traiter la requête en local. - Retour au LLM : si la précision du modèle est faible ou si AlloyDB ne trouve pas de modèle, AlloyDB revient automatiquement à l'utilisation du LLM.
Avant de commencer
Avant d'utiliser les fonctions optimisées, procédez comme suit :
- Connectez-vous à votre base de données à l'aide de psql ou d'AlloyDB Studio en tant qu'utilisateur
postgresou en tant qu'utilisateur ayant accès à la table dans laquelle se trouvent les données. Vérifiez que l'extension
google_ml_integrationest installée et disponible dans la version 1.5.8 ou ultérieure.SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.8 (1 row)Configurez AlloyDB pour qu'il fonctionne avec Vertex AI. Pour en savoir plus, consultez Intégrer votre base de données à Vertex AI.
Assurez-vous que les indicateurs de base de données suivants sont activés. Pour en savoir plus, consultez Configurer les options de base de données d'une instance.
google_ml_integration.enable_model_supportgoogle_ml_integration.enable_ai_query_enginegoogle_ml_integration.enable_cost_optimized_ai_functions
Générez des embeddings pour la table que vous souhaitez interroger. Pour en savoir plus, consultez Générer et gérer des embeddings automatiques pour les tableaux.
Tenez compte des points suivants :
- La colonne de données source doit être de type
TEXTouVARCHAR. - La colonne d'embedding qui fournit l'entrée à la fonction d'IA optimisée doit être de type
REAL[]ouVECTOR. - Les fonctions optimisées ne sont disponibles que dans les régions où les modèles génératifs Vertex AI sont disponibles. Pour obtenir la liste des régions disponibles, consultez Emplacements de l'IA générative.
- La colonne de données source doit être de type
Utiliser des fonctions optimisées
Pour utiliser une fonction optimisée, utilisez les instructions PREPARE et EXECUTE avec la fonction ai.if(). Voici un exemple d'utilisation d'une fonction optimisée :
Créez une table
restaurant_reviews. La colonnereviewcontenant les données sources est de typeTEXT, et la colonnereview_embeddingutilisée pour les requêtes est de typeVECTOR(768).CREATE TABLE restaurant_reviews ( id SERIAL, name VARCHAR(64), city VARCHAR(64), review TEXT, review_embedding VECTOR(768) );Utilisez une instruction
PREPAREavec la fonctionai.if()pour indiquer que la requête doit utiliser une fonction optimisée. Cette instruction déclenche l'entraînement asynchrone du modèle en arrière-plan.Le modèle n'est entraîné que dans les conditions suivantes :
- La requête contient exactement une fonction
ai.if(). ai.if()ne se trouve pas dans une sous-requête.
PREPARE positive_reviews_query AS SELECT r.name, r.city FROM restaurant_reviews r WHERE ai.if('Is the following a positive review? Review: ' || r.review, r.review_embedding) GROUP BY r.name, r.city HAVING COUNT(*) > 500;- La requête contient exactement une fonction
Exécutez la requête à l'aide de l'instruction
EXECUTE. Comme l'instructionPREPAREest spécifique à la session en cours, vous devez exécuter l'instructionEXECUTEsur la même connexion :EXECUTE positive_reviews_query;conn2=> SELECT r.name, r.city FROM restaurant_reviews r WHERE ai.if('Is the following a positive review? Review: ' || r.review, r.review_embedding) GROUP BY r.name, r.city HAVING COUNT(*) > 500;Le modèle proxy entraîné n'est pas utilisé si l'une des conditions suivantes est remplie :
- La colonne de contenu ou d'intégration référencée dans
ai.if()change. Les deux colonnes doivent appartenir à la même table. - La requête fournie à la colonne de contenu change.
- La structure de la requête change, ce qui entraîne un
query_iddifférent. - La requête ne respecte pas le seuil de vérification de l'exactitude au début de la requête.
Dans ce cas, la requête revient à l'utilisation du LLM et AlloyDB renvoie un avertissement.
- La colonne de contenu ou d'intégration référencée dans
Facultatif. Pour désactiver la vérification de la précision pour l'ensemble de l'environnement de base de données, ce qui est nécessaire, car des vérifications de la précision sont également effectuées lors de l'entraînement du modèle, exécutez la commande suivante.
ALTER DATABASE DATABASE_NAME SET google_ml_integration.runtime_accuracy_check = off;Remplacez
DATABASE_NAMEpar le nom de votre base de données.
Réentraîner un modèle proxy
Si les données de votre tableau sous-jacent changent de manière significative, vous pouvez réentraîner le modèle proxy en exécutant à nouveau l'instruction PREPARE. La préparation d'une requête remplace le modèle proxy existant en lançant une nouvelle demande d'entraînement.
Limites
Si vous modifiez la colonne de contenu source, la colonne d'intégration ou l'invite fournie à la fonction ai.if(), vous devez émettre une nouvelle instruction PREPARE.
AlloyDB entraîne la fonction optimisée pour approximer le comportement d'une combinaison unique de données d'entrée et d'invite.