
Mit der Sprachübersetzung können Sie Ihre Streaming-Audiodaten in Echtzeit in transkribierten Text umwandeln. Agent Assist macht Vorschläge auf Grundlage von Text. Audiodaten müssen also konvertiert werden, bevor sie verwendet werden können. Sie können auch transkribierte Streaming-Audiodaten mit Customer Experience Insights verwenden, um Echtzeitdaten zu Agent-Unterhaltungen zu erfassen, z. B. Themenmodellierung.
Es gibt zwei Möglichkeiten, Streaming-Audio für die Verwendung mit Agent Assist zu transkribieren: entweder mit der SIPREC-Funktion oder durch gRPC-Aufrufe mit Audiodaten als Nutzlast. Auf dieser Seite wird beschrieben, wie Sie Streaming-Audiodaten mit gRPC-Aufrufen transkribieren.
Die Sprache wird mithilfe der Streamingerkennung von Speech-to-Text transkribiert. Speech-to-Text bietet mehrere Erkennungsmodelle, Standard- und optimierte. Agent Assist schränkt nicht ein, welche Modelle Sie für die Sprachtranskription verwenden können. Die Sprachtranskription wird jedoch auf GA-Ebene nur unterstützt, wenn sie mit dem Telefonie- oder Chirp 3-Modell verwendet wird. Für eine optimale Transkriptionsqualität wird das Modell Chirp 3 empfohlen, sofern es in Ihrer Region verfügbar ist.
Vorbereitung
- Erstellen Sie ein Projekt inGoogle Cloud.
- Dialogflow API aktivieren
- Wenden Sie sich an Ihren Google-Kundenbetreuer, um sicherzustellen, dass Ihr Konto Zugriff auf erweiterte Speech-to-Text-Modelle hat.
Unterhaltungsprofil erstellen
Wenn Sie ein Unterhaltungsprofil erstellen möchten, verwenden Sie die Agent Assist Console oder rufen Sie die Methode create für die Ressource ConversationProfile direkt auf.
Für die Spracheingabe empfehlen wir, ConversationProfile.stt_config als Standard-InputAudioConfig zu konfigurieren, wenn Audiodaten in einer Unterhaltung gesendet werden.
![]()
Transkriptionen während der Unterhaltung abrufen
Wenn Sie während der Unterhaltung Transkriptionen erhalten möchten, müssen Sie Teilnehmer für die Unterhaltung erstellen und Audiodaten für jeden Teilnehmer senden.
Teilnehmer erstellen
Es gibt drei Arten von Teilnehmern.
Weitere Informationen zu ihren Rollen finden Sie in der Referenzdokumentation. Rufen Sie die Methode create für participant auf und geben Sie role an. Nur ein Teilnehmer mit END_USER oder HUMAN_AGENT kann StreamingAnalyzeContent anrufen, was für eine Transkription erforderlich ist.
Audiodaten senden und ein Transkript erhalten
Sie können StreamingAnalyzeContent verwenden, um das Audio eines Teilnehmers an Google zu senden und ein Transkript zu erhalten. Dazu sind die folgenden Parameter erforderlich:
Die erste Anfrage im Stream muss
InputAudioConfigsein. Die hier konfigurierten Felder überschreiben die entsprechenden Einstellungen unterConversationProfile.stt_config. Senden Sie erst bei der zweiten Anfrage Audioeingaben.audioEncodingmuss aufAUDIO_ENCODING_LINEAR_16oderAUDIO_ENCODING_MULAWfestgelegt werden.model: Das ist das Speech-to-Text-Modell, das Sie zum Transkribieren Ihrer Audioinhalte verwenden möchten. Setzen Sie dieses Feld aufchirp_3. Die Variante hat keinen Einfluss auf die Transkriptionsqualität. Sie können Sprachmodellvariante also leer lassen oder Beste verfügbare verwenden auswählen.singleUtterancesollte für eine optimale Transkriptionsqualität auffalsefestgelegt werden. Sie solltenEND_OF_SINGLE_UTTERANCEnicht erwarten, wennsingleUtterancefalseist. Sie können sich jedoch aufisFinal==trueinnerhalb vonStreamingAnalyzeContentResponse.recognition_resultverlassen, um den Stream halb zu schließen.- Optionale zusätzliche Parameter: Die folgenden Parameter sind optional. Wenden Sie sich an Ihren Google-Ansprechpartner, um Zugriff auf diese Parameter zu erhalten.
languageCode:language_codedes Audios. Der Standardwert isten-US.alternativeLanguageCodes: Diese Funktion ist nur für das Chirp 3-Modell auf GA-Ebene verfügbar. Zusätzliche Sprachen, die im Audio erkannt werden könnten. Agent Assist verwendet das Feldlanguage_code, um die Sprache am Anfang des Audios automatisch zu erkennen und in allen folgenden Unterhaltungsrunden standardmäßig zu verwenden. Im FeldalternativeLanguageCodeskönnen Sie weitere Optionen für Agent Assist angeben.phraseSets: Der Ressourcenname der Speech-to-Text-ModellanpassungphraseSet>.- Wenn Sie die Anpassung für das Chirp 3-Modell konfigurieren möchten, fügen Sie Inline-Phrasen hinzu, die durch Zeilenumbrüche getrennt sind, ohne Kommas.
- Wenn Sie die Modellanpassung mit anderen Modellen wie
telephonyfür die Sprachtranskription verwenden möchten, müssen Sie zuerst dasphraseSetmit der Speech-to-Text API erstellen und den Ressourcennamen hier angeben.
Nachdem Sie die zweite Anfrage mit der Audio-Nutzlast gesendet haben, sollten Sie einige
StreamingAnalyzeContentResponsesaus dem Stream empfangen.- Sie können den Stream halb schließen (oder das Senden in einigen Sprachen wie Python beenden), wenn
is_finalinStreamingAnalyzeContentResponse.recognition_resultauftruegesetzt ist. - Nachdem Sie den Stream halb geschlossen haben, sendet der Server die Antwort mit dem endgültigen Transkript sowie mögliche Dialogflow- oder Agent Assist-Vorschläge zurück.
- Sie können den Stream halb schließen (oder das Senden in einigen Sprachen wie Python beenden), wenn
Sie finden die endgültige Transkription an den folgenden Stellen:
StreamingAnalyzeContentResponse.message.content.- Wenn Sie Pub/Sub-Benachrichtigungen aktivieren, können Sie das Transkript auch in Pub/Sub aufrufen.
Starten Sie einen neuen Stream, nachdem der vorherige Stream geschlossen wurde.
- Audio neu senden: Audiodaten, die nach dem letzten
speech_end_offsetder Antwort mitis_final=truegeneriert wurden, müssen für eine optimale Transkriptionsqualität anStreamingAnalyzeContentgesendet werden.
- Audio neu senden: Audiodaten, die nach dem letzten
Das folgende Diagramm veranschaulicht die Funktionsweise von Streams.
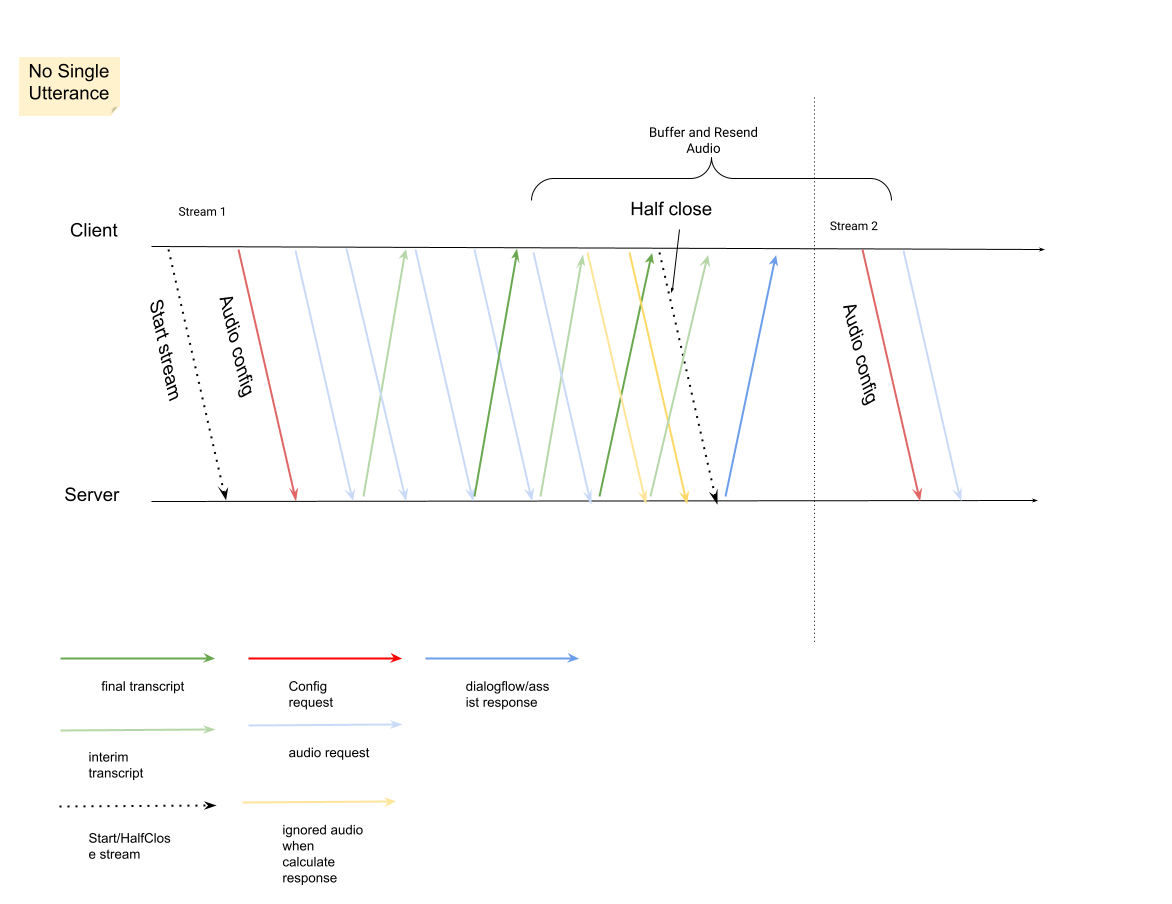
Beispielcode für Streamingerkennungsanfrage
Im folgenden Codebeispiel wird gezeigt, wie eine Streaming-Transkriptionsanfrage gesendet wird:
Python
Richten Sie zur Authentifizierung bei Agent Assist Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.