
生成ナレッジ アシストは、提供されたドキュメントの情報に基づいてエージェントの質問に回答します。フローベースのデータストア エージェントまたはハンドブックベースのデータストア エージェントのドメイン名を指定することも、ドキュメントをアップロードすることもできます。生成ナレッジ アシストは、その情報を進行中の会話と利用可能な顧客メタデータと組み合わせて、エージェントに適切かつタイムリーな回答を提供します。
始める前に
プロジェクト オーナーでない場合は、データストア エージェントを作成するために次のロールが必要です。
- Dialogflow API Admin
- Discovery Engine Admin
フローベースのデータストア エージェントを作成する
Vertex AI コンソールで AI Applications API を有効にします。
エージェントを作成するには、フローベースのデータストア エージェントの手順に沿って操作します。
ハンドブックベースのデータストア エージェントを作成する
Vertex AI コンソールで AI Applications API を有効にします。
エージェントを作成するには、ハンドブックベースのデータストア エージェントの手順に沿って操作します。
エージェントをデータストアに接続するには、データストア ツールを作成します。詳しくは、ハンドブック データストア ツールの例をご覧ください。
人間のエージェントからの質問に回答する
フローベースまたはハンドブックベースのデータストア エージェントは、提供されたドキュメントに基づいて人間のエージェントからの質問に回答できます。
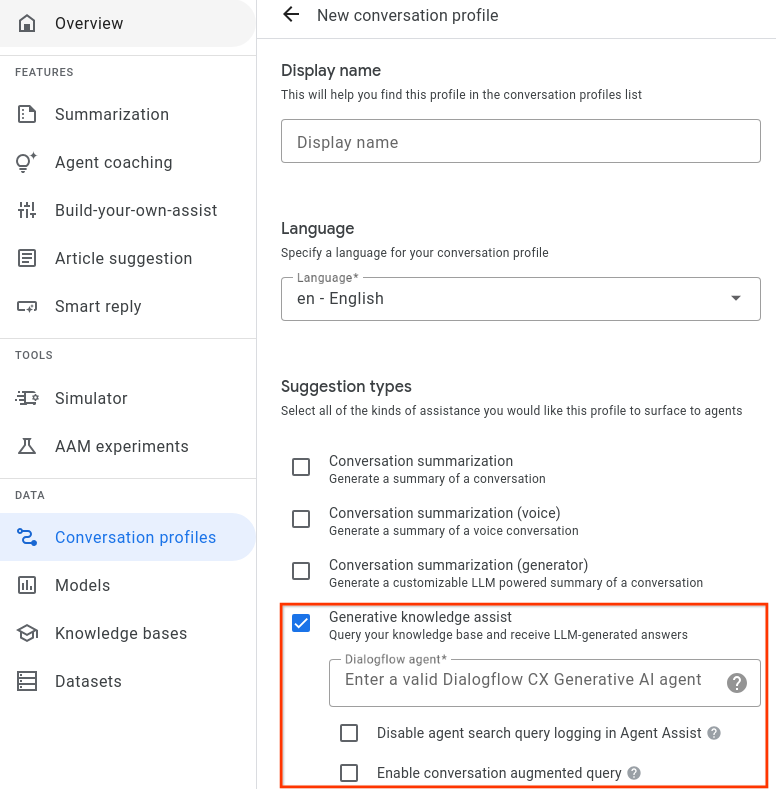
ステップ 1: 会話プロファイルを作成する
会話プロファイルを作成するには、Agent Assist コンソールまたは API を使用します。
コンソールから作成する
- 生成ナレッジ アシストの提案タイプを有効にして、前のステップのフローベースまたはハンドブックベースのデータストア エージェントにリンクする必要があります。
- 省略可: [エージェント検索クエリのロギングを無効にする] チェックボックスを使用して、品質向上のために秘匿化された検索クエリを収集して保存するかどうかを指定します。
- [会話拡張クエリを有効にする] チェックボックスを使用して、検索クエリの回答を生成する際に、人間のエージェントとユーザー間の会話コンテキストを考慮するかどうかを指定できます。
API から作成する
次の手順では、ConversationProfile オブジェクトを使用して HumanAgentAssistantConfig を作成する方法について説明します。Agent Assist コンソールを使用してこれらの操作を行うこともできます。
会話プロファイルを作成するには、ConversationProfile リソースの create メソッドを呼び出します。
リクエストのデータを使用する前に、次のように置き換えます。- PROJECT_ID: プロジェクト ID
- LOCATION_ID: ロケーションの ID
- AGENT_ID: 前のステップのフローベースまたはハンドブックベースのデータストア エージェント ID
{ "displayName": "my-conversation-profile-display-name", "humanAgentAssistantConfig": { "humanAgentSuggestionConfig": { "featureConfigs": [ { "suggestionFeature": { "type": "KNOWLEDGE_SEARCH" }, "queryConfig": { "dialogflowQuerySource": { "humanAgentSideConfig": { "agent": "projects/PROJECT_ID/locations/LOCATION_ID/agents/AGENT_ID" } } }, "disableAgentQueryLogging": false, "enableConversationAugmentedQuery": false, } ] } } }
Agent Assist コンソールで会話プロファイルを作成すると、生成ナレッジ アシストが自動的に有効になります。
ステップ 2: データストア エージェントを使用する
必要に応じて、
SearchKnowledge
API を使用してデータストア エージェントから回答を取得します。SearchKnowledge リクエストの一部として、次の構成を使用することもできます。
querySource: エージェントがクエリを入力したか、生成ナレッジ アシストが自動的に提案したかを示すように、このフィールドを設定します。exactSearch: クエリの書き換えを行わずに正確な入力クエリを検索するかどうかを示すように、このフィールドを設定します。endUserMetadata: 生成された回答を改善するエンドユーザーに関する追加情報を含めるように、このフィールドを設定します。詳しくは、データストア エージェントのパフォーマンスのパーソナライズ ページをご覧ください。searchConfig: ナレッジ ドキュメントのブーストとフィルタリングをさらに制御するように、このフィールドを設定します。詳しくは、データストア エージェントのパフォーマンスの検索構成ページをご覧ください。
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- LOCATION_ID: ロケーションの ID
- CONVERSATION_PROFILE_ID: 前のステップの会話プロファイル ID
- SESSION_ID: 検索セッション ID 同じセッションの検索履歴が検索結果に影響する可能性があります。セッション ID には、次の会話 ID を使用できます。
- CONVERSATION_ID: 検索リクエストがトリガーされる会話(人間のエージェントとエンドユーザーの間)
- MESSAGE_ID: 検索リクエストがトリガーされたときの最新の会話メッセージ
JSON リクエストの例を次に示します。
{ "parent": "projects/PROJECT_ID/locations/LOCATION_ID" "query": { "text": "What is the return policy?" } "conversationProfile": "projects/PROJECT_ID/locations/LOCATION_ID/conversationProfiles/CONVERSATION_PROFILE_ID" "sessionId": "SESSION_ID "conversation": "projects/PROJECT_ID/locations/LOCATION_ID/conversations/CONVERSATION_ID" "latestMessage": "projects/PROJECT_ID/locations/LOCATION_ID/conversations/CONVERSATION_ID/messages/MESSAGE_ID "querySource": AGENT_QUERY "exactSearch": false "searchConfig": { "filterSpecs": { "filter": "category: ANY(\"persona_B\")" } } "endUserMetadata": { "deviceOwned": "Google Pixel 7" } }
必要に応じて、エージェントの検索がユーザーとの会話中に行われる場合は、conversation リソース名と latest_message リソース名を指定します。これらの 2 つのフィールドは、enable_conversation_augmented_query オプションを有効にして、エージェントとユーザー間の会話コンテキストを使用してクエリ回答エクスペリエンスを向上させる場合に必要です。
シミュレータ
Agent Assist シミュレータで、フローベースまたはハンドブックベースのデータストア エージェントをテストします。
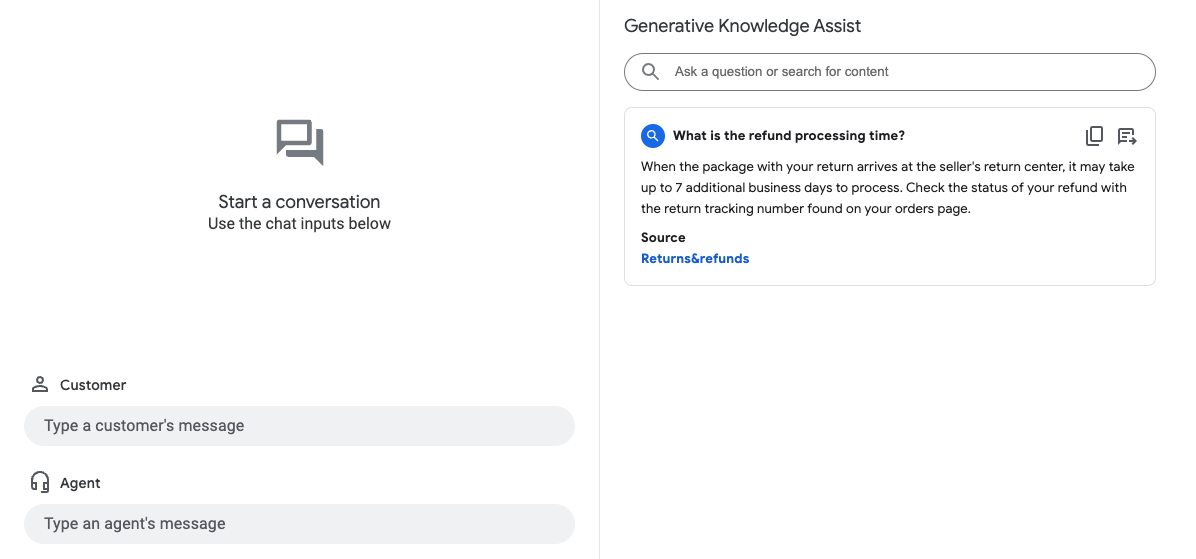
上記の例では、フローベースのデータストア エージェントは、ユーザーのクエリ What is the refund
processing time? に次の情報で回答します。
- 生成 AI が生成した回答: 返品された荷物が販売者の返品センターに到着してから、処理に最長で 7 営業日かかる場合があります。注文ページに記載されている返品追跡番号で払い戻しのステータスをご確認ください。
- 関連するナレッジ ドキュメントのタイトル: 返品と払い戻し。
フィードバックを送信
フィードバックを送信する手順については、Agent Assist にフィードバックを送信するをご覧ください。
エージェントの質問に回答する
エージェントの質問への回答に関するフィードバックを送信するための JSON リクエストの例を次に示します。
{ "name": "projects/PROJECT_ID/locations/LOCATION_ID/answerRecords/ANSWER_RECORD_ID", "answerFeedback": { "displayed": true "clicked": true "correctnessLevel": "FULLY_CORRECT" "agentAssistantDetailFeedback": { "knowledgeSearchFeedback": { "answerCopied": true "clickedUris": [ "url_1", "url_2", "url_3", ] } } } }
メタデータ
ナレッジ ドキュメントのメタデータを構成すると、生成ナレッジ アシストとプロアクティブ生成ナレッジ アシストの両方で、レスポンスとともにドキュメントのメタデータが返されます。
たとえば、メタデータを使用して、ナレッジ ドキュメントが社内の非公開記事か、外部の公開記事かをマークできます。Agent Assist シミュレータと UI モジュールの両方で、生成ナレッジ アシストとプロアクティブ生成ナレッジ アシストの両方で、特定のキーのドキュメント メタデータ値が自動的に表示されます。
gka_source_label: 値は提案カードに直接表示されます。gka_source_tooltip: 値がstruct型の場合、ソースリンクにカーソルを合わせると展開され、値がツールチップに表示されます。
ナレッジ ドキュメントに次のメタデータがある場合、提案カードにはソースが External Doc と表示され、ツールチップには doc_visibility: public doc が追加されます。
メタデータ:
None
{
"title": "Public Sample Doc",
"gka_source_label": "External Doc",
"gka_source_tooltip": {
"doc_visibility": "public doc"
}
}
エンドユーザーのメタデータ
エンドユーザーのメタデータを添付して、データストア エージェントによって生成される回答を改善し、パーソナライズします。生成ナレッジ アシストの場合は、エンドユーザーのメタデータを end_user_metadata フィールドに添付するか、IngestContextReferences API を使用して会話に取り込むことができます。取り込んだエンドユーザーのメタデータは、生成ナレッジ アシストとプロアクティブ生成ナレッジ アシストの両方で使用できます。
例 1: エンドユーザーのメタデータを添付する
{
"query": {
"text": "test query"
},
"conversationProfile": "projects/PROJECT_ID/locations/LOCATION_ID/conversationProfiles/CONVERSATION_PROFILE_ID",
"sessionId": "SESSION_ID",
"conversation": "projects/PROJECT_ID/locations/LOCATION_ID/conversations/CONVERSATION_ID",
"querySource": "AGENT_QUERY",
"endUserMetadata": {
"Name": "Jack",
"Age": 33,
"City": "Tokyo"
}
}
例 2: エンドユーザーのメタデータを取り込む
{
"conversation": "projects/PROJECT_ID/locations/global/conversations/CONVERSATION_ID",
"contextReferences": {
"gka_end_user_metadata": {
"contextContents": [{
"content": "{\"Name\":\"Jack\",\"Age\":33,\"city\":\"Tokyo\"}",
"contentFormat": "JSON"
}],
"updateMode": "OVERWRITE",
"languageCode": "en-US"
}
}
}
データストアのエンドユーザーのメタデータの詳細については、Dialogflow のパーソナライズに関する情報をご覧ください。
言語サポート
詳しくは、対応言語の全リストをご覧ください。