
架构
下图显示了使用 Workflows 的无服务器提取、加载和转换 (ELT) 流水线的概要架构。

在上图中,假设一个零售平台定期从各个商店以文件形式收集销售事件,然后将文件写入 Cloud Storage 存储分区。事件用于通过在 BigQuery 中导入和处理来提供业务指标。此架构提供了一个用于将文件导入到 BigQuery 中的可靠、无服务器的编排系统,它分为以下两个模块:
- 文件列表:维护已添加到 Cloud Storage 存储分区内 Firestore 集合中的未处理文件的列表。此模块通过 Cloud Run 函数工作,该函数通过对象完成存储事件触发,而该事件在将新文件添加到 Cloud Storage 存储桶时生成。文件名会附加到 Firestore 中名为
new的集合files数组中。 工作流:运行计划的工作流。Cloud Scheduler 会触发一个工作流,它根据基于 YAML 的语法运行一系列步骤来编排加载,然后通过调用 Cloud Run 函数来转换 BigQuery 中的数据。工作流中的步骤调用 Cloud Run functions 函数以运行以下任务:
- 创建并启动 BigQuery 加载作业。
- 轮询加载作业状态。
- 创建并启动转换查询作业。
- 轮询转换作业状态。
通过使用事务来维护 Firestore 中的新文件列表,可帮助确保在工作流将这些文件导入 BigQuery 中时不会丢失任何文件。通过将作业元数据和状态存储在 Firestore 中,可以使得工作流的单独运行具有幂等性。
目标
- 创建 Firestore 数据库。
- 设置一个 Cloud Run 函数触发器,以跟踪添加到 Cloud Storage 存储桶区内 Firestore 中的文件。
- 部署 Cloud Run 函数以运行和监控 BigQuery 作业。
- 部署并运行工作流以自动执行此过程。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用情况来估算费用,请使用价格计算器。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
-
在 Google Cloud 控制台的项目选择器页面上,选择或创建 Google Cloud 项目。
选择或创建项目所需的角色
- 选择项目:选择项目不需要特定的 IAM 角色,您可以选择已获授角色的任何项目。
-
创建项目:如需创建项目,您需要拥有 Project Creator 角色 (
roles/resourcemanager.projectCreator),该角色包含resourcemanager.projects.create权限。了解如何授予角色。
-
启用 Cloud Build API、Cloud Run functions API、Identity and Access Management API、Resource Manager API 和 Workflows API。
启用 API 所需的角色
如需启用 API,您需要拥有 Service Usage Admin IAM 角色 (
roles/serviceusage.serviceUsageAdmin),该角色包含serviceusage.services.enable权限。了解如何授予角色。 前往欢迎页面,记下项目 ID 以用于后续步骤。
在 Google Cloud 控制台中,激活 Cloud Shell。
准备环境
若要准备环境,请创建 Firestore 数据库,从 GitHub 代码库克隆代码示例,使用 Terraform 创建资源,修改工作流 YAML 文件,并安装文件生成器的要求。
如需创建 Firestore 数据库,请执行以下操作:
在 Google Cloud 控制台中,前往 Firestore 页面。
点击选择原生模式。
在选择位置菜单中,选择要托管 Firestore 数据库的区域。我们建议选择靠近您的物理位置的区域。
点击创建数据库。
在 Cloud Shell 中,克隆源代码库:
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-load在 Cloud Shell 中,使用 Terraform 创建以下资源:
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve替换以下内容:
PROJECT_ID:您的 Google Cloud 项目 IDREGION:用于托管资源的特定 Google Cloud地理位置,例如us-central1ZONE:用于托管资源的区域内的位置,例如us-central1-b
您应该会看到如下所示的消息:
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Terraform 可帮助您以可预测的方式安全地大规模创建、更改和升级基础架构。系统会在您的项目中创建以下资源:
- 具有必需权限的服务账号,用于确保安全访问您的资源。
- 名为
serverless_elt_dataset的 BigQuery 数据集和名为word_count的表,用于加载传入的文件。 - 名为
${project_id}-ordersbucket的 Cloud Storage 存储分区,用于暂存输入文件。 - 以下五个 Cloud Run 函数:
file_add_handler用于将添加到 Cloud Storage 存储分区的文件的名称添加到 Firestore 集合。create_job用于创建一个新的 BigQuery 加载作业,并将 Firebase 集合中的文件与该作业相关联。create_query用于创建一个新的 BigQuery 查询作业。poll_bigquery_job用于获取 BigQuery 作业的状态。run_bigquery_job用于启动 BigQuery 作业。
获取您在上一步中部署的
create_job、create_query、poll_job、run_bigquery_jobCloud Run 函数的网址。gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
输出类似于以下内容:
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
请记下这些网址,因为在部署工作流时需要用到它们。
创建和部署工作流
在 Cloud Shell 中,打开工作流的源文件
workflow.yaml:替换以下内容:
CREATE_JOB_URL:用于创建新作业的函数的网址POLL_BIGQUERY_JOB_URL:用于轮询运行中作业状态的函数的网址RUN_BIGQUERY_JOB_URL:用于启动 BigQuery 加载作业的函数的网址CREATE_QUERY_URL:用于启动 BigQuery 查询作业的函数的网址BQ_REGION:存储数据的 BigQuery 区域,例如USBQ_DATASET_TABLE_NAME:BigQuery 数据集表名称,格式为PROJECT_ID.serverless_elt_dataset.word_count
部署
workflow文件:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yaml替换以下内容:
WORKFLOW_NAME:工作流的唯一名称WORKFLOW_REGION:在其中部署此工作流的区域,例如us-central1WORKFLOW_DESCRIPTION:工作流的说明
创建 Python 3 虚拟环境并安装文件生成器的必备项目:
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
生成要导入的文件
gen.py Python 脚本会生成 Avro 格式的随机内容。架构与 BigQuery word_count 表相同。这些 Avro 文件会复制到指定的 Cloud Storage 存储桶中。
在 Cloud Shell 中,生成以下文件:
python gen.py -p PROJECT_ID \
-o PROJECT_ID-ordersbucket \
-n RECORDS_PER_FILE \
-f NUM_FILES \
-x FILE_PREFIX
替换以下内容:
RECORDS_PER_FILE:单个文件中的记录数NUM_FILES:要上传的文件总数FILE_PREFIX:已生成文件的名称的前缀
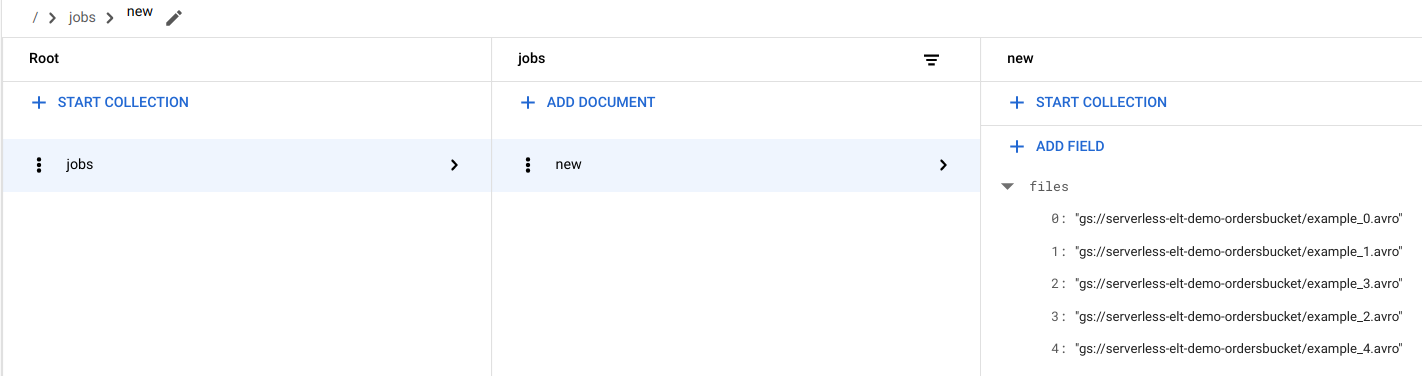
查看 Firestore 中的文件条目
将文件复制到 Cloud Storage 时,会触发 handle_new_file Cloud Run 函数。该函数会将文件列表添加到 Firestore jobs 集合的 new 文档的文件列表数组中。
如需查看文件列表,请在 Google Cloud 控制台中前往 Firestore 数据页面。
触发工作流
Workflows 将一系列无服务器任务与Google Cloud 和 API 服务相关联。此工作流中的各个步骤以 Cloud Run 函数的形式运行,并且状态存储在 Firestore 中。所有对 Cloud Run functions 的调用都使用工作流的服务账号进行身份验证。
在 Cloud Shell 中,运行工作流:
gcloud workflows execute WORKFLOW_NAME
下图显示了在工作流中使用的步骤:

工作流分为两个部分:主工作流和子工作流。主工作流处理作业创建和有条件执行,子工作流执行 BigQuery 作业。工作流会执行以下操作:
create_jobCloud Run 函数会创建新的作业对象、获取从 Firestore 文档添加到 Cloud Storage 的文件列表并将这些文件与加载作业相关联。如果没有要加载的文件,函数将不会创建新作业。create_queryCloud Run 函数接受这样的查询:需要与应在其中执行查询的 BigQuery 区域一起执行的查询。该函数在 Firestore 中创建作业并返回作业 ID。run_bigquery_jobCloud Run 函数获取需要执行的作业的 ID,然后调用 BigQuery API 来提交作业。- 您可以定期轮询作业状态,而不是等待 Cloud Run 函数中的作业完成。
查看作业状态
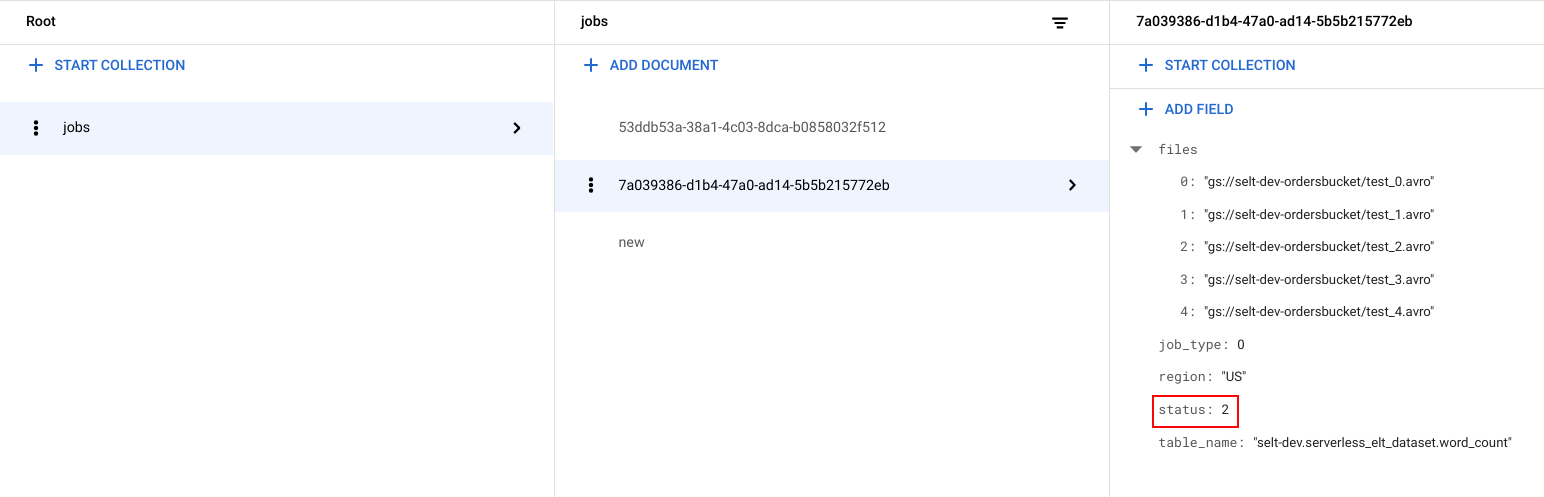
您可以查看文件列表和作业状态。
在Google Cloud 控制台中,前往 Firestore 数据页面。
系统会为每个作业生成一个唯一标识符 (UUID)。如需查看
job_type和status,请点击作业 ID。每个作业可能具有以下类型之一和状态:job_type:工作流正在运行的作业的类型,值为以下值之一:- 0:将数据加载到 BigQuery 中。
- 1:在 BigQuery 中运行查询。
status:作业的当前状态,值为以下值之一:- 0:作业已创建,但尚未开始。
- 1:作业正在运行。
- 2:作业已成功完成其执行。
- 3:出现错误,作业未成功完成。
作业对象还包含元数据属性,例如 BigQuery 数据集所在的区域、BigQuery 表的名称以及正在运行的查询字符串(如果作业是查询作业的话)。
在 BigQuery 中查看数据
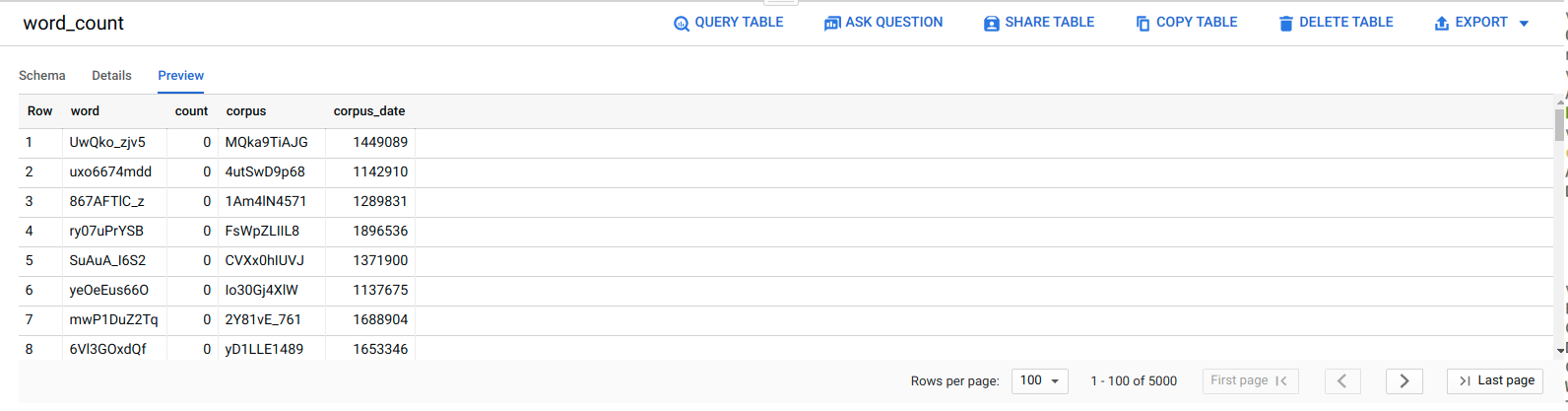
如需确认 ELT 作业是否成功,请验证数据是否显示在表中。
在 Google Cloud 控制台中,前往 BigQuery 编辑器页面。
点击
serverless_elt_dataset.word_count表。点击预览标签页。
安排工作流
如需定期按计划运行工作流,您可以使用 Cloud Scheduler。
清理
为了避免产生费用,最简单的方法是删除您为本教程创建的 Google Cloud 项目。或者,您也可以删除各个资源。逐个删除资源
在 Cloud Shell 中,移除使用 Terraform 创建的所有资源:
cd $HOME/bigquery-workflows-load terraform destroy \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve
在 Google Cloud 控制台中,前往 Firestore 数据页面。
在作业旁边,点击 菜单,然后选择删除。
删除项目
- 在 Google Cloud 控制台中,前往管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
后续步骤
- 如需详细了解 BigQuery,请参阅 BigQuery 文档。
- 了解如何构建无服务器自定义机器学习流水线。
- 如需查看更多参考架构、图表和最佳实践,请浏览云架构中心。