
Ao adicionar um conector do BigQuery ao app do Gemini Enterprise Agent Platform Vision, todas as saídas do modelo de app conectado serão ingeridas na tabela de destino.
Você pode criar sua própria tabela do BigQuery e especificar essa tabela ao adicionar um conector do BigQuery ao app ou permitir que a plataforma do app do Gemini Enterprise Agent Platform Vision crie a tabela automaticamente.
Criação automática de tabelas
Se você permitir que a plataforma do app do Gemini Enterprise Agent Platform Vision crie a tabela automaticamente, poderá especificar essa opção ao adicionar o nó do conector do BigQuery.
As seguintes condições de conjunto de dados e tabela serão aplicadas se você quiser usar a criação automática de tabelas:
- Conjunto de dados: o nome do conjunto de dados criado automaticamente é
visionai_dataset. - Tabela: o nome da tabela criada automaticamente é
visionai_dataset.APPLICATION_ID. Tratamento de erros:
- Se a tabela com o mesmo nome no mesmo conjunto de dados existir, nenhuma criação automática será realizada.
Console
Abra a guia Aplicativos do painel do Gemini Enterprise Agent Platform Vision.
Selecione Ver app ao lado do nome do aplicativo na lista.
Na página do criador de aplicativos, selecione BigQuery na seção Conectores.
Deixe o campo Caminho do BigQuery vazio.
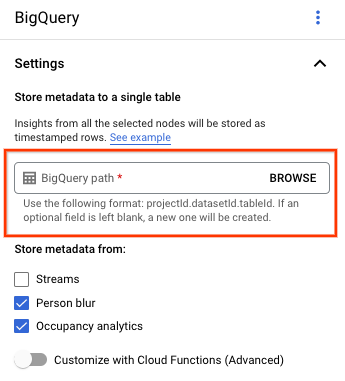
Mude outras configurações.
REST e LINHA DE CMD
Para permitir que a plataforma do app infira um esquema de tabela, use o
createDefaultTableIfNotExists campo do BigQueryConfig
ao criar ou atualizar um app.
Criar e especificar uma tabela manualmente
Se você quiser gerenciar a tabela de saída manualmente, ela precisará ter o esquema necessário como um subconjunto do esquema da tabela.
Se a tabela atual tiver esquemas incompatíveis, a implantação será rejeitada.
Usar o esquema padrão
Se você usar o esquema padrão para tabelas de saída de modelo, verifique se a tabela contém apenas as seguintes colunas obrigatórias. É possível copiar diretamente o texto do esquema a seguir ao criar a tabela do BigQuery. Para mais informações detalhadas sobre como criar uma tabela do BigQuery, consulte Criar e usar tabelas. Para mais informações sobre a especificação do esquema ao criar uma tabela, consulte Como especificar um esquema.
Use o texto a seguir para descrever o esquema ao criar uma tabela. Para
informações sobre como usar o tipo de coluna JSON
("type": "JSON"), consulte Como trabalhar com dados JSON no SQL padrão.
O tipo de coluna JSON é recomendado para consulta de anotação. Também é possível usar
"type" : "STRING".
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
Google Cloud Console do
No Google Cloud console, acesse a página BigQuery.
Selecione o projeto.
Selecione mais opções .
Clique em Criar tabela.
Na seção "Esquema", ative Editar como texto.

gcloud
O exemplo a seguir cria primeiro o arquivo JSON de solicitação e, em seguida, usa o
gcloud alpha bq tables create comando.
Primeiro, crie o arquivo JSON de solicitação:
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsonEnvie o comando
gcloud. Faça as seguintes substituições:TABLE_NAME: o ID da tabela ou o identificador totalmente qualificado da tabela.
DATASET: o ID do conjunto de dados do BigQuery.
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
Exemplo de linhas do BigQuery geradas por um app do Gemini Enterprise Agent Platform Vision:
| ingestion_time | aplicativo | instância | nó | anotação |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
Usar um esquema personalizado
Se o esquema padrão não funcionar para seu caso de uso, você poderá usar as funções do Cloud Run para gerar linhas do BigQuery com um esquema definido pelo usuário. Se você usar um esquema personalizado, não haverá pré-requisito para o esquema da tabela do BigQuery.
Gráfico de apps com o nó do BigQuery selecionado
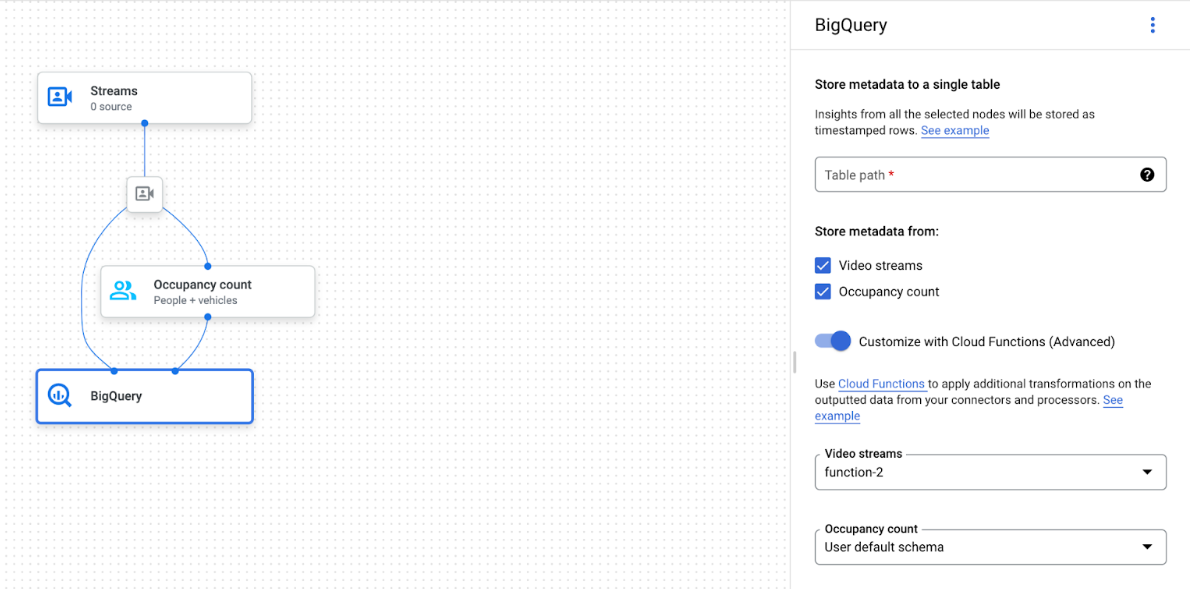
O conector do BigQuery pode ser conectado a qualquer modelo que gere anotação de vídeo ou baseada em proto:
- Para entrada de vídeo, o conector do BigQuery só extrai os dados de metadados armazenados no cabeçalho do stream e ingere esses dados no BigQuery como outras saídas de anotação de modelo. O vídeo em si não é armazenado.
- Se o stream não contiver metadados, nada será armazenado no BigQuery.
Consultar os dados da tabela
Com o esquema de tabela do BigQuery, é possível realizar uma análise avançada depois que a tabela é preenchida com dados.
Amostras de consultas
É possível usar as consultas de exemplo a seguir no BigQuery para receber insights dos modelos do Gemini Enterprise Agent Platform Vision.
Por exemplo, você pode usar o BigQuery para desenhar uma curva baseada em tempo para o número máximo de pessoas detectadas por minuto usando dados do modelo de detector de pessoas / veículos com a seguinte consulta:
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
Da mesma forma, é possível usar o BigQuery e o recurso de contagem de linhas de cruzamento do modelo de análise de ocupação para criar uma consulta que conte o número total de veículos que passam pela linha de cruzamento por minuto:
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
Execute a consulta
Depois de formatar a consulta SQL padrão do Google, você pode usar o console para executar a consulta:
Console
No Google Cloud console do, abra a página do BigQuery.
Selecione Expandir ao lado do nome do conjunto de dados e selecione o nome da tabela.
Na visualização de detalhes da tabela, clique em Escrever nova consulta.

Insira uma consulta SQL padrão do Google na área de texto do Editor de consultas. Para exemplos de consultas, consulte consultas de exemplo.
Opcional: para mudar o local de processamento de dados, clique em Editar > Configurações de consulta. Em Local de processamento, clique em Seleção automática e escolha o local dos dados. Por fim, clique em Salvar para atualizar as configurações da consulta.
Clique em Executar.
Isso cria um job de consulta que grava a saída em uma tabela temporária.
Integração de funções do Cloud Run
É possível usar as funções do Cloud Run para acionar o processamento de dados adicional com a ingestão personalizada do BigQuery. Para usar as funções do Cloud Run na ingestão personalizada do BigQuery, faça o seguinte:
Ao usar o Google Cloud console, selecione a função do Cloud correspondente no menu suspenso de cada modelo conectado.
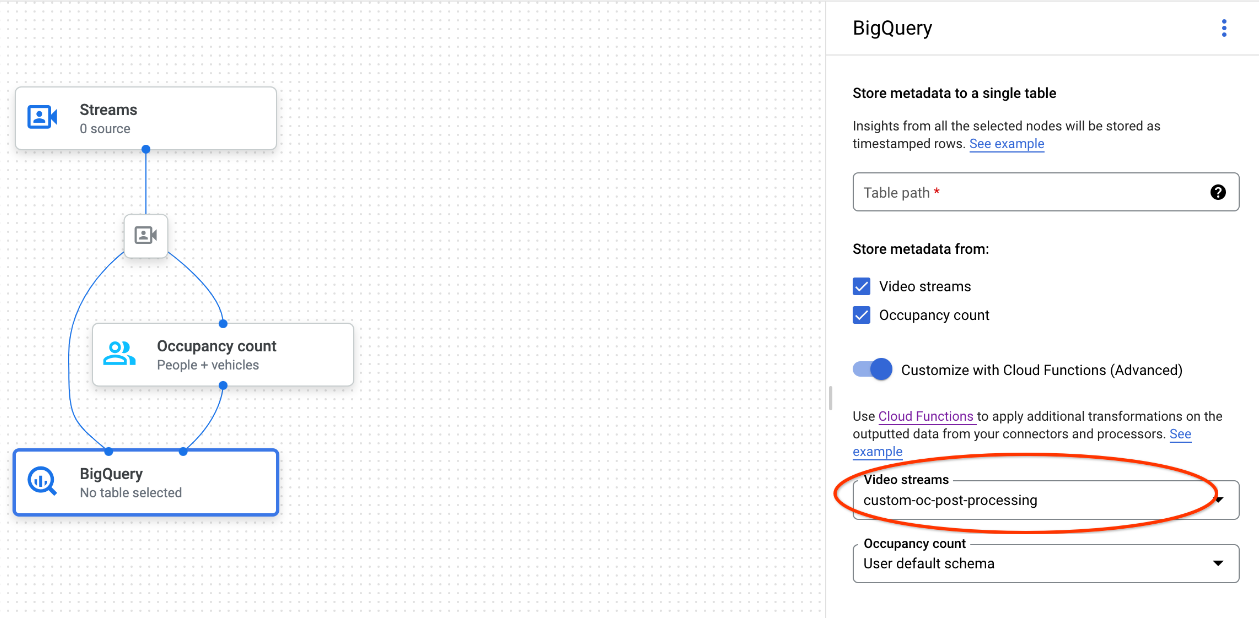
Ao usar a API Gemini Enterprise Agent Platform Vision, adicione um par de chave-valor ao
cloud_function_mappingcampo deBigQueryConfigno nó do BigQuery. A chave é o nome do nó do BigQuery e o valor é o acionador HTTP da função de destino.
Para usar as funções do Cloud Run com a ingestão personalizada do BigQuery, a função precisa atender aos seguintes requisitos:
- A instância das funções do Cloud Run precisa ser criada antes da criação do nó do BigQuery.
- A API Gemini Enterprise Agent Platform Vision espera receber an
AppendRowsRequestanotação retornada das funções do Cloud Run. - É necessário definir o campo
proto_rows.writer_schemapara todas asCloudFunctionrespostas.write_streampode ser ignorado.
Exemplo de integração de funções do Cloud Run
O exemplo a seguir mostra como analisar a saída do nó de contagem de ocupação (OccupancyCountPredictionResult) e extrair dela um esquema de tabela ingestion_time, person_count e vehicle_count.
O resultado do exemplo a seguir é uma tabela do BigQuery com o esquema:
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
Use o código a seguir para criar essa tabela:
Defina um proto (por exemplo,
test_table_schema.proto) para os campos da tabela que você quer gravar:syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }Compile o arquivo proto para gerar o arquivo Python do buffer de protocolo:
protoc -I=./ --python_out=./ ./test_table_schema.protoImporte o arquivo Python gerado e escreva a função do Cloud.
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
Para incluir suas dependências nas funções do Cloud Run, também é necessário fazer o upload do arquivo
test_table_schema_pb2.pygerado e especificarrequirements.txtsemelhante ao seguinte:functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2Implante a função do Cloud e defina o acionador HTTP correspondente no
BigQueryConfig.