
כשמוסיפים מחבר BigQuery לאפליקציית Gemini Enterprise Agent Platform Vision, כל הפלט של מודל האפליקציה המקושרת מוזן לטבלת היעד.
אתם יכולים ליצור טבלת BigQuery משלכם ולהגדיר את הטבלה הזו כשאתם מוסיפים מחבר BigQuery לאפליקציה, או לאפשר לפלטפורמת האפליקציות של Gemini Enterprise Agent Platform Vision ליצור את הטבלה באופן אוטומטי.
יצירת טבלה אוטומטית
אם מאפשרים לפלטפורמת האפליקציות של Gemini Enterprise Agent Platform Vision ליצור את הטבלה באופן אוטומטי, אפשר לציין את האפשרות הזו כשמוסיפים את צומת המחבר של BigQuery.
אם רוצים להשתמש ביצירת טבלה אוטומטית, צריך לעמוד בתנאים הבאים לגבי מערך הנתונים והטבלה:
- מערך נתונים: השם של מערך הנתונים שנוצר באופן אוטומטי הוא
visionai_dataset. - טבלה: שם הטבלה שנוצר באופן אוטומטי הוא
visionai_dataset.APPLICATION_ID. טיפול בשגיאות:
- אם קיימת טבלה עם אותו שם באותו מערך נתונים, לא מתבצעת יצירה אוטומטית.
המסוף
פותחים את הכרטיסייה Applications (אפליקציות) במרכז הבקרה של Gemini Enterprise Agent Platform Vision.
לוחצים על הצגת האפליקציה לצד שם האפליקציה ברשימה.
בדף של כלי בניית האפליקציות, בוחרים באפשרות BigQuery בקטע Connectors (מחברים).
משאירים את השדה BigQuery path (נתיב BigQuery) ריק.
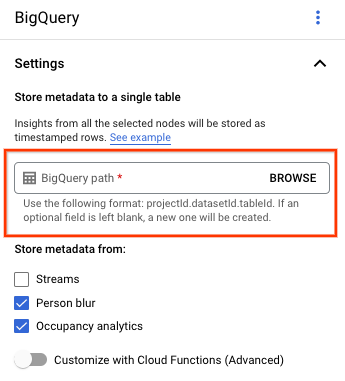
משנים הגדרות אחרות.
REST ושורת הפקודה
כדי לאפשר לפלטפורמת האפליקציות להסיק סכימת טבלה, משתמשים בשדה createDefaultTableIfNotExists של BigQueryConfig כשיוצרים או מעדכנים אפליקציה.
יצירה וציון של טבלה באופן ידני
אם רוצים לנהל את טבלת הפלט באופן ידני, הסכימה של הטבלה צריכה לכלול את הסכימה הנדרשת כקבוצת משנה.
אם לטבלה הקיימת יש סכימות לא תואמות, הפריסה נדחית.
שימוש בסכימה שמוגדרת כברירת מחדל
אם משתמשים בסכימה שמוגדרת כברירת מחדל לטבלאות של פלט המודל, צריך לוודא שהטבלה מכילה רק את עמודות החובה הבאות. כשיוצרים את הטבלה ב-BigQuery, אפשר להעתיק ישירות את הטקסט של הסכימה הבאה. מידע נוסף על יצירת טבלה ב-BigQuery זמין במאמר יצירה ושימוש בטבלאות. מידע נוסף על הגדרת סכימה כשיוצרים טבלה זמין במאמר הגדרת סכימה.
משתמשים בטקסט הבא כדי לתאר את הסכימה כשיוצרים טבלה. למידע על שימוש בסוג העמודה JSON ("type": "JSON"), אפשר לעיין במאמר עבודה עם נתוני JSON ב-SQL סטנדרטי.
מומלץ להשתמש בסוג העמודה JSON לשאילתת הערות. אפשר גם להשתמש ב-"type" : "STRING".
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
מסוף Google Cloud
במסוף Google Cloud , עוברים לדף BigQuery.
בוחרים את הפרויקט הרצוי.
לוחצים על סמל האפשרויות הנוספות .
לוחצים על יצירת טבלה.
בקטע Schema (סכימה), מפעילים את האפשרות Edit as text (עריכה כטקסט).
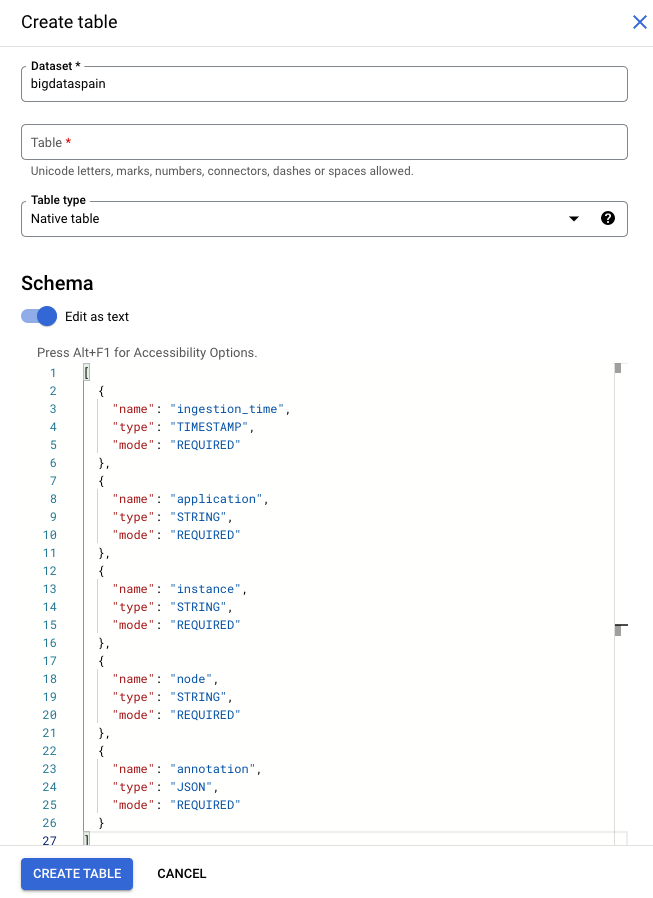
gcloud
בדוגמה הבאה, קודם יוצרים את קובץ ה-JSON של הבקשה, ואז משתמשים בפקודה gcloud alpha bq tables create.
קודם יוצרים את קובץ ה-JSON של הבקשה:
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsonשולחים את הפקודה
gcloud. מחליפים את הפרטים הבאים:TABLE_NAME: המזהה של הטבלה או מזהה מלא של הטבלה.
DATASET: המזהה של מערך הנתונים ב-BigQuery.
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
שורות לדוגמה ב-BigQuery שנוצרו על ידי אפליקציית Vision של Gemini Enterprise Agent Platform:
| ingestion_time | אפליקציה | מכונה | צומת | אנוטציה |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
שימוש בסכימה מותאמת אישית
אם סכימת ברירת המחדל לא מתאימה לתרחיש השימוש שלכם, אתם יכולים להשתמש בפונקציות של Cloud Run כדי ליצור שורות ב-BigQuery עם סכימה שהוגדרה על ידי המשתמש. אם אתם משתמשים בסכימה בהתאמה אישית, אין דרישה מוקדמת לסכימת הטבלה ב-BigQuery.
גרף האפליקציה עם הצומת BigQuery שנבחר
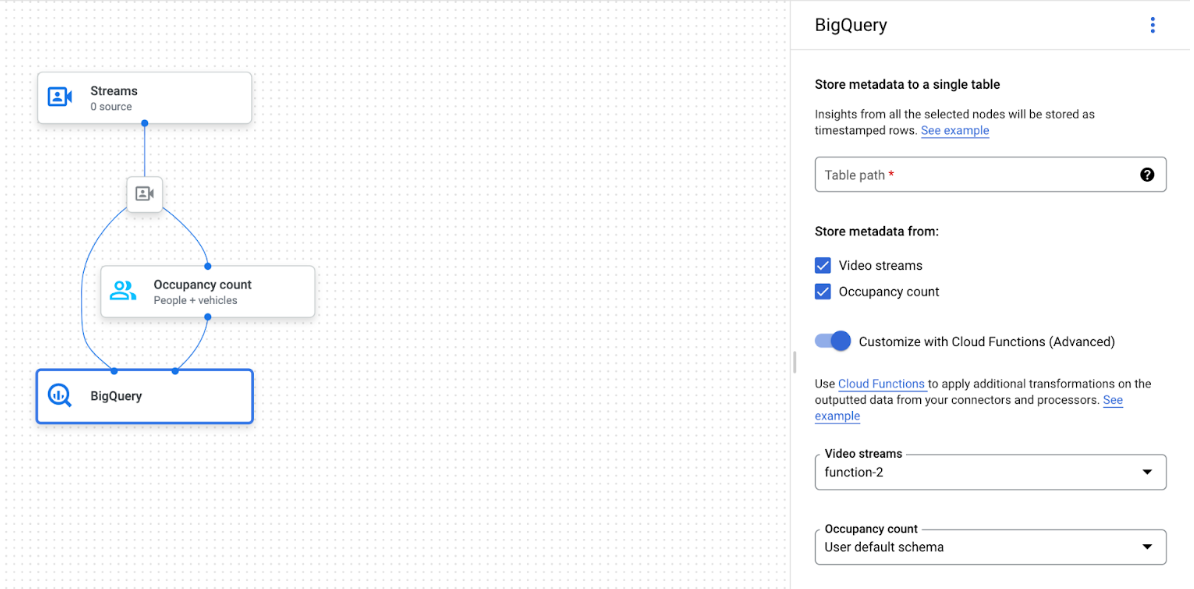
אפשר לחבר את המחבר של BigQuery לכל מודל שמפיק אנוטציה מבוססת וידאו או פרוטו:
- במקרה של קלט וידאו, מחבר BigQuery רק מחלץ את נתוני המטא-נתונים שמאוחסנים בכותרת של הזרם ומטמיע את הנתונים האלה ב-BigQuery כפלט של הערות של מודלים אחרים. הסרטון עצמו לא נשמר.
- אם הסטרימינג לא מכיל מטא-נתונים, לא יישמר כלום ב-BigQuery.
שאילתות על נתונים בטבלה
אחרי שהטבלה מאוכלסת בנתונים, אפשר לבצע ניתוח מתקדם באמצעות סכימת הטבלה ב-BigQuery שמוגדרת כברירת מחדל.
שאילתות לדוגמה
אתם יכולים להשתמש בדוגמאות הבאות לשאילתות ב-BigQuery כדי לקבל תובנות ממודלים של ראייה בפלטפורמת הסוכנים של Gemini Enterprise.
לדוגמה, אפשר להשתמש ב-BigQuery כדי ליצור עקומה מבוססת-זמן של המספר המקסימלי של אנשים שזוהו בדקה באמצעות נתונים ממודל לזיהוי אנשים או כלי רכב עם השאילתה הבאה:
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
באופן דומה, אתם יכולים להשתמש ב-BigQuery ובתכונה 'ספירת כלי רכב שחוצים את הקו' של מודל ניתוח התפוסה כדי ליצור שאילתה שסופרת את המספר הכולל של כלי הרכב שעוברים את הקו בכל דקה:
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
הרצת השאילתה
אחרי שמעצבים את שאילתת Google Standard SQL, אפשר להשתמש במסוף כדי להריץ את השאילתה:
המסוף
נכנסים לדף BigQuery במסוף Google Cloud .
לוחצים על הרחבה לצד שם מערך הנתונים, ובוחרים את שם הטבלה.
בתצוגת הפרטים של הטבלה, לוחצים על Compose new query.

מזינים שאילתת Google Standard SQL באזור הטקסט של Query editor. דוגמאות לשאילתות זמינות במאמר דוגמאות לשאילתות.
אופציונלי: כדי לשנות את המיקום של עיבוד הנתונים, לוחצים על עריכה > הגדרות שאילתה. בקטע מיקום העיבוד, לוחצים על בחירה אוטומטית ובוחרים את המיקום של הנתונים. לסיום, לוחצים על שמירה כדי לעדכן את הגדרות השאילתה.
לוחצים על Run.
הפעולה הזו יוצרת עבודת שאילתה שכותבת את הפלט לטבלה זמנית.
שילוב של פונקציות Cloud Run
אתם יכולים להשתמש בפונקציות של Cloud Run כדי להפעיל עיבוד נוסף של נתונים באמצעות הטמעה מותאמת אישית של BigQuery. כדי להשתמש בפונקציות של Cloud Run להטמעה מותאמת אישית ב-BigQuery:
כשמשתמשים במסוף Google Cloud , בוחרים את פונקציית הענן המתאימה מהתפריט הנפתח של כל מודל מקושר.
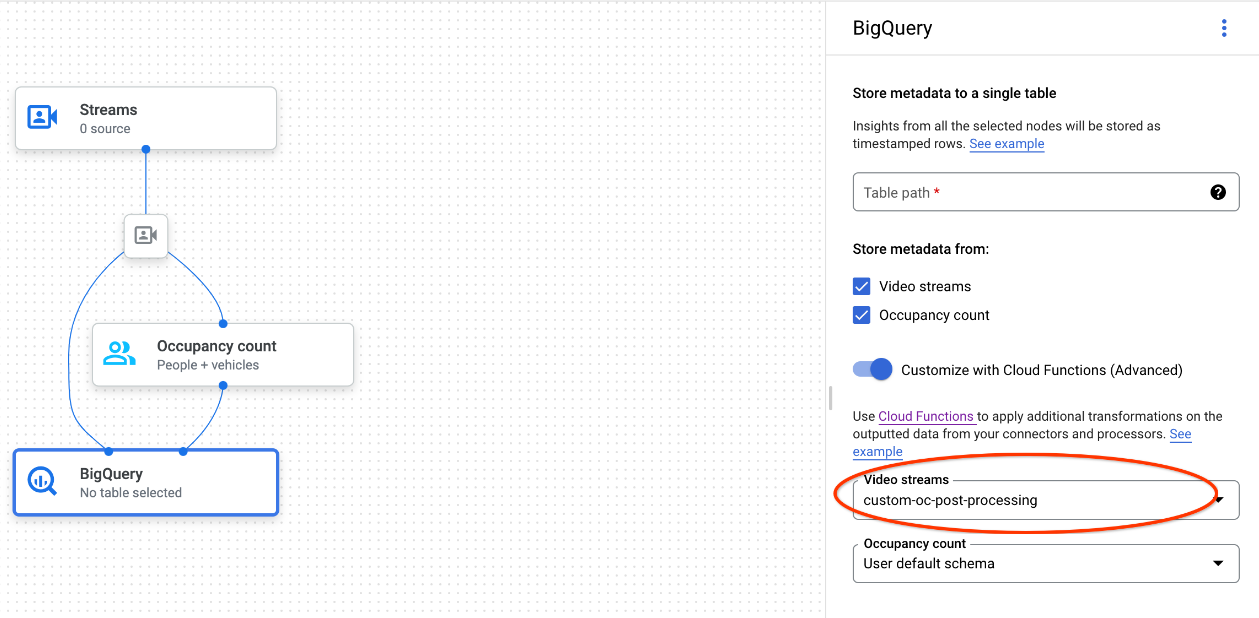
כשמשתמשים ב-Vision API של Gemini Enterprise Agent Platform, מוסיפים זוג אחד של מפתח/ערך לשדה
cloud_function_mappingשלBigQueryConfigבצומת BigQuery. המפתח הוא שם הצומת ב-BigQuery והערך הוא טריגר ה-HTTP של פונקציית היעד.
כדי להשתמש בפונקציות Cloud Run עם הטמעה מותאמת אישית של BigQuery, הפונקציה צריכה לעמוד בדרישות הבאות:
- צריך ליצור את מופע הפונקציות של Cloud Run לפני שיוצרים את צומת BigQuery.
- Gemini Enterprise Agent Platform Vision API מצפה לקבל הערה
AppendRowsRequestשמוחזרת מפונקציות Cloud Run. - חובה להגדיר את השדה
proto_rows.writer_schemaלכל התגובות מסוגCloudFunction. אפשר להתעלם מהשדהwrite_stream.
דוגמה לשילוב של פונקציות Cloud Run
בדוגמה הבאה מוצג ניתוח של פלט צומת של מספר המשתמשים (OccupancyCountPredictionResult), וחילוץ של סכימת טבלה ingestion_time, person_count ו-vehicle_count ממנו.
התוצאה של הדוגמה הבאה היא טבלה ב-BigQuery עם הסכימה:
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
כדי ליצור את הטבלה הזו, משתמשים בקוד הבא:
מגדירים קובץ proto (לדוגמה,
test_table_schema.proto) לשדות בטבלה שרוצים לכתוב:syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }קומפילציה של קובץ ה-proto כדי ליצור את קובץ ה-Python של מאגר אחסון לפרוטוקולים:
protoc -I=./ --python_out=./ ./test_table_schema.protoמייבאים את קובץ ה-Python שנוצר וכותבים את הפונקציה של Cloud Functions.
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
כדי לכלול את התלויות בפונקציות Cloud Run, צריך גם להעלות את קובץ
test_table_schema_pb2.pyשנוצר ולציין אתrequirements.txtבאופן דומה לזה:functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2פורסים את הפונקציה של Cloud Functions ומגדירים את טריגר ה-HTTP המתאים ב-
BigQueryConfig.