
Lorsque vous ajoutez un connecteur BigQuery à votre application Gemini Enterprise Agent Platform Vision, toutes les sorties du modèle d'application connectée sont ingérées dans la table cible.
Vous pouvez créer votre propre table BigQuery et la spécifier lorsque vous ajoutez un connecteur BigQuery à l'application, ou laisser la plate-forme d'applications Gemini Enterprise Agent Platform Vision créer automatiquement la table.
Création automatique de tables
Si vous laissez la plate-forme d'application Gemini Enterprise Agent Platform Vision créer automatiquement la table, vous pouvez spécifier cette option lorsque vous ajoutez le nœud du connecteur BigQuery.
Les conditions suivantes s'appliquent aux ensembles de données et aux tables si vous souhaitez utiliser la création automatique de tables :
- Ensemble de données : le nom de l'ensemble de données créé automatiquement est
visionai_dataset. - Table : le nom de la table créée automatiquement est
visionai_dataset.APPLICATION_ID. Gestion des exceptions :
- Si une table portant le même nom existe déjà dans le même ensemble de données, aucune création automatique n'a lieu.
Console
Ouvrez l'onglet Applications du tableau de bord Vision de Gemini Enterprise Agent Platform.
Sélectionnez Afficher l'application à côté du nom de votre application dans la liste.
Sur la page du générateur d'applications, sélectionnez BigQuery dans la section Connecteurs.
Laissez le champ Chemin d'accès BigQuery vide.

Modifiez tous les autres paramètres.
API REST et ligne de commande
Pour permettre à la plate-forme d'applications d'inférer un schéma de table, utilisez le champ createDefaultTableIfNotExists de BigQueryConfig lorsque vous créez ou mettez à jour une application.
Créer et spécifier manuellement une table
Si vous souhaitez gérer manuellement votre table de sortie, celle-ci doit avoir le schéma requis comme sous-ensemble du schéma de la table.
Si la table existante présente des schémas incompatibles, le déploiement est refusé.
Utiliser le schéma par défaut
Si vous utilisez le schéma par défaut pour les tables de sortie de modèle, assurez-vous que votre table ne contient que les colonnes requises suivantes. Vous pouvez copier directement le texte du schéma suivant lorsque vous créez la table BigQuery. Pour en savoir plus sur la création d'une table BigQuery, consultez Créer et utiliser des tables. Pour en savoir plus sur la spécification d'un schéma lorsque vous créez une table, consultez Spécifier un schéma.
Utilisez le texte suivant pour décrire le schéma lorsque vous créez une table. Pour en savoir plus sur l'utilisation du type de colonne JSON ("type": "JSON"), consultez Utiliser des données JSON en langage SQL standard.
Le type de colonne JSON est recommandé pour les requêtes d'annotation. Vous pouvez également utiliser "type" : "STRING".
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
Console Google Cloud
Dans la console Google Cloud , accédez à la page BigQuery.
Sélectionnez votre projet.
Sélectionnez Plus d'options .
Cliquez sur Créer une table.
Dans la section "Schéma", activez Modifier sous forme de texte.

gcloud
L'exemple suivant crée d'abord le fichier JSON de la requête, puis utilise la commande gcloud alpha bq tables create.
Commencez par créer le fichier JSON de la requête :
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsonEnvoyez la commande
gcloud. Effectuez les remplacements suivants :TABLE_NAME : ID de la table ou identifiant complet de la table.
DATASET : ID de l'ensemble de données BigQuery.
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
Exemple de lignes BigQuery générées par une application Vision Gemini Enterprise Agent Platform :
| ingestion_time | application | instance | nœud | annotation |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
Utiliser un schéma personnalisé
Si le schéma par défaut ne convient pas à votre cas d'utilisation, vous pouvez utiliser les fonctions Cloud Run pour générer des lignes BigQuery avec un schéma défini par l'utilisateur. Si vous utilisez un schéma personnalisé, il n'y a pas de condition préalable pour le schéma de table BigQuery.
Graphique d'application avec le nœud BigQuery sélectionné

Le connecteur BigQuery peut être associé à n'importe quel modèle qui génère des annotations vidéo ou basées sur des fichiers proto :
- Pour les entrées vidéo, le connecteur BigQuery n'extrait que les métadonnées stockées dans l'en-tête du flux et les ingère dans BigQuery comme les autres sorties d'annotation de modèle. La vidéo elle-même n'est pas stockée.
- Si votre flux ne contient aucune métadonnée, rien ne sera stocké dans BigQuery.
Interroger les données de la table
Avec le schéma de table BigQuery par défaut, vous pouvez effectuer des analyses puissantes une fois la table remplie de données.
Exemples de requêtes
Vous pouvez utiliser les exemples de requêtes suivants dans BigQuery pour obtenir des insights à partir des modèles Vision de Gemini Enterprise Agent Platform.
Par exemple, vous pouvez utiliser BigQuery pour tracer une courbe temporelle du nombre maximal de personnes détectées par minute à l'aide des données du modèle de détection des personnes / véhicules avec la requête suivante :
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
De même, vous pouvez utiliser BigQuery et la fonctionnalité de comptage des lignes de croisement du modèle d'analyse de l'occupation pour créer une requête qui compte le nombre total de véhicules qui franchissent la ligne de croisement par minute :
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
Exécuter votre requête
Après avoir mis en forme votre requête SQL standard Google, vous pouvez l'exécuter à l'aide de la console :
Console
Dans la console Google Cloud , ouvrez la page "BigQuery".
Sélectionnez Développer à côté du nom de votre ensemble de données, puis sélectionnez le nom de votre table.
Dans la vue détaillée de la table, cliquez surSaisir une nouvelle requête.

Saisissez une requête SQL standard de Google dans la zone de texte de l'éditeur de requête. Pour obtenir des exemples de requêtes, consultez Exemples de requêtes.
Facultatif : Pour modifier l'emplacement de traitement des données, cliquez sur Modifier > Paramètres de requête. Dans le champ Emplacement de traitement, cliquez sur Sélection automatique et choisissez l'emplacement de vos données. Cliquez ensuite sur Enregistrer pour mettre à jour les paramètres de la requête.
Cliquez sur Run (Exécuter).
Cette action crée une tâche de requête qui écrit les résultats dans une table temporaire.
Intégration de Cloud Run Functions
Vous pouvez utiliser des fonctions Cloud Run pour déclencher un traitement de données supplémentaire avec votre ingestion BigQuery personnalisée. Pour utiliser les fonctions Cloud Run pour votre ingestion BigQuery personnalisée, procédez comme suit :
Lorsque vous utilisez la console Google Cloud , sélectionnez la fonction cloud correspondante dans le menu déroulant de chaque modèle connecté.
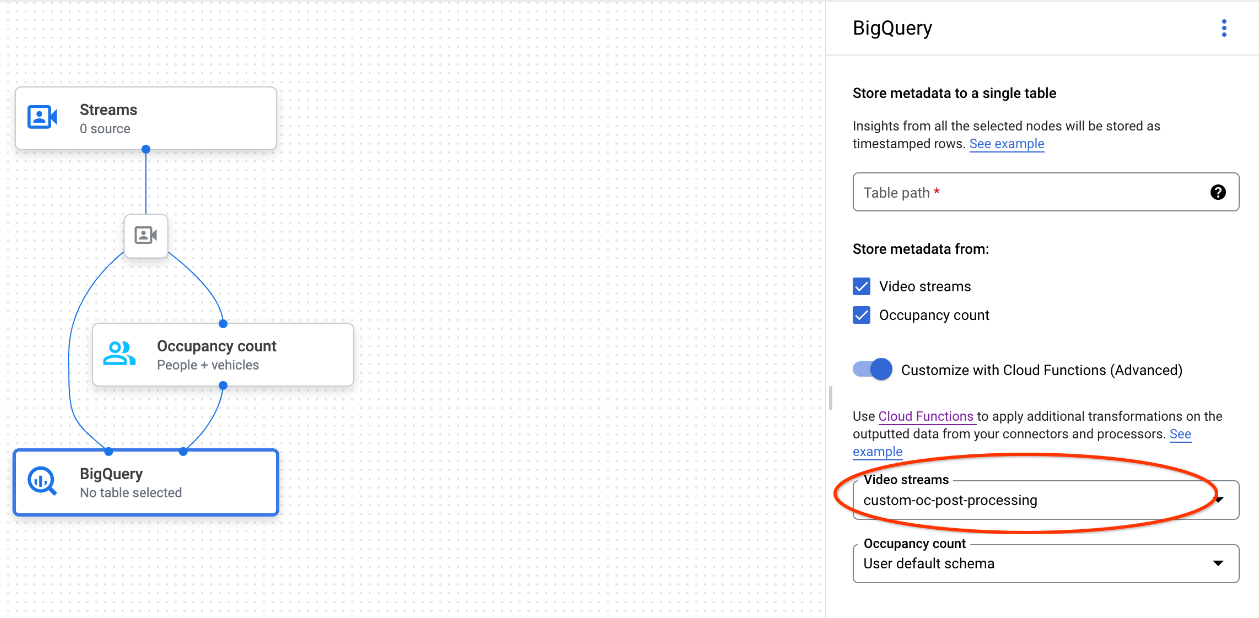
Lorsque vous utilisez l'API Vision de la plate-forme d'agents Gemini Enterprise, ajoutez une paire clé-valeur au champ
cloud_function_mappingdeBigQueryConfigdans le nœud BigQuery. La clé correspond au nom du nœud BigQuery et la valeur au déclencheur HTTP de la fonction cible.
Pour utiliser les fonctions Cloud Run avec votre ingestion BigQuery personnalisée, la fonction doit répondre aux exigences suivantes :
- L'instance Cloud Run Functions doit être créée avant le nœud BigQuery.
- L'API Vision de Gemini Enterprise Agent Platform s'attend à recevoir une annotation
AppendRowsRequestrenvoyée par les fonctions Cloud Run. - Vous devez définir le champ
proto_rows.writer_schemapour toutes les réponsesCloudFunction.write_streampeut être ignoré.
Exemple d'intégration de Cloud Run Functions
L'exemple suivant montre comment analyser la sortie du nœud de nombre d'occupants (OccupancyCountPredictionResult) et en extraire un schéma de table ingestion_time, person_count et vehicle_count.
L'exemple suivant génère une table BigQuery avec le schéma suivant :
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
Utilisez le code suivant pour créer ce tableau :
Définissez un fichier .proto (par exemple,
test_table_schema.proto) pour les champs de table que vous souhaitez écrire :syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }Compilez le fichier .proto pour générer le fichier Python du tampon de protocole :
protoc -I=./ --python_out=./ ./test_table_schema.protoImportez le fichier Python généré et écrivez la fonction cloud.
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
Pour inclure vos dépendances dans Cloud Run Functions, vous devez également importer le fichier
test_table_schema_pb2.pygénéré et spécifierrequirements.txtcomme suit :functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2Déployez la fonction cloud et définissez le déclencheur HTTP correspondant dans
BigQueryConfig.