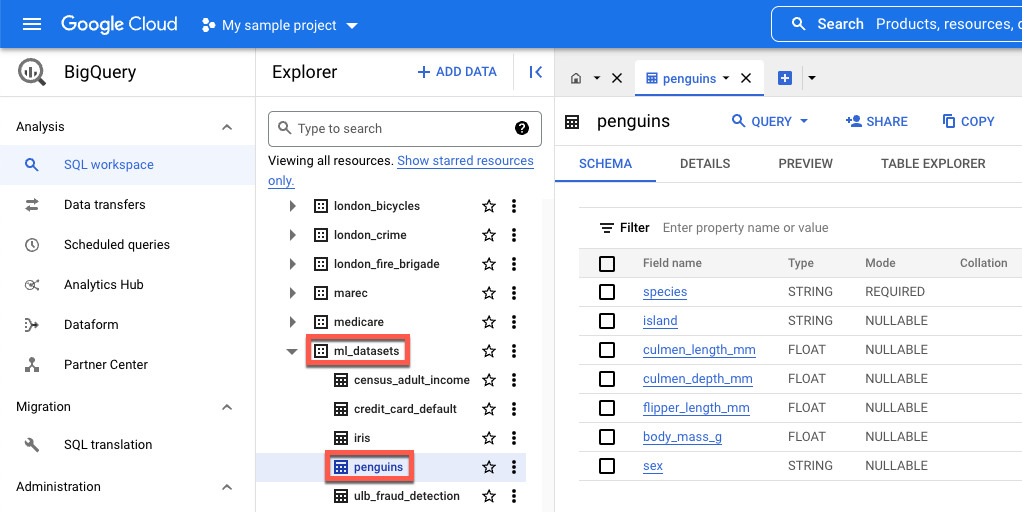
island- A ilha onde se encontra uma espécie de pinguim.culmen_length_mm– O comprimento da crista ao longo da parte superior do bico de um pinguim.culmen_depth_mm– A altura do bico de um pinguim.flipper_length_mm- O comprimento da asa semelhante a uma barbatana de um pinguim.body_mass_g- A massa do corpo de um pinguim.sex- O sexo do pinguim.
Transfira, pré-processe e divida os dados
Nesta secção, transfere o conjunto de dados do BigQuery disponível publicamente e prepara os respetivos dados. Para preparar os dados, faça o seguinte:
Converter caraterísticas de categoria (caraterísticas descritas com uma string em vez de um número) em dados numéricos. Por exemplo, converte os nomes dos três tipos de pinguins nos valores numéricos
0,1e2.Remova todas as colunas no conjunto de dados que não são usadas.
Remova todas as linhas que não podem ser usadas.
Divida os dados em dois conjuntos de dados distintos. Cada conjunto de dados é armazenado num objeto pandas
DataFrame.O
df_trainDataFramecontém dados usados para preparar o modelo.O
df_for_predictionDataFramecontém dados usados para gerar previsões.
Após o processamento dos dados, o código mapeia os valores numéricos das três colunas categóricas para os respetivos valores de string e, em seguida, imprime-os para que possa ver o aspeto dos dados.
Para transferir e processar os seus dados, execute o seguinte código no bloco de notas:
import numpy as np
import pandas as pd
LABEL_COLUMN = "species"
# Define the BigQuery source dataset
BQ_SOURCE = "bigquery-public-data.ml_datasets.penguins"
# Define NA values
NA_VALUES = ["NA", "."]
# Download a table
table = bq_client.get_table(BQ_SOURCE)
df = bq_client.list_rows(table).to_dataframe()
# Drop unusable rows
df = df.replace(to_replace=NA_VALUES, value=np.NaN).dropna()
# Convert categorical columns to numeric
df["island"], island_values = pd.factorize(df["island"])
df["species"], species_values = pd.factorize(df["species"])
df["sex"], sex_values = pd.factorize(df["sex"])
# Split into a training and holdout dataset
df_train = df.sample(frac=0.8, random_state=100)
df_for_prediction = df[~df.index.isin(df_train.index)]
# Map numeric values to string values
index_to_island = dict(enumerate(island_values))
index_to_species = dict(enumerate(species_values))
index_to_sex = dict(enumerate(sex_values))
# View the mapped island, species, and sex data
print(index_to_island)
print(index_to_species)
print(index_to_sex)
Seguem-se os valores mapeados impressos para características que não são numéricas:
{0: 'Dream', 1: 'Biscoe', 2: 'Torgersen'}
{0: 'Adelie Penguin (Pygoscelis adeliae)', 1: 'Chinstrap penguin (Pygoscelis antarctica)', 2: 'Gentoo penguin (Pygoscelis papua)'}
{0: 'FEMALE', 1: 'MALE'}
Os primeiros três valores são as ilhas que um pinguim pode habitar. Os segundos três valores são importantes porque são mapeados para as previsões que recebe no final deste tutorial. A terceira linha mostra o género FEMALE mapeado para 0 e o género MALE mapeado para 1.
Crie um conjunto de dados tabulares para preparar o modelo
No passo anterior, transferiu e processou os seus dados. Neste passo, vai
carregar os dados armazenados no seu df_train DataFrame para um conjunto de dados do BigQuery. Em seguida, usa o conjunto de dados do BigQuery para criar um conjunto de dados tabular do Vertex AI. Este conjunto de dados tabular é usado para preparar o seu modelo. Para mais informações, consulte o artigo Use conjuntos de dados geridos.
Crie um conjunto de dados do BigQuery
Para criar o conjunto de dados do BigQuery usado para criar um conjunto de dados do Vertex AI, execute o seguinte código. O comando create_dataset devolve um novo DataSet do BigQuery.
# Create a BigQuery dataset
bq_dataset_id = f"{project_id}.dataset_id_unique"
bq_dataset = bigquery.Dataset(bq_dataset_id)
bq_client.create_dataset(bq_dataset, exists_ok=True)
Crie um conjunto de dados tabulares do Vertex AI
Para converter o seu conjunto de dados do BigQuery num conjunto de dados tabular do Vertex AI, execute o seguinte código. Pode ignorar o aviso sobre o número necessário de linhas para fazer a preparação com dados tabulares. Uma vez que o objetivo deste tutorial é mostrar rapidamente como obter previsões, é usado um conjunto de dados relativamente pequeno para mostrar como gerar previsões. Num cenário do mundo real, quer, pelo menos, 1000 linhas num conjunto de dados tabulares. O comando
create_from_dataframe
devolve um Vertex AI
TabularDataset.
# Create a Vertex AI tabular dataset
dataset = aiplatform.TabularDataset.create_from_dataframe(
df_source=df_train,
staging_path=f"bq://{bq_dataset_id}.table-unique",
display_name="sample-penguins",
)
Agora, tem o conjunto de dados tabular do Vertex AI usado para preparar o seu modelo.
(Opcional) Veja o conjunto de dados público no BigQuery
Se quiser ver os dados públicos usados neste tutorial, pode abri-los no BigQuery.
Em Pesquisar no Google Cloud, introduza BigQuery e, de seguida, prima Enter.
Nos resultados da pesquisa, clique em BigQuery
Na janela do Explorador, expanda bigquery-public-data.
Em bigquery-public-data, expanda ml_datasets e, de seguida, clique em penguins.
Clique em qualquer um dos nomes em Nome do campo para ver os dados desse campo.