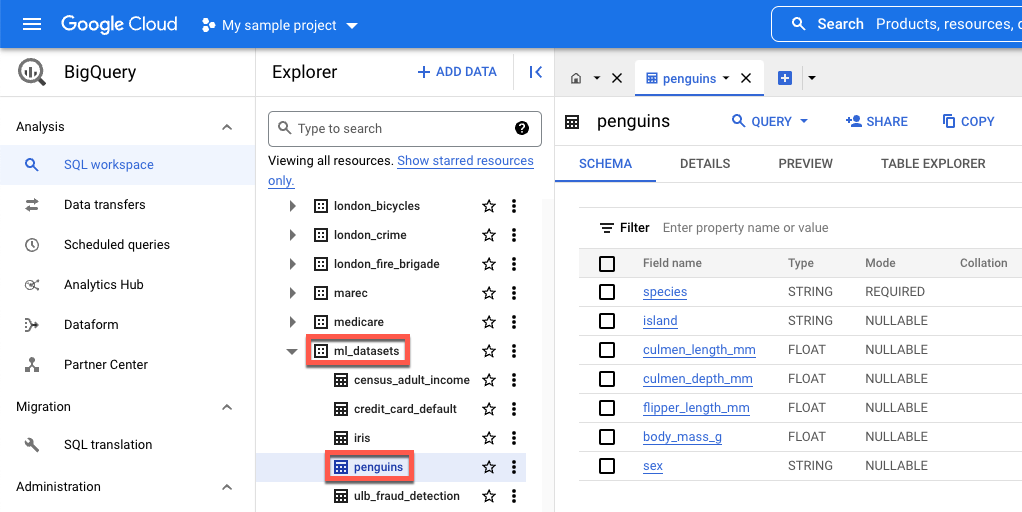
-
island– האי שבו נמצא מין של פינגווין. culmen_length_mm– האורך של הרכס לאורך החלק העליון של המקור של פינגווין.-
culmen_depth_mm– גובה המקור של פינגווין. -
flipper_length_mm– אורך הכנף דמוית הסנפיר של פינגווין. -
body_mass_g– מסת הגוף של פינגווין. -
sex– המין של הפינגווין.
הורדה, עיבוד מוקדם ופיצול של הנתונים
בקטע הזה, תורידו את מערך הנתונים שזמין לכולם ב-BigQuery ותכינו את הנתונים שלו. כדי להכין את הנתונים, פועלים לפי ההוראות הבאות:
המרת תכונות קטגוריות (תכונות שמתוארות באמצעות מחרוזת במקום מספר) לנתונים מספריים. לדוגמה, אתם ממירים את השמות של שלושת סוגי הפינגווינים לערכים המספריים
0,1ו-2.מסירים מהמערך עמודות שלא נמצאות בשימוש.
מסירים את כל השורות שלא ניתן להשתמש בהן.
פיצול הנתונים לשתי קבוצות נתונים נפרדות. כל קבוצת נתונים מאוחסנת באובייקט pandas
DataFrame.
df_trainDataFrameמכיל נתונים שמשמשים לאימון המודל.
df_for_predictionDataFrameמכיל נתונים שמשמשים ליצירת תחזיות.
אחרי עיבוד הנתונים, הקוד ממפה את הערכים המספריים של שלושת העמודות הקטגוריות לערכי המחרוזות שלהן, ואז מדפיס אותם כדי שתוכלו לראות איך הנתונים נראים.
כדי להוריד ולעבד את הנתונים, מריצים את הקוד הבא ב-notebook:
import numpy as np
import pandas as pd
LABEL_COLUMN = "species"
# Define the BigQuery source dataset
BQ_SOURCE = "bigquery-public-data.ml_datasets.penguins"
# Define NA values
NA_VALUES = ["NA", "."]
# Download a table
table = bq_client.get_table(BQ_SOURCE)
df = bq_client.list_rows(table).to_dataframe()
# Drop unusable rows
df = df.replace(to_replace=NA_VALUES, value=np.NaN).dropna()
# Convert categorical columns to numeric
df["island"], island_values = pd.factorize(df["island"])
df["species"], species_values = pd.factorize(df["species"])
df["sex"], sex_values = pd.factorize(df["sex"])
# Split into a training and holdout dataset
df_train = df.sample(frac=0.8, random_state=100)
df_for_prediction = df[~df.index.isin(df_train.index)]
# Map numeric values to string values
index_to_island = dict(enumerate(island_values))
index_to_species = dict(enumerate(species_values))
index_to_sex = dict(enumerate(sex_values))
# View the mapped island, species, and sex data
print(index_to_island)
print(index_to_species)
print(index_to_sex)
אלה הערכים הממופים המודפסים של מאפיינים לא מספריים:
{0: 'Dream', 1: 'Biscoe', 2: 'Torgersen'}
{0: 'Adelie Penguin (Pygoscelis adeliae)', 1: 'Chinstrap penguin (Pygoscelis antarctica)', 2: 'Gentoo penguin (Pygoscelis papua)'}
{0: 'FEMALE', 1: 'MALE'}
שלושת הערכים הראשונים הם האיים שבהם פינגווין עשוי להתגורר. שלושת הערכים הבאים חשובים כי הם משקפים את התחזיות שתקבלו בסוף המדריך הזה. בשורה השלישית מוצג המאפיין FEMALE שמתאים ל-0, והמאפיין MALE שמתאים ל-1.
יצירת מערך נתונים טבלאי לאימון המודל
בשלב הקודם הורדתם ועיבדתם את הנתונים. בשלב הזה, טוענים את הנתונים שמאוחסנים ב-df_train DataFrame למערך נתונים ב-BigQuery. לאחר מכן, משתמשים במערך הנתונים ב-BigQuery כדי ליצור מערך נתונים טבלאי ב-Vertex AI. מערך הנתונים הטבלאי הזה משמש לאימון המודל. מידע נוסף מופיע במאמר בנושא שימוש במערכי נתונים מנוהלים.
יצירת מערך נתונים ב-BigQuery
כדי ליצור את מערך הנתונים ב-BigQuery שמשמש ליצירת מערך נתונים ב-Vertex AI, מריצים את הקוד הבא. הפקודה create_dataset מחזירה DataSet חדש של BigQuery.
# Create a BigQuery dataset
bq_dataset_id = f"{project_id}.dataset_id_unique"
bq_dataset = bigquery.Dataset(bq_dataset_id)
bq_client.create_dataset(bq_dataset, exists_ok=True)
יצירת מערך נתונים טבלאי ב-Vertex AI
כדי להמיר את מערך הנתונים שלכם ב-BigQuery למערך נתונים טבלאי ב-Vertex AI, מריצים את הקוד הבא. אפשר להתעלם מהאזהרה לגבי מספר השורות הנדרש לאימון באמצעות נתונים טבלאיים. מטרת המדריך הזה היא להראות לכם במהירות איך לקבל תחזיות, ולכן נעשה בו שימוש במערך נתונים קטן יחסית כדי להדגים איך ליצור תחזיות. בתרחיש מהעולם האמיתי, כדאי שיהיו לפחות 1,000 שורות במערך נתונים טבלאי. הפקודה
create_from_dataframe
מחזירה TabularDataset של Vertex AI.
# Create a Vertex AI tabular dataset
dataset = aiplatform.TabularDataset.create_from_dataframe(
df_source=df_train,
staging_path=f"bq://{bq_dataset_id}.table-unique",
display_name="sample-penguins",
)
עכשיו יש לכם את מערך הנתונים הטבלאי של Vertex AI שמשמש לאימון המודל.
(אופציונלי) צפייה במערך הנתונים הציבורי ב-BigQuery
אם רוצים לראות את הנתונים הציבוריים שבהם נעשה שימוש במדריך הזה, אפשר לפתוח אותם ב-BigQuery.
בחיפוש ב- Google Cloud, מזינים BigQuery ואז מקישים על מקש Enter.
בתוצאות החיפוש, לוחצים על BigQuery.
בחלון Explorer, מרחיבים את bigquery-public-data.
בקטע bigquery-public-data, מרחיבים את ml_datasets ואז לוחצים על penguins.
כדי לראות את הנתונים של שדה מסוים, לוחצים על השם שלו בעמודה שם השדה.