
Verwenden Sie die Google Cloud Console, um die Leistung Ihres Modells zu prüfen. Analysieren Sie Testfehler, um die Modellqualität iterativ zu verbessern, indem Sie Datenprobleme beheben.
Diese Anleitung umfasst mehrere Seiten:
Dataset zur Bildklassifizierung erstellen und Bilder importieren
Modellleistung bewerten und analysieren
Modell auf einem Endpunkt bereitstellen und eine Vorhersage senden
Auf jeder Seite wird davon ausgegangen, dass Sie die Anleitung auf den vorherigen Seiten des Leitfadens bereits ausgeführt haben.
1. Ergebnisse der AutoML-Modellbewertung verstehen
Nach Abschluss des Trainings wird Ihr Modell automatisch anhand der Testdaten bewertet. Die entsprechenden Bewertungsergebnisse werden angezeigt, wenn Sie auf der Seite Model Registry oder Dataset auf den Namen des Modells klicken.
Dort finden Sie die Messwerte zur Messung der Modellleistung.
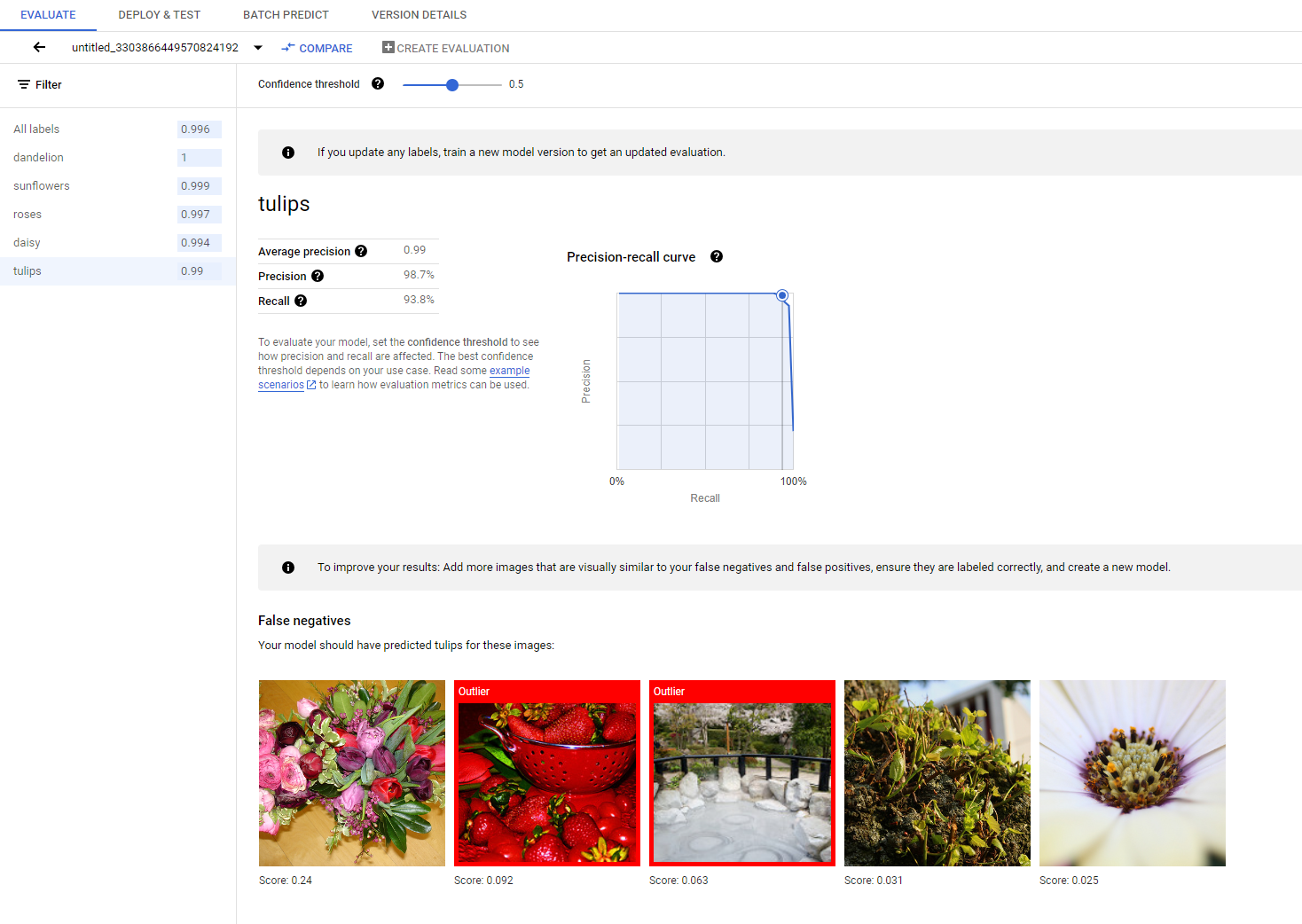
Eine detailliertere Einführung in die verschiedenen Bewertungsmetriken finden Sie im Abschnitt Modell bewerten, testen und bereitstellen.
2. Testergebnisse analysieren
Wenn Sie die Modellleistung weiter verbessern möchten, sollten Sie zuerst die Fehlerfälle untersuchen und die möglichen Ursachen ermitteln. Auf der Bewertungsseite jeder Klasse werden detaillierte Testbilder der jeweiligen Klasse angezeigt, die als falsch negative, falsch positive und richtig positive Ergebnisse kategorisiert sind. Die Definition der einzelnen Kategorien finden Sie im Abschnitt Modell bewerten, testen und bereitstellen.
Für jedes Bild in jeder Kategorie können Sie die Vorhersagedetails aufrufen, indem Sie auf das Bild klicken. Rechts auf der Seite wird der Bereich Ähnliche Bilder prüfen angezeigt. Dabei werden die ähnlichsten Stichproben aus dem Trainings-Dataset mit den im Merkmalsbereich gemessenen Entfernungen angezeigt.

Es gibt zwei Arten von Datenproblemen, die Sie beachten sollten:
Label-Inkonsistenz. Wenn ein visuell ähnliches Beispiel aus dem Trainings-Dataset andere Labels als das Testbeispiel hat, ist es möglich, dass eines davon falsch ist oder dass das mit dem geringfügige Unterschied mehr Daten benötigt, damit das Modell davon lernen kann, oder die aktuellen Klassenlabels sind nicht genau genug, um das angegebene Beispiel zu beschreiben. Durch die Überprüfung ähnlicher Bilder können Sie die Labelinformationen evtl. korrekt machen. Dazu korrigieren Sie entweder die Fehlerfälle oder schließen das problematische Beispiel aus dem Test-Dataset aus. Sie können das Label des Testbilds oder der Trainingsbilder ganz einfach im Bereich Ähnliche Bilder überprüfen auf derselben Seite ändern.
Ausreißer Wenn eine Testprobe als Ausreißer gekennzeichnet ist, sind möglicherweise keine visuell ähnlichen Proben im Trainings-Dataset vorhanden, mit denen das Modell trainiert werden kann. Wenn Sie ähnliche Bilder aus dem Trainings-Dataset überprüfen, können Sie diese Beispiele identifizieren und ähnliche Bilder in das Trainings-Dataset aufnehmen, um die Modellleistung in diesen Fällen weiter zu verbessern.
Nächste Schritte
Wenn Sie mit der Leistung des Modells zufrieden sind, folgen Sie der nächsten Seite dieser Anleitung, um Ihr trainiertes AutoML-Modell für einen Endpunkt bereitzustellen und ein Bild zur Vorhersage an das Modell zu senden. Wenn Sie Korrekturen an den Daten vornehmen, trainieren Sie ein neues Modell anhand des Tutorials AutoML-Bildklassifizierungsmodell trainieren.