
במסמך הזה מפורטת סקירה כללית על הצינור והרכיבים של AutoML מקצה לקצה. כדי ללמוד איך לאמן מודל באמצעות End-to-End AutoML, אפשר לעיין במאמר אימון מודל באמצעות End-to-End AutoML.
Tabular Workflow for End-to-End AutoML הוא צינור AutoML מלא למשימות סיווג ורגרסיה. הוא דומה ל-AutoML API, אבל מאפשר לכם לבחור מה לשלוט ומה להפוך לאוטומטי. במקום אמצעי בקרה לכל הצינור, יש אמצעי בקרה לכל שלב בצינור. אמצעי הבקרה של הצינור כוללים:
- פיצול נתונים
- Feature engineering
- חיפוש אדריכלות
- אימון המודל
- שילוב מודלים
- זיקוק מודלים
יתרונות
אלה כמה מהיתרונות של Tabular Workflow for End-to-End AutoML :
- תמיכה במערכי נתונים גדולים בגודל של כמה טרה-בייט ועד 1,000 עמודות.
- האפשרות הזו מאפשרת לכם לשפר את היציבות ולקצר את זמן האימון על ידי הגבלת מרחב החיפוש של סוגי הארכיטקטורה או דילוג על חיפוש הארכיטקטורה.
- האפשרות הזו מאפשרת לכם לשפר את מהירות האימון על ידי בחירה ידנית של החומרה שמשמשת לאימון ולחיפוש ארכיטקטורה.
- מאפשרת להקטין את גודל המודל ולשפר את זמן האחזור באמצעות זיקוק או שינוי גודל האנסמבל.
- אפשר לבדוק כל רכיב של AutoML בממשק גרפי רב-עוצמה של צינורות, שמאפשר לראות את טבלאות הנתונים שעברו טרנספורמציה, את ארכיטקטורות המודלים שנבדקו ועוד הרבה פרטים.
- כל רכיב AutoML מקבל גמישות ושקיפות מורחבות, כמו היכולת להתאים אישית פרמטרים, חומרה, להציג את סטטוס התהליך, יומנים ועוד.
AutoML מקצה לקצה ב-Vertex AI Pipelines
Tabular Workflow for End-to-End AutoML הוא מופע מנוהל של Vertex AI Pipelines.
Vertex AI Pipelines הוא שירות ללא שרתים שמריץ צינורות עיבוד נתונים של Kubeflow. אתם יכולים להשתמש בצינורות כדי להפוך לאוטומטיות את המשימות שלכם בלמידת מכונה ובהכנת נתונים, ולעקוב אחריהן. כל שלב בצינור העברת נתונים מבצע חלק מזרימת העבודה של צינור העברת הנתונים. לדוגמה, צינור יכול לכלול שלבים לפיצול נתונים, המרה של סוגי נתונים ואימון מודל. מכיוון ששלבים הם מופעים של רכיבי צינור עיבוד נתונים, יש להם קלט, פלט וקובץ אימג' של קונטיינר. אפשר להגדיר את קלט השלב מתוך הקלט של צינור העיבוד, או שהוא יכול להיות תלוי בפלט של שלבים אחרים בצינור העיבוד הזה. התלויות האלה מגדירות את תהליך העבודה של הצינור כגרף אציקלי מכוון.
סקירה כללית של צינורות ורכיבים
בתרשים הבא מוצג צינור עיבוד הנתונים של תהליך העבודה של נתונים טבלאיים ב-AutoML מקצה לקצה:

הרכיבים של צינור עיבוד הנתונים הם:
- feature-transform-engine: מבצע הנדסת פיצ'רים. פרטים נוספים זמינים במאמר בנושא Feature Transform Engine.
- split-materialized-data:
פיצול הנתונים המגובשים לקבוצת נתונים לאימון, לקבוצת הערכה ולקבוצת נתונים לבדיקה.
קלט:
- נתונים מהותיים
materialized_data.
פלט:
- חלוקת האימון שהתממשה
materialized_train_split. - פיצול חומרי הערכה
materialized_eval_split. - קבוצת נתונים לבדיקה
materialized_test_split.
- נתונים מהותיים
- merge-materialized-splits – מיזוג של פיצול ההערכה הממומש ופיצול האימון הממומש.
automl-tabular-stage-1-tuner – מבצע חיפוש של ארכיטקטורת מודל ומכוונן היפר-פרמטרים.
- ארכיטקטורה מוגדרת על ידי קבוצה של היפרפרמטרים.
- היפר-פרמטרים כוללים את סוג המודל ואת הפרמטרים של המודל.
- סוגי המודלים שנלקחים בחשבון הם רשתות נוירונים ועצים מחוזקים.
- המערכת מאמנת מודל לכל ארכיטקטורה שנבדקת.
automl-tabular-cv-trainer – מאמת את הארכיטקטורות באמצעות אימון מודלים על קפלים שונים של נתוני הקלט.
- הארכיטקטורות שנלקחות בחשבון הן אלה שנותנות את התוצאות הכי טובות בשלב הקודם.
- המערכת בוחרת כעשר ארכיטקטורות שהכי מתאימות. המספר המדויק מוגדר על ידי תקציב האימון.
automl-tabular-ensemble – יוצר מודל סופי על ידי שילוב של הארכיטקטורות הטובות ביותר.
- התרשים הבא ממחיש אימות צולב של K-fold עם bagging:
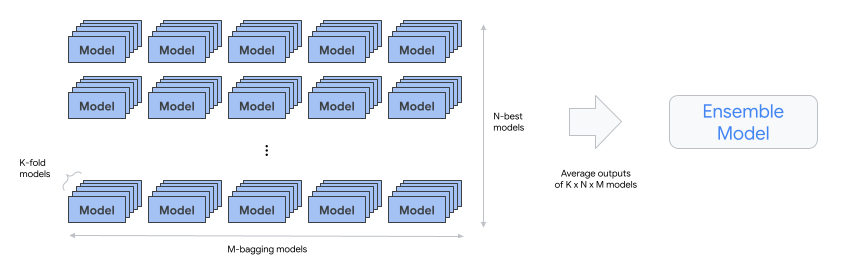
condition-is-distill – אופציונלי. יוצר גרסה קטנה יותר של מודל האנסמבל.
- מודל קטן יותר מקצר את זמן האחזור ומפחית את העלות של הסקת מסקנות.
automl-tabular-infra-validator – מאמת אם המודל שאומן הוא מודל תקין.
model-upload – העלאת המודל.
condition-is-evaluation – אופציונלי. משתמשים בקבוצת הנתונים לבדיקה כדי לחשב את מדדי ההערכה.