

Esta guía para principiantes es una introducción a la obtención de inferencias de modelos personalizados en Gemini Enterprise Agent Platform.
Objetivos de aprendizaje
Nivel de experiencia de Gemini Enterprise Agent Platform: Principiante
Tiempo de lectura estimado: 15 minutos
Qué aprenderás
- Beneficios de usar un servicio de inferencia administrado.
- Cómo funcionan las inferencias por lotes en Gemini Enterprise Agent Platform
- Cómo funcionan las inferencias en línea en Agent Platform
¿Por qué usar un servicio de inferencia administrado?
Imagina que tienes la tarea de crear un modelo que tome como entrada una imagen de una planta y prediga las especies. Para comenzar, puedes entrenar un modelo en un notebook y probar diferentes hiperparámetros y arquitecturas. Cuando tienes un modelo entrenado, puedes llamar al método predict en el framework de AA que elijas y probar su calidad.
Este flujo de trabajo es excelente para la experimentación, pero si quieres usar el modelo para obtener inferencias sobre muchos datos o inferencias de baja latencia sobre la marcha, necesitarás algo más que un notebook. Por ejemplo, supongamos que intentas medir la biodiversidad de un ecosistema en particular y, en lugar de que las personas identifiquen y cuenten manualmente las especies de plantas en la naturaleza, quieres usar este modelo de AA para clasificar grandes lotes de imágenes. Si usas un notebook, es posible que tengas problemas de memoria. Además, es probable que obtener inferencias de todos esos datos sea un trabajo que demore mucho y agote el tiempo de espera en tu notebook.
O imagina que quieres usar este modelo en una aplicación en la que los usuarios puedan subir imágenes de plantas y que las identifiquen de inmediato. Necesitarás un lugar para alojar el modelo que existe fuera de un notebook al que tu aplicación pueda llamar para realizar una inferencia. Además, es poco probable que tengas tráfico coherente en tu modelo, por lo que necesitarás un servicio que pueda ajustar la escala de forma automática cuando sea necesario.
En todos estos casos, un servicio de inferencia administrado reducirá las complicaciones del hosting y el uso de tus modelos de AA. En esta guía, se proporciona una introducción a la obtención de inferencias de modelos de AA en Gemini Enterprise Agent Platform. Ten en cuenta que existen personalizaciones, funciones y formas de interfaz adicionales con el servicio que no se tratan aquí. El objetivo de esta guía es proporcionar una descripción general. Para obtener más información, consulta la documentación sobre las inferencias de Gemini Enterprise Agent Platform.
Descripción general del servicio de inferencia administrado
Agent Platform admite inferencias por lotes y en línea.
La inferencia por lotes es una solicitud asíncrona. Es una buena opción cuando no necesitas una respuesta inmediata y quieres procesar datos acumulados en una sola solicitud. En el ejemplo analizado en la introducción, este sería el caso de uso de la caracterización de la biodiversidad.
Si quieres obtener inferencias de latencia baja a partir de los datos que se pasan a tu modelo sobre la marcha, puedes usar la Inferencia en línea. En el ejemplo que analizamos en la introducción, este sería el caso de uso en el que deseas incorporar tu modelo en una app que ayude a los usuarios a identificar especies de plantas de inmediato.
Sube el modelo a Model Registry de Gemini Enterprise Agent Platform
Para usar el servicio de inferencia, el primer paso es subir tu modelo de AA entrenado a Model Registry. Este es un registro en el que puedes administrar el ciclo de vida de tus modelos.
Cómo crear un recurso del modelo
Cuando entrenas modelos con el servicio de entrenamiento personalizado de Gemini Enterprise Agent Platform, puedes hacer que este se importe de forma automática al registro después de que se complete el trabajo de entrenamiento. Si omitiste ese paso o entrenaste tu modelo fuera de Gemini Enterprise Agent Platform, puedes subirlo de forma manual con la Google Cloud consola o el SDK de Agent Platform para Python si apuntas a una ubicación de Cloud Storage con tus artefactos de modelo guardados. El formato de estos artefactos del modelo puede ser savedmodel.pb, model.joblib, etcétera, según el marco de trabajo de AA que uses.
Cuando subes artefactos a Model Registry de Gemini Enterprise Agent Platform, se crea un recurso Model, que se puede ver en la Google Cloud consola:
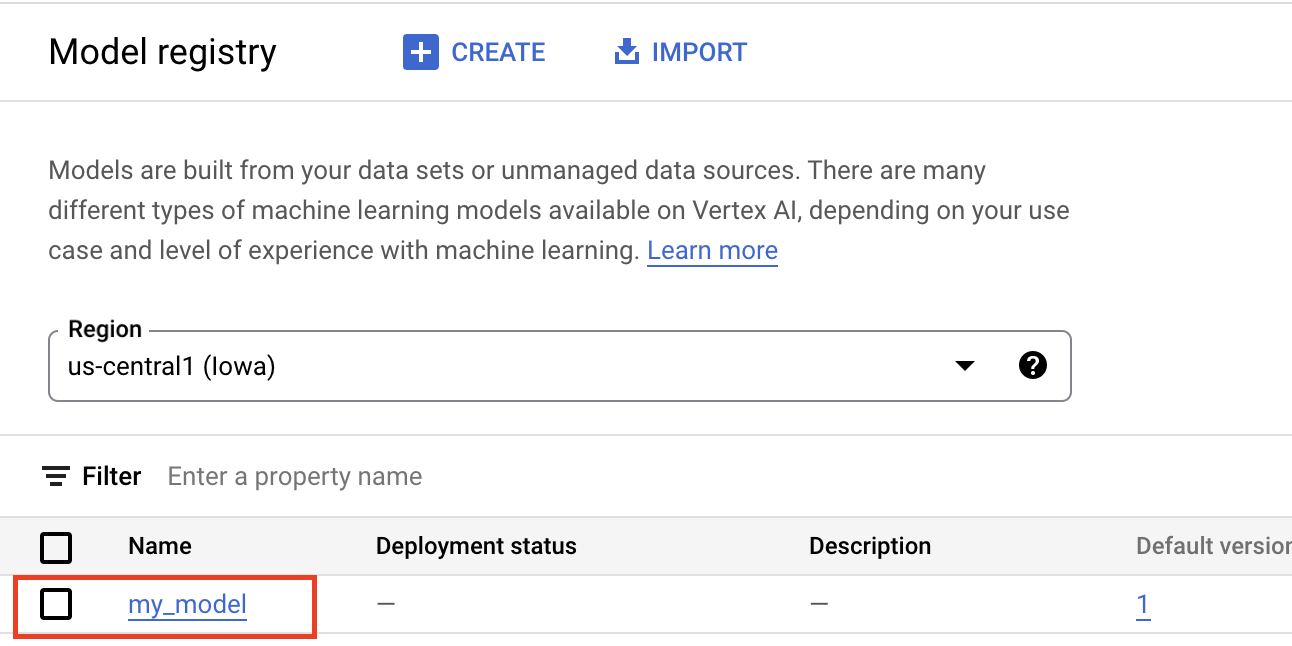
Selecciona un contenedor
Cuando importas un modelo a Model Registry de Gemini Enterprise Agent Platform, debes asociarlo con un contenedor para que Gemini Enterprise Agent Platform entregue solicitudes de inferencia.
Contenedores compilados previamente
La plataforma de agentes de Gemini Enterprise proporciona contenedores compilados previamente que puedes usar para las inferencias. Los contenedores compilados previamente están organizados por framework de AA y versión de framework, y proporcionan servidores de inferencia HTTP que puedes usar para entregar inferencias con una configuración mínima. Solo realizan la operación de inferencia del framework de aprendizaje automático, por lo que, si necesitas procesar tus datos con anterioridad, debes hacerlo antes de realizar la solicitud de inferencia. Del mismo modo, cualquier procesamiento posterior debe realizarse después de que realices la solicitud de inferencia. Para ver un ejemplo del uso de un contenedor compilado previamente, consulta el notebook Cómo entregar modelos de imágenes de PyTorch con contenedores compilados previamente en la plataforma de agentes.
Contenedores personalizados
Si tu caso de uso requiere de bibliotecas que no se incluyen en los contenedores compilados con anterioridad o tal vez tienes transformaciones de datos personalizadas que desees realizar como parte de la solicitud de inferencia, puedes usar un contenedor personalizado que compiles y envíes a Artifact Registry. Si bien los contenedores personalizados permiten una mayor personalización, el contenedor debe ejecutar un servidor HTTP. Específicamente, el contenedor debe escuchar y responder verificaciones de actividad, verificaciones de estado y solicitudes de inferencia. En la mayoría de los casos, se recomienda usar un contenedor precompilado si es posible. Para ver un ejemplo de cómo usar un contenedor personalizado, consulta el notebook GPU-PyTorch Image Classification mediante el entrenamiento de Vertex con un contenedor personalizado.
Rutinas de inferencia personalizadas
Si tu caso de uso requiere transformaciones personalizadas de procesamiento previo y posterior y no deseas la sobrecarga de compilar y mantener un contenedor personalizado, puedes usar las rutinas de inferencia personalizadas. Con las rutinas de inferencia personalizadas, puedes proporcionar tus transformaciones de datos como código de Python y, tras bambalinas, el SDK de Agent Platform para Python compilará un contenedor personalizado que puedes probar de forma local y, luego, implementar en Gemini Enterprise Agent Platform. Para ver un ejemplo del uso de rutinas de inferencia personalizadas, consulta el notebook Rutinas de inferencia personalizadas con Sklearn.
Obtén inferencias por lotes
Una vez que tu modelo esté en Model Registry de Gemini Enterprise Agent Platform, puedes enviar un trabajo de inferencia por lotes desde la consola de Google Cloud o el SDK de Agent Platform para Python. Deberás especificar la ubicación de los datos de origen, así como la ubicación de Cloud Storage o BigQuery donde quieres que se guarden los resultados. También puedes especificar el tipo de máquina en el que deseas que se ejecute este trabajo y los aceleradores opcionales. Debido a que el servicio de inferencias está completamente administrado, Gemini Enterprise Agent Platform aprovisiona automáticamente los recursos de procesamiento, realiza la tarea de inferencia y garantiza la eliminación de los recursos de procesamiento una vez que finaliza el trabajo de inferencia. Se puede hacer un seguimiento del estado de los trabajos de inferencia por lotes en la consola de Google Cloud .
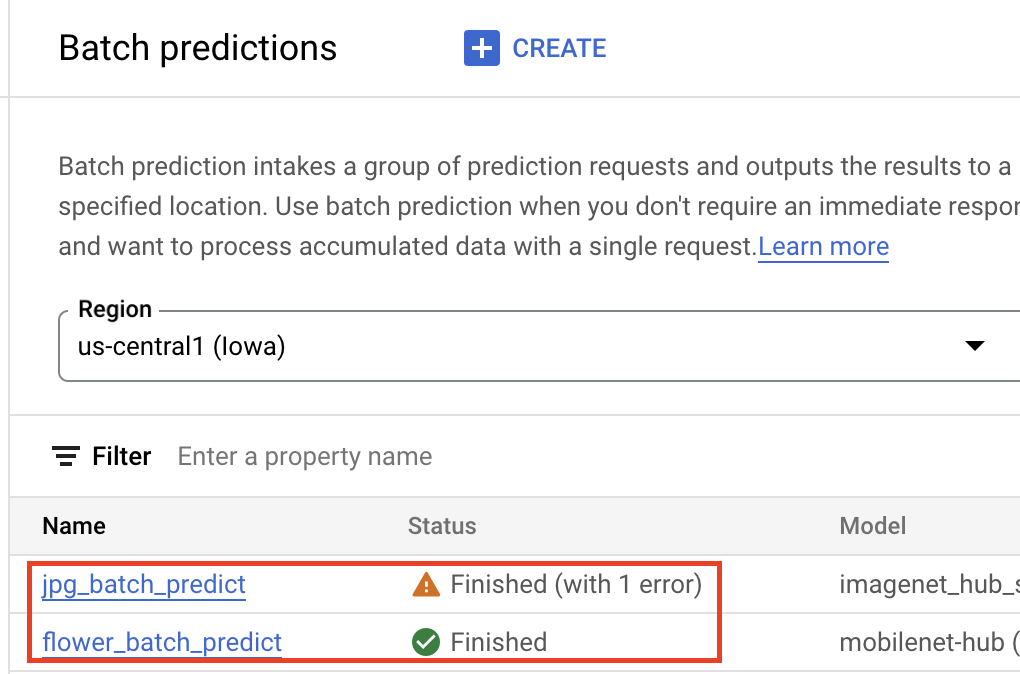
Obtén inferencias en línea
Si quieres obtener inferencias en línea, debes realizar el paso adicional de implementar tu modelo en un extremo de Gemini Enterprise Agent Platform.
De esta manera, se asocian los artefactos del modelo con recursos físicos para la entrega de latencia baja y se crea un recurso DeployedModel.
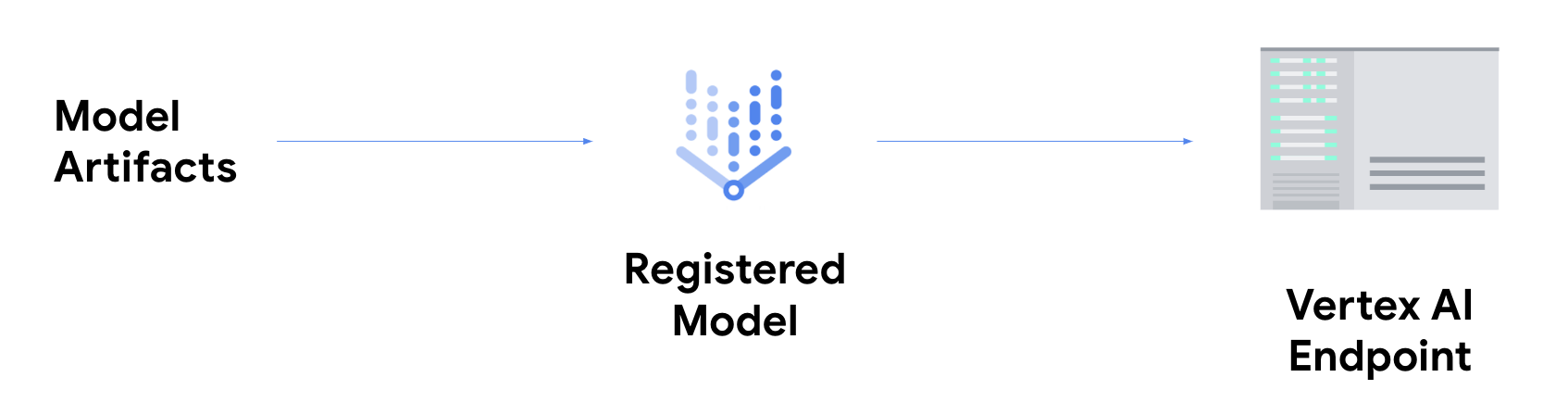
Una vez que el modelo se implementa en un extremo, acepta solicitudes como cualquier otro extremo de REST, lo que significa que puedes llamarlo desde una función de Cloud Run Functions, chatbot, una aplicación web, etcétera. Ten en cuenta que puedes implementar múltiples modelos en un solo extremo, lo que divide el tráfico entre ellos. Esta función es útil, por ejemplo, si quieres lanzar una versión de modelo nueva, pero no deseas dirigir todo el tráfico al modelo nuevo de manera inmediata. También puedes implementar el mismo modelo en varios extremos.
Recursos para obtener inferencias a partir de modelos personalizados en Agent Platform
Para obtener más información sobre el hosting y la entrega de modelos en Agent Platform, consulta los siguientes recursos o el repositorio de GitHub de muestras de Agent Platform.
- Video sobre cómo obtener predicciones
- Entrena y entrega un modelo de TensorFlow con un contenedor compilado previamente
- Entrega modelos de imágenes de PyTorch con contenedores precompilados en Agent Platform
- Entrega un modelo de dispersión estable con un contenedor compilado previamente
- Rutinas de inferencia personalizadas con Sklearn