
Ray ist ein Open-Source-Framework zur Skalierung von KI- und Python-Anwendungen. Ray bietet die Infrastruktur für verteiltes Computing und parallele Verarbeitung für Ihren ML-Workflow („maschinelles Lernen“).
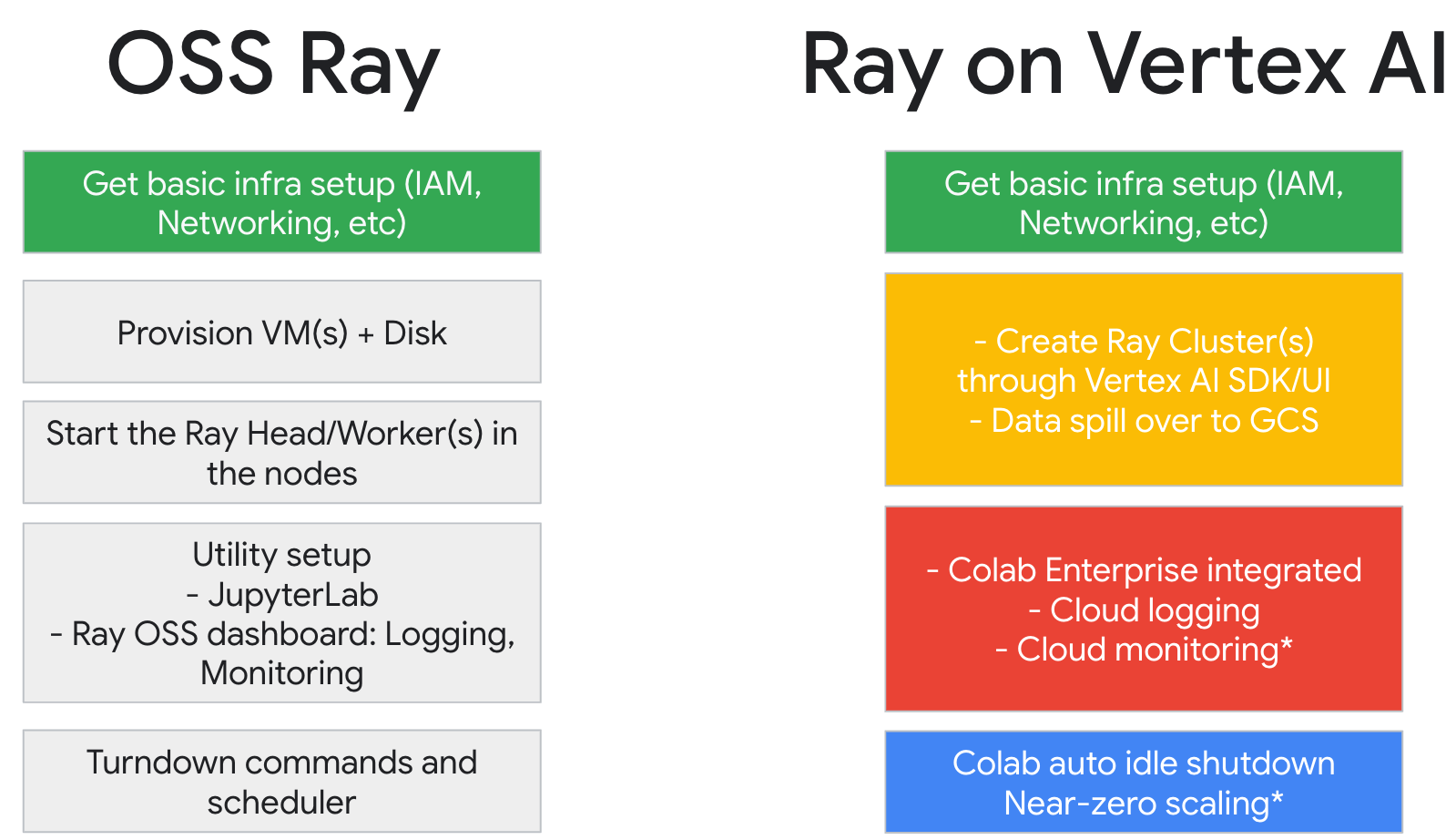
Wenn Sie Ray bereits verwenden, können Sie denselben Open-Source-Ray-Code verwenden, um Programme zu schreiben und Anwendungen mit minimalen Änderungen in Vertex AI zu entwickeln. Anschließend können Sie die Einbindungen von Vertex AI in andere Google Cloud-Dienste wie Vertex AI Inference und BigQuery als Teil Ihres ML-Workflows verwenden.
Wenn Sie Vertex AI bereits verwenden und eine einfachere Methode zum Verwalten von Rechenressourcen benötigen, können Sie das Training mit Ray-Code skalieren.
Workflow für die Verwendung von Ray in Vertex AI
Verwenden Sie Colab Enterprise und Vertex AI SDK für Python, um eine Verbindung zum Ray-Cluster herzustellen.
| Schritte | Beschreibung |
|---|---|
| 1. Einrichtung für Ray in Vertex AI | Richten Sie Ihr Google-Projekt ein, installieren Sie die Version des Vertex AI SDK für Python, die die Funktionen des Ray-Clients enthält, und richten Sie ein VPC-Peering-Netzwerk ein (optional). |
| 2. Ray-Cluster in Vertex AI erstellen | Ray-Cluster in Vertex AI erstellen. Die Administratorrolle für Vertex AI ist erforderlich. |
| 3. Ray-Anwendung in Vertex AI entwickeln | Stellen Sie eine Verbindung zu einem Ray-Cluster in Vertex AI her und entwickeln Sie eine Anwendung. Die Nutzerrolle für Vertex AI ist erforderlich. |
| 4. (Optional) Ray in Vertex AI mit BigQuery verwenden | Mit BigQuery Daten lesen, schreiben und transformieren. |
| 5. (Optional) Modell in Vertex AI bereitstellen und Inferenz abrufen | Ein Modell auf einem Vertex AI-Online-Endpunkt bereitstellen und Inferenzen abrufen. |
| 6. Ray-Cluster in Vertex AI überwachen | Generierte Logs in Cloud Logging und Messwerte in Cloud Monitoring überwachen. |
| 7. Ray-Cluster in Vertex AI löschen | Löschen Sie einen Ray-Cluster in Vertex AI, um unnötige Kosten zu vermeiden. |
Übersicht
Integrierte Ray-Cluster sichern Kapazitätsverfügbarkeit für kritisches ML-Arbeitslasten oder während Spitzenzeiten. Im Gegensatz zu benutzerdefinierten Jobs, bei denen der Trainingsdienst die Ressource nach Abschluss des Jobs freigibt, bleiben Ray-Cluster bis zum Löschen verfügbar.
Hinweis: Verwenden Sie in folgenden Szenarien Ray-Cluster mit langer Ausführungszeit:
- Wenn Sie denselben Ray-Job mehrmals senden, können Sie von Daten- und Bild-Caching profitieren, indem die Jobs auf demselben Ray-Cluster mit langer Laufzeit ausgeführt werden.
- Wenn Sie viele kurzlebige Ray-Jobs ausführen, bei denen die tatsächliche Verarbeitungszeit kürzer als die Startzeit ist, kann es von Vorteil sein, einen Cluster mit langer Laufzeit einzusetzen.
Ray-Cluster in Vertex AI können entweder mit öffentlichen oder mit privaten Verbindungen eingerichtet werden. Die folgenden Diagramme zeigen die Architektur und den Workflow für Ray on Vertex AI. Weitere Informationen finden Sie unter Öffentliche oder private Verbindungen.
Architektur mit öffentlicher Konnektivität
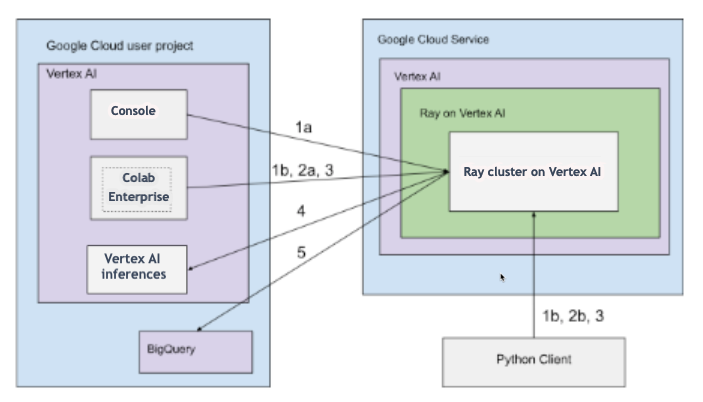
Erstellen Sie den Ray-Cluster in Vertex AI mit den folgenden Optionen:
a. Verwenden Sie die Google Cloud -Console, um den Ray-Cluster in Vertex AI zu erstellen.
b. Erstellen Sie den Ray-Cluster in Vertex AI mit dem Vertex AI SDK für Python.
Stellen Sie mit den folgenden Optionen eine Verbindung zum Ray-Cluster in Vertex AI für die interaktive Entwicklung her:
a. Verwenden Sie Colab Enterprise in der Google Cloud Console für eine nahtlose Verbindung.
b. Verwenden Sie eine beliebige im öffentlichen Internet zugängliche Python-Umgebung.
Entwickeln Sie Ihre Anwendung und trainieren Sie Ihr Modell im Ray-Cluster in Vertex AI:
Verwenden Sie das Vertex AI SDK für Python in Ihrer bevorzugten Umgebung (Colab Enterprise oder ein beliebiges Python-Notebook).
Schreiben Sie ein Python-Script in Ihrer bevorzugten Umgebung.
Senden Sie mit dem Vertex AI SDK für Python, der Ray Job CLI oder der Ray Job Submission API einen Ray-Job an den Ray-Cluster in Vertex AI.
Stellen Sie das trainierte Modell auf einem Vertex AI-Online-Endpunkt für Live-Inferenz bereit.
Verwenden Sie BigQuery, um Ihre Daten zu verwalten.
Architektur mit VPC
Das folgende Diagramm zeigt die Architektur und den Workflow für Ray on Vertex AI nach der Einrichtung Ihres Google Cloud -Projekts und Ihres VPC-Netzwerk. Dies ist optional:
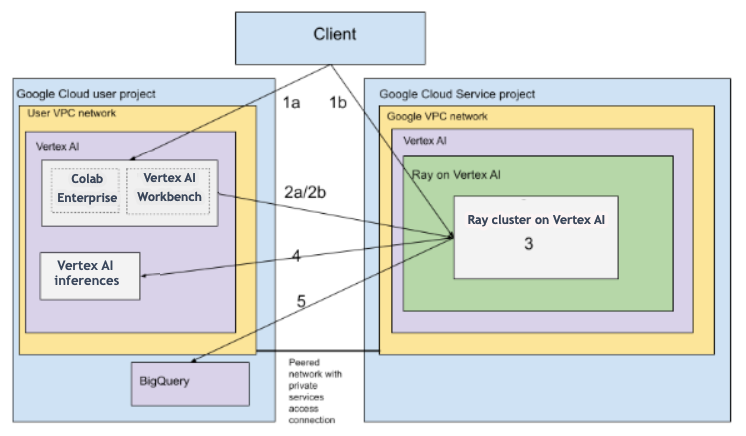
Richten Sie Ihr (a) Google-Projekt und (b) VPC-Netzwerk ein.
Erstellen Sie den Ray-Cluster in Vertex AI mit den folgenden Optionen:
a. Verwenden Sie die Google Cloud -Console, um den Ray-Cluster in Vertex AI zu erstellen.
b. Erstellen Sie den Ray-Cluster in Vertex AI mit dem Vertex AI SDK für Python.
Stellen Sie mit den folgenden Optionen über ein VPC-Peering-Netzwerk eine Verbindung zum Ray-Cluster in Vertex AI her:
Verwenden Sie Colab Enterprise in derGoogle Cloud Console.
Verwenden Sie ein Vertex AI Workbench-Notebook.
Entwickeln Sie Ihre Anwendung und trainieren Sie Ihr Modell im Ray-Cluster in Vertex AI mit den folgenden Optionen:
Verwenden Sie das Vertex AI SDK für Python in Ihrer bevorzugten Umgebung (Colab Enterprise oder ein Vertex AI Workbench-Notebook).
Schreiben Sie ein Python-Script in Ihrer bevorzugten Umgebung. Senden Sie mit dem Vertex AI SDK für Python, der Ray Job CLI oder dem Ray Dashboard einen Ray-Job an den Ray-Cluster in Vertex AI.
Stellen Sie das trainierte Modell auf einem Vertex AI-Online-Endpunkt für Inferenz bereit.
Verwenden Sie BigQuery, um Ihre Daten zu verwalten.
Terminologie
Eine vollständige Liste der Begriffe finden Sie im Vertex AI-Glossar für Predictive AI.
-
Autoscaling
- Autoscaling ist die Fähigkeit einer Computeressource, z. B. des Worker-Pools eines Ray-Clusters, die Anzahl der Knoten automatisch an die Arbeitslastanforderungen anzupassen, um die Ressourcennutzung und die Kosten zu optimieren. Weitere Informationen finden Sie unter Ray-Cluster in Vertex AI skalieren: Autoscaling.
-
Batch-Inferenz
- Die Batchinferenz gibt für eine Gruppe von Inferenzanfragen und -ausgaben die Ergebnisse in einer einzelnen Datei aus. Weitere Informationen finden Sie unter Übersicht: Inferenz in Vertex AI abrufen.
-
BigQuery
- BigQuery ist ein vollständig verwaltetes, serverloses und hoch skalierbares Data Warehouse für Unternehmen von Google Cloud, das für die Analyse umfangreicher Datasets mit SQL-Abfragen in unglaublich hoher Geschwindigkeit entwickelt wurde. BigQuery ermöglicht leistungsstarke Business Intelligence und Analysen, ohne dass Nutzer eine Infrastruktur verwalten müssen. Weitere Informationen finden Sie unter Vom Data Warehouse zur autonomen Daten- und KI-Plattform.
-
Cloud Logging
- Cloud Logging ist ein vollständig verwalteter Echtzeit-Logging-Dienst von Google Cloud, mit dem Sie Logs aus allen Ihren Google Cloud-Ressourcen, lokalen Anwendungen und sogar benutzerdefinierten Quellen erfassen, speichern, analysieren und überwachen können. Cloud Logging zentralisiert die Logverwaltung und erleichtert so die Fehlerbehebung, die Prüfung und die Analyse des Verhaltens und des Zustands Ihrer Anwendungen und Infrastruktur. Weitere Informationen finden Sie unter Cloud Logging – Übersicht.
-
Colab Enterprise
- Colab Enterprise ist eine kollaborative, verwaltete Jupyter-Notebook-Umgebung, die die beliebte Google Colab-Benutzerfreundlichkeit in Google Cloud bietet und Sicherheits- und Compliance-Funktionen auf Unternehmensniveau umfasst. Colab Enterprise bietet eine Notebook-zentrierte Umgebung ohne Konfiguration, in der Rechenressourcen von Vertex AI verwaltet werden. Außerdem ist es in andere Google Cloud-Dienste wie BigQuery eingebunden. Weitere Informationen finden Sie unter Einführung in Colab Enterprise.
-
Benutzerdefiniertes Container-Image
- Ein benutzerdefiniertes Container-Image ist ein eigenständiges, ausführbares Paket, das den Anwendungscode des Nutzers, die Laufzeit, Bibliotheken, Abhängigkeiten und die Umgebungskonfiguration enthält. Im Kontext von Google Cloud, insbesondere Vertex AI, ermöglicht es dem Nutzer, seinen Code für das Training von Machine-Learning-Modellen oder seine Serving-Anwendung mit den genauen Abhängigkeiten zu verpacken. So wird die Reproduzierbarkeit sichergestellt und der Nutzer kann eine Arbeitslast auf verwalteten Diensten mit bestimmten Softwareversionen oder eindeutigen Konfigurationen ausführen, die von Standardumgebungen nicht bereitgestellt werden. Weitere Informationen finden Sie unter Anforderungen an benutzerdefinierte Container für die Inferenz.
-
Endpunkt
- Ressourcen, auf denen Sie trainierte Modelle bereitstellen können, um Inferenzen zu berechnen. Weitere Informationen finden Sie unter Endpunkttyp auswählen.
-
Berechtigungen zur Identitäts- und Zugriffsverwaltung (Identity and Access Management, IAM)
- IAM-Berechtigungen (Identity and Access Management) sind spezifische, detaillierte Funktionen, die definieren, wer was mit welchen Google Cloud-Ressourcen tun darf. Sie werden Hauptkonten (z. B. Nutzern, Gruppen oder Dienstkonten) über Rollen zugewiesen und ermöglichen so eine präzise Steuerung des Zugriffs auf Dienste und Daten in einem Google Cloud-Projekt oder einer Organisation. Weitere Informationen finden Sie unter Zugriffssteuerung mit IAM.
-
Inferenz
- Im Kontext der Vertex AI-Plattform bezieht sich die Inferenz auf den Prozess, bei dem Datenpunkte durch ein Modell für maschinelles Lernen geleitet werden, um eine Ausgabe zu berechnen, z. B. einen einzelnen numerischen Wert. Dieser Vorgang wird auch als „Operationalisieren eines ML-Modells“ oder „Überführen eines ML-Modells in die Produktion“ bezeichnet. Die Inferenz ist ein wichtiger Schritt im Workflow für maschinelles Lernen, da sie es ermöglicht, Modelle zu verwenden, um Rückschlüsse auf neue Daten zu ziehen. In Vertex AI kann die Inferenz auf verschiedene Arten durchgeführt werden, z. B. als Batchinferenz und als Onlineinferenz. Bei der Batchinferenz wird eine Gruppe von Inferenzanfragen ausgeführt und die Ergebnisse in einer Datei ausgegeben. Bei der Onlineinferenz sind Echtzeitinferenzen für einzelne Datenpunkte möglich.
-
Network File System (NFS)
- Ein Client-/Serversystem, mit dem Nutzer über ein Netzwerk auf Dateien zugreifen und sie so behandeln können, als befänden sie sich in einem lokalen Dateiverzeichnis. Weitere Informationen finden Sie unter NFS-Freigabe einbinden.
-
Online-Inferenz
- Synchrones Abrufen von Inferenzinformationen für einzelne Instanzen. Weitere Informationen finden Sie unter Online-Inferenz.
-
Nichtflüchtige Ressource
- Ein Typ von Vertex AI-Computing-Ressource, z. B. ein Ray-Cluster, der zugewiesen und verfügbar bleibt, bis er explizit gelöscht wird. Dies ist vorteilhaft für die iterative Entwicklung und reduziert den Startaufwand zwischen Jobs. Weitere Informationen finden Sie unter Informationen zu einer nichtflüchtigen Ressource abrufen.
-
Pipeline
- ML-Pipelines sind portable und skalierbare ML-Workflows, die auf Containern basieren. Weitere Informationen finden Sie unter Einführung in Vertex AI Pipelines.
-
Vordefinierter Container
- Von Vertex AI bereitgestellte Container-Images, in denen gängige ML-Frameworks und -Abhängigkeiten vorinstalliert sind, was die Einrichtung für Trainings- und Inferenzjobs vereinfacht. Weitere Informationen finden Sie unter Vordefinierte Container für serverloses Training .
-
Private Service Connect (PSC)
- Private Service Connect ist eine Technologie, mit der Compute Engine-Kunden private IPs in ihrem Netzwerk entweder einem anderen VPC-Netzwerk oder Google APIs zuordnen können. Weitere Informationen finden Sie unter Private Service Connect.
-
Ray-Cluster in Vertex AI
- Ein Ray-Cluster in Vertex AI ist ein verwalteter Cluster von Rechenknoten, der zum Ausführen von verteilten Anwendungen für maschinelles Lernen (ML) und Python verwendet werden kann. Es bietet die Infrastruktur für verteiltes Computing und parallele Verarbeitung für Ihren ML-Workflow. Ray-Cluster sind in Vertex AI integriert, um die Kapazitätsverfügbarkeit für kritische ML-Arbeitslasten oder während Spitzenzeiten zu gewährleisten. Im Gegensatz zu benutzerdefinierten Jobs, bei denen der Trainingsdienst die Ressource nach Abschluss des Jobs freigibt, bleiben Ray-Cluster bis zum Löschen verfügbar. Weitere Informationen finden Sie in der Übersicht zu Ray on Vertex AI.
-
Ray on Vertex AI (RoV)
- Ray on Vertex AI wurde so entwickelt, dass Sie denselben Open-Source-Ray-Code zum Schreiben von Programmen und Entwickeln von Anwendungen in Vertex AI mit minimalen Änderungen verwenden können. Weitere Informationen finden Sie in der Übersicht zu Ray on Vertex AI.
-
Ray on Vertex AI SDK für Python
- Das Ray on Vertex AI SDK für Python ist eine Version des Vertex AI SDK für Python, die die Funktionen von Ray Client, Ray BigQuery Connector, der Ray-Clusterverwaltung in Vertex AI und Inferenzen in Vertex AI umfasst. Weitere Informationen finden Sie unter Einführung in das Vertex AI SDK für Python.
-
Ray on Vertex AI SDK für Python
- Das Ray on Vertex AI SDK für Python ist eine Version des Vertex AI SDK für Python, die die Funktionen von Ray Client, Ray BigQuery Connector, der Ray-Clusterverwaltung in Vertex AI und Inferenz in Vertex AI umfasst. Weitere Informationen finden Sie unter Einführung in das Vertex AI SDK für Python.
-
Dienstkonto
- Dienstkonten sind spezielle Google Cloud-Konten, die von Anwendungen oder virtuellen Maschinen verwendet werden, um autorisierte API-Aufrufe an Google Cloud-Dienste auszuführen. Im Gegensatz zu Nutzerkonten sind sie nicht an eine einzelne Person gebunden, sondern fungieren als Identität für Ihren Code. So ermöglichen sie einen sicheren und programmatischen Zugriff auf Ressourcen, ohne dass Anmeldedaten einer Person erforderlich sind. Weitere Informationen finden Sie unter Dienstkontenübersicht.
-
Vertex AI Workbench
- Vertex AI Workbench ist eine einheitliche, Jupyter-Notebook-basierte Entwicklungsumgebung, die den gesamten Data-Science-Workflow unterstützt, von der Datenexploration und -analyse bis hin zur Modellentwicklung, zum Modelltraining und zur Modellbereitstellung. Vertex AI Workbench bietet eine verwaltete und skalierbare Infrastruktur mit integrierten Integrationen in andere Google Cloud-Dienste wie BigQuery und Cloud Storage. So können Data Scientists ihre Machine-Learning-Aufgaben effizient ausführen, ohne die zugrunde liegende Infrastruktur verwalten zu müssen. Weitere Informationen finden Sie unter Einführung in Vertex AI Workbench.
-
Worker-Knoten
- Ein Worker-Knoten ist eine einzelne Maschine oder Recheninstanz in einem Cluster, die für die Ausführung von Aufgaben oder die Erledigung von Arbeiten verantwortlich ist. In Systemen wie Kubernetes- oder Ray-Clustern sind Knoten die Grundeinheiten für die Berechnung. Weitere Informationen finden Sie unter Was ist High Performance Computing (HPC)?.
-
Worker-Pool
- Komponenten eines Ray-Clusters, die verteilte Aufgaben ausführen. Worker-Pools können mit bestimmten Maschinentypen konfiguriert werden und unterstützen sowohl Autoscaling als auch manuelle Skalierung. Weitere Informationen finden Sie unter Struktur des Trainingsclusters.
Preise
Die Preise für Ray on Vertex AI werden so berechnet:
Die verwendeten Rechenressourcen werden basierend auf der Maschinenkonfiguration abgerechnet, die Sie beim Erstellen Ihres Ray-Clusters in Vertex AI auswählen. Die Preise für Ray on Vertex AI finden Sie auf der Seite „Preise“.
In Bezug auf Ray-Cluster entstehen Ihnen nur Kosten während der Status-WErte „RUNNING” und „UPDATING” in Rechnung gestellt. Für andere Statuswerte werden keine Kosten berechnet. Der berechnete Betrag basiert auf der tatsächlichen Clustergröße zu diesem Zeitpunkt.
Wenn Sie Aufgaben mit dem Ray-Cluster in Vertex AI ausführen, werden Logs automatisch generiert und auf Basis der Cloud Logging-Preise berechnet.
Wenn Sie Ihr Modell auf einem Endpunkt für Onlineinferenzen bereitstellen, lesen Sie den Abschnitt „Vorhersage und Erläuterung“ auf der Vertex AI-Preisseite.
Wenn Sie BigQuery mit Ray on Vertex AI verwenden, finden Sie weitere Informationen unter BigQuery-Preise.