
Esta página descreve como configurar pedidos de tarefas de inferência em lote para incluir uma análise única da monitorização de modelos. Para inferências em lote, a monitorização de modelos suporta a deteção de desequilíbrios de funcionalidades para funcionalidades de entrada categóricas e numéricas.
Para criar uma tarefa de inferência em lote com a análise de desequilíbrio da monitorização de modelos, tem de incluir os dados de entrada de inferência em lote e os dados de preparação originais do modelo no pedido. Só pode adicionar a análise de monitorização de modelos quando cria novas tarefas de inferência em lote.
Para mais informações sobre a distorção, consulte o artigo Introdução à monitorização de modelos.
Para ver instruções sobre como configurar a monitorização de modelos para inferências online (em tempo real), consulte o artigo Usar a monitorização de modelos.
Pré-requisitos
Para usar a monitorização de modelos com inferências em lote, conclua o seguinte:
Ter um modelo disponível no Registo de modelos do Vertex AI que seja do tipo AutoML tabular ou preparação personalizada tabular.
Carregue os seus dados de preparação para o Cloud Storage ou o BigQuery e obtenha o link do URI para os dados.
- Para modelos preparados com o AutoML, pode usar o ID do conjunto de dados para o seu conjunto de dados de preparação.
A monitorização de modelos compara os dados de preparação com a saída da inferência em lote. Certifique-se de que usa formatos de ficheiros suportados para os dados de preparação e a saída da inferência em lote:
Tipo de modelo Dados de preparação Resultado da inferência em lote Com formação personalizada CSV, JSONL, BigQuery, TfRecord(tf.train.Example) JSONL AutoML tabular CSV, JSONL, BigQuery, TfRecord(tf.train.Example) CSV, JSONL, BigQuery, TfRecord(Protobuf.Value) Opcional: para modelos preparados de forma personalizada, carregue o esquema do seu modelo para o Cloud Storage. A monitorização de modelos requer o esquema para calcular a distribuição de base para a deteção de desvios.
Peça uma inferência em lote
Pode usar os seguintes métodos para adicionar configurações de monitorização de modelos a tarefas de inferência em lote:
Consola
Siga as instruções para fazer um pedido de inferência em lote com a monitorização de modelos ativada:
API REST
Siga as instruções para fazer um pedido de inferência em lote através da API REST:
Quando criar o pedido de inferência em lote, adicione a seguinte configuração de monitorização de modelos ao corpo JSON do pedido:
"modelMonitoringConfig": {
"alertConfig": {
"emailAlertConfig": {
"userEmails": "EMAIL_ADDRESS"
},
"notificationChannels": [NOTIFICATION_CHANNELS]
},
"objectiveConfigs": [
{
"trainingDataset": {
"dataFormat": "csv",
"gcsSource": {
"uris": [
"TRAINING_DATASET"
]
}
},
"trainingPredictionSkewDetectionConfig": {
"skewThresholds": {
"FEATURE_1": {
"value": VALUE_1
},
"FEATURE_2": {
"value": VALUE_2
}
}
}
}
]
}
where:
EMAIL_ADDRESS é o endereço de email onde quer receber alertas da monitorização de modelos. Por exemplo,
example@example.com.NOTIFICATION_CHANNELS: uma lista de canais de notificação do Cloud Monitoring onde quer receber alertas da monitorização de modelos. Use os nomes dos recursos para os canais de notificação, que pode obter listando os canais de notificação no seu projeto. Por exemplo,
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568".TRAINING_DATASET é o link para o conjunto de dados de preparação armazenado no Cloud Storage.
- Para usar uma associação a um conjunto de dados de preparação do BigQuery, substitua o campo
gcsSourcepelo seguinte:
"bigquerySource": { { "inputUri": "TRAINING_DATASET" } }- Para usar um link para um modelo do AutoML, substitua o campo
gcsSourcepelo seguinte:
"dataset": "TRAINING_DATASET"
- Para usar uma associação a um conjunto de dados de preparação do BigQuery, substitua o campo
FEATURE_1:VALUE_1 e FEATURE_2:VALUE_2 é o limite de alerta para cada funcionalidade que quer monitorizar. Por exemplo, se especificar
Age=0.4, o Model Monitoring regista um alerta quando a distância estatística entre as distribuições de entrada e de referência para a caraterísticaAgeexceder 0,4. Por predefinição, todas as caraterísticas categóricas e numéricas são monitorizadas com valores de limite de 0,3.
Para mais informações sobre as configurações da monitorização de modelos, consulte a referência de tarefas de monitorização.
Python
Consulte o exemplo de bloco de notas para executar uma tarefa de inferência em lote com a monitorização de modelos para um modelo tabular personalizado.
A monitorização de modelos envia-lhe automaticamente notificações de atualizações e alertas de tarefas por email.
Aceda às métricas de desvio
Pode usar os seguintes métodos para aceder às métricas de desvio para tarefas de inferência em lote:
Consola (histograma)
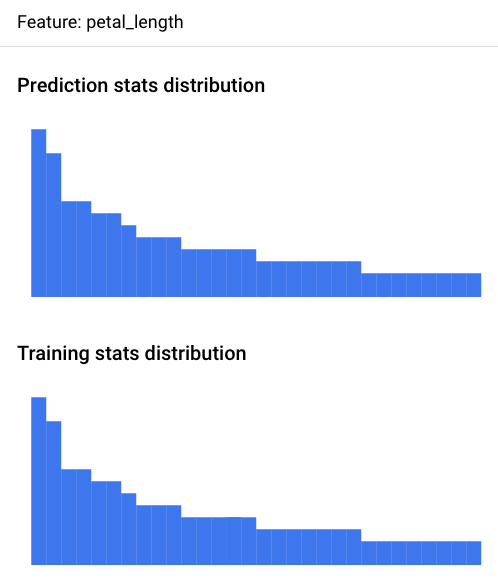
Use a Google Cloud consola para ver os histogramas de distribuição de funcionalidades de cada funcionalidade monitorizada e saber que alterações provocaram a distorção ao longo do tempo:
Aceda à página Previsões em lote:
Na página Previsões em lote, clique na tarefa de inferência em lote que quer analisar.
Clique no separador Alertas de monitorização de modelos para ver uma lista das funcionalidades de entrada do modelo, juntamente com informações pertinentes, como o limite de alerta para cada funcionalidade.
Para analisar uma funcionalidade, clique no nome da mesma. Uma página mostra os histogramas de distribuição de funcionalidades para essa funcionalidade.
A visualização da distribuição de dados como histogramas permite-lhe focar-se rapidamente nas alterações ocorridas nos dados. Posteriormente, pode decidir ajustar o pipeline de geração de funcionalidades ou voltar a preparar o modelo.
Consola (ficheiro JSON)
Use a Google Cloud consola para aceder às métricas no formato JSON:
Aceda à página Previsões em lote:
Clique no nome da tarefa de monitorização da inferência em lote.
Clique no separador Propriedades de monitorização.
Clique no link Diretório de saída de monitorização, que direciona para um contentor do Cloud Storage.
Clique na pasta
metrics/.Clique na pasta
skew/.Clique no ficheiro
feature_skew.json, que direciona para a página Detalhes do objeto.Abra o ficheiro JSON através de uma das seguintes opções:
Clique em Transferir e abra o ficheiro no seu editor de texto local.
Use o caminho do URI gsutil para executar
gcloud storage cat gsutil_URIno Cloud Shell ou no seu terminal local.
O ficheiro feature_skew.json inclui um dicionário em que a chave é o nome da funcionalidade e o valor é a distorção da funcionalidade. Por exemplo:
{
"cnt_ad_reward": 0.670936,
"cnt_challenge_a_friend": 0.737924,
"cnt_completed_5_levels": 0.549467,
"month": 0.293332,
"operating_system": 0.05758,
"user_pseudo_id": 0.1
}
Python
Consulte o exemplo de bloco de notas para aceder às métricas de assimetria de um modelo tabular personalizado após executar uma tarefa de inferência em lote com a monitorização de modelos.
Depure falhas de monitorização da inferência em lote
Se a sua tarefa de monitorização de inferência em lote falhar, pode encontrar registos de depuração na Google Cloud consola:
Aceda à página Previsões em lote.
Clique no nome da tarefa de monitorização de inferência em lote com falhas.
Clique no separador Propriedades de monitorização.
Clique no link Diretório de saída de monitorização, que direciona para um contentor do Cloud Storage.
Clique na pasta
logs/.Clique num dos ficheiros
.INFO, que direciona para a página Detalhes do objeto.Abra o ficheiro de registos com qualquer uma das opções:
Clique em Transferir e abra o ficheiro no seu editor de texto local.
Use o caminho do URI gsutil para executar
gcloud storage cat gsutil_URIno Cloud Shell ou no seu terminal local.
Tutoriais do bloco de notas
Saiba como usar o Vertex AI Model Monitoring para obter visualizações e estatísticas para modelos com estes tutoriais completos.
AutoML
- Vertex AI Model Monitoring para modelos tabulares do AutoML
- Vertex AI Model Monitoring para a previsão em lote em modelos de imagens do AutoML
- Vertex AI Model Monitoring para a previsão online em modelos de imagens do AutoML
Personalizado
- Vertex AI Model Monitoring para modelos tabulares personalizados
- Vertex AI Model Monitoring para modelos tabulares personalizados com o contentor TensorFlow Serving
Modelos XGBoost
Atribuições de funcionalidades do Vertex Explainable AI
Inferência em lote
Configuração para modelos tabulares
O que se segue?
- Saiba como usar a Monitorização de modelos.
- Saiba como a monitorização de modelos calcula a discrepância entre a preparação e a publicação, e a variação da inferência.