

Gemini Enterprise Agent Platform Pipelines は、Google Cloud Platform でエンドツーエンドの ML ワークフローを構築、デプロイ、管理するのに役立つマネージド サービスです。パイプラインを実行するためのサーバーレス環境が提供されるため、インフラストラクチャの管理に悩む必要はありません。
このチュートリアルでは、Agent Platform Pipelines を使用してカスタム トレーニング ジョブを実行し、トレーニング済みモデルをハイブリッド ネットワーク環境の Gemini Enterprise Agent Platform にデプロイします。
プロセス全体が完了するまでに 2~3 時間かかります。これには、パイプラインの実行にかかる時間(約 50 分)も含まれます。
このチュートリアルは、Gemini Enterprise Agent Platform、Virtual Private Cloud(VPC)、 Google Cloud コンソール、Cloud Shell に精通している企業のネットワーク管理者、データ サイエンティスト、研究者を対象としています。Vertex AI Workbench の使用経験があると役立ちますが、必須ではありません。
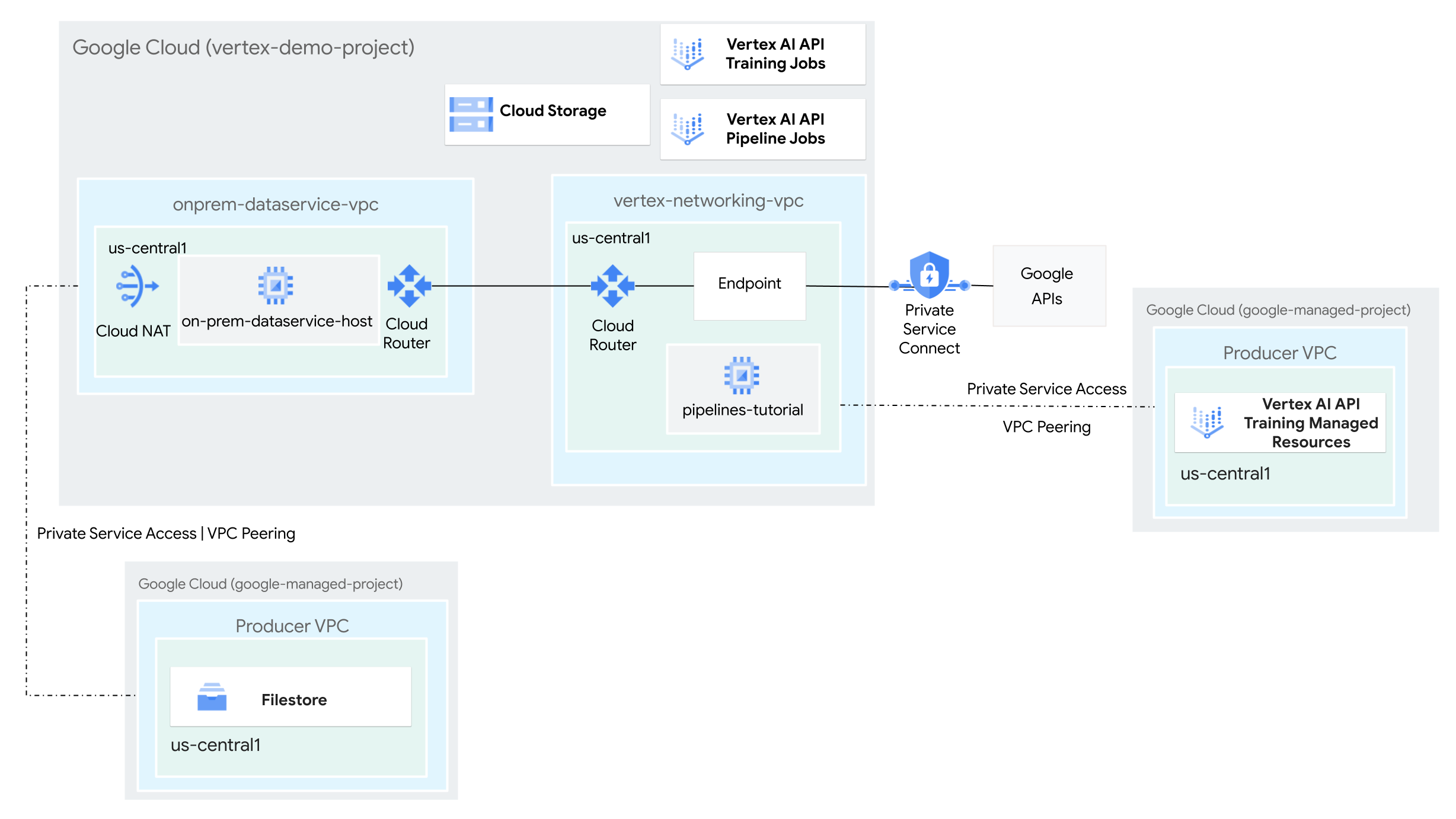
目標
- 2 つの Virtual Private Cloud(VPC)ネットワークを作成します。
- 1 つ(
vertex-networking-vpc)は、Agent Platform Pipelines API を使用して、ML モデルをトレーニングしてエンドポイントにデプロイするためのパイプライン テンプレートを作成してホストします。 - もう 1 つ(
onprem-dataservice-vpc)は、オンプレミス ネットワークを表します。
- 1 つ(
- 次のように 2 つの VPC ネットワークを接続します。
- HA VPN ゲートウェイ、Cloud VPN トンネル、Cloud Router をデプロイして、
vertex-networking-vpcとonprem-dataservice-vpcに接続します。 - 限定公開のリクエストを Agent Platform Pipelines REST API に転送する Private Service Connect(PSC)エンドポイントを作成します。
- Private Service Connect エンドポイントのルートを
onprem-dataservice-vpcに通知するために、vertex-networking-vpcに Cloud Router のカスタム ルート アドバタイズを構成します。
- HA VPN ゲートウェイ、Cloud VPN トンネル、Cloud Router をデプロイして、
onprem-dataservice-vpcVPC ネットワークに Filestore インスタンスを作成し、そこに NFS 共有でトレーニング データを追加します。- トレーニング ジョブ用の Python パッケージ アプリケーションを作成します。
- 次の処理を行う Agent Platform Pipelines ジョブ テンプレートを作成します。
- NFS 共有のデータに対してトレーニング ジョブを作成して実行します。
- トレーニング済みモデルをインポートして、Gemini Enterprise Agent Platform Model Registry にアップロードします。
- オンライン予測用の Gemini Enterprise Agent Platform エンドポイントを作成します。
- エンドポイントにモデルをデプロイします。
- パイプライン テンプレートを Artifact Registry リポジトリにアップロードします。
- Agent Platform Pipelines REST API を使用して、オンプレミス データ サービス ホスト(
on-prem-dataservice-host)からパイプラインの実行をトリガーします。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
- Cloud NAT
- Cloud Storage
- Cloud VPN
- Compute Engine
- Filestore
- Gemini Enterprise Agent Platform
- Virtual Private Cloud
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
-
Google Cloud コンソールで、プロジェクトの選択ページに移動します。
-
Google Cloud プロジェクトの選択または作成
プロジェクトの選択または作成に必要なロール
- プロジェクトを選択する: プロジェクトの選択に特定の IAM ロールは必要ありません。ロールが付与されているプロジェクトであれば、どのプロジェクトでも選択できます。
-
プロジェクトを作成する: プロジェクトを作成するには、
resourcemanager.projects.create権限を含むプロジェクト作成者ロール(roles/resourcemanager.projectCreator)が必要です。詳しくは、ロールを付与する方法をご覧ください。
- このチュートリアルで説明するコマンドを実行するために、Cloud Shell を開きます。Cloud Shell は Google Cloud のインタラクティブなシェル環境であり、ウェブブラウザからプロジェクトやリソースを管理できます。
- Cloud Shell で現在のプロジェクトを Google Cloud プロジェクト ID に設定してから、同じプロジェクト ID を
projectidシェル変数に保存します。projectid="PROJECT_ID" gcloud config set project ${projectid} - プロジェクト オーナーでない場合は、プロジェクト IAM 管理者(
roles/resourcemanager.projectIamAdmin)のロールを付与するようプロジェクト オーナーに依頼してください。このロールは、次のステップで IAM ロールを付与するために必要です。 -
ユーザー アカウントにロールを付与します。次の IAM ロールごとに次のコマンドを 1 回実行します。
roles/artifactregistry.admin, roles/artifactregistry.repoAdmin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/file.editor, roles/logging.viewer, roles/logging.admin, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/servicemanagement.quotaAdmin, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/storage.objectAdmin, roles/aiplatform.admin, roles/aiplatform.user, roles/aiplatform.viewer, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/resourcemanager.projectIamAdmingcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
次のように置き換えます。
PROJECT_ID: プロジェクト ID。USER_IDENTIFIER: ユーザー アカウントの識別子。例:myemail@example.comROLE: ユーザー アカウントに付与する IAM ロール。
DNS、Artifact Registry、IAM、Compute Engine、Cloud Logging、Network Connectivity、Notebooks、Cloud Filestore、Service Networking、Service Usage、Agent Platform API を有効にします。
API を有効にするために必要なロール
API を有効にするには、
serviceusage.services.enable権限を含む Service Usage 管理者 IAM ロール(roles/serviceusage.serviceUsageAdmin)が必要です。ロールを付与する方法を確認する。gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com logging.googleapis.com networkconnectivity.googleapis.com notebooks.googleapis.com file.googleapis.com servicenetworking.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.com
VPC ネットワークを作成する
このセクションでは、2 つの VPC ネットワークを作成します。1 つは Agent Platform Pipelines 用に Google API にアクセスするためのもので、もう 1 つはオンプレミス ネットワークをシミュレートするためのものです。2 つの VPC ネットワークに、それぞれ Cloud Router と Cloud NAT ゲートウェイを作成します。Cloud NAT ゲートウェイは、外部 IP アドレスを持たない Compute Engine 仮想マシン(VM)インスタンスの送信接続を提供します。
Cloud Shell で、次のコマンドを実行します。ここで、PROJECT_ID はプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}vertex-networking-vpcVPC ネットワークを作成します。gcloud compute networks create vertex-networking-vpc \ --subnet-mode customvertex-networking-vpcネットワークで、プライマリ IPv4 範囲が10.0.0.0/24のサブネットをpipeline-networking-subnet1という名前で作成します。gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessオンプレミス ネットワーク(
onprem-dataservice-vpc)をシミュレートするための VPC ネットワークを作成します。gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode customonprem-dataservice-vpcネットワークで、プライマリ IPv4 範囲が172.16.10.0/24のサブネットをonprem-dataservice-vpc-subnet1という名前で作成します。gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
VPC ネットワークが正しく構成されていることを確認する
Google Cloud コンソールで、[VPC ネットワーク] ページの [現在のプロジェクトのネットワーク] タブに移動します。
VPC ネットワークのリストで、2 つのネットワーク(
vertex-networking-vpcとonprem-dataservice-vpc)が作成されていることを確認します。[現在のプロジェクトのサブネット] タブをクリックします。
VPC サブネットのリストで、
pipeline-networking-subnet1サブネットとonprem-dataservice-vpc-subnet1サブネットが作成されていることを確認します。
ハイブリッド接続の構成
このセクションでは、相互に接続する 2 つの HA VPN ゲートウェイを作成します。1 つは vertex-networking-vpc VPC ネットワークにあります。もう一つは onprem-dataservice-vpc VPC ネットワークにあります。各ゲートウェイには、Cloud Router と VPN トンネルのペアが含まれます。
HA VPN ゲートウェイを作成する
Cloud Shell で、
vertex-networking-vpcVPC ネットワークに HA VPN ゲートウェイを作成します。gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1onprem-dataservice-vpcVPC ネットワークに HA VPN ゲートウェイを作成します。gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1Google Cloud コンソールで、[VPN] ページの [Cloud VPN ゲートウェイ] タブに移動します。
2 つのゲートウェイ(
vertex-networking-vpn-gw1とonprem-vpn-gw1)が作成され、それぞれに 2 つのインターフェース IP アドレスがあることを確認します。
Cloud Router と Cloud NAT ゲートウェイを作成する
2 つの VPC ネットワークに、Cloud NAT で使用する Cloud Router と HA VPN の BGP セッションを管理する Cloud Router を 1 つずつ作成します。
Cloud Shell で、
vertex-networking-vpcVPC ネットワークに、VPN に使用する Cloud Router を作成します。gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001onprem-dataservice-vpcVPC ネットワークに、VPN に使用する Cloud Router を作成します。gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002vertex-networking-vpcVPC ネットワークに、Cloud NAT に使用する Cloud Router を作成します。gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Cloud Router で Cloud NAT ゲートウェイを構成します。
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1onprem-dataservice-vpcVPC ネットワークに、Cloud NAT に使用する Cloud Router を作成します。gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1Cloud Router で Cloud NAT ゲートウェイを構成します。
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Google Cloud コンソールで、[Cloud Router] ページに移動します。
[Cloud Router] リストで、次のルーターが作成されていることを確認します。
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
新しい値を表示するには、 Google Cloud コンソールのブラウザタブの更新が必要となる場合があります。
[Cloud Router] リストで
cloud-router-us-central1-vertex-natをクリックします。[ルーターの詳細] ページで、
cloud-nat-us-central1Cloud NAT ゲートウェイが作成されていることを確認します。戻る矢印 をクリックして、[Cloud Router] ページに戻ります。
[Cloud Router] リストで
cloud-router-us-central1-onprem-natをクリックします。[ルーターの詳細] ページで、
cloud-nat-us-central1-on-premCloud NAT ゲートウェイが作成されていることを確認します。
VPN トンネルを作成する
Cloud Shell で、
vertex-networking-vpcネットワークに VPN トンネル(vertex-networking-vpc-tunnel0)を作成します。gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0vertex-networking-vpcネットワークに、vertex-networking-vpc-tunnel1という VPN トンネルを作成します。gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1onprem-dataservice-vpcネットワークに、onprem-dataservice-vpc-tunnel0という VPN トンネルを作成します。gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0onprem-dataservice-vpcネットワークに、onprem-dataservice-vpc-tunnel1という VPN トンネルを作成します。gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Google Cloud コンソールで、[VPN] ページに移動します。
VPN トンネルのリストで、4 つの VPN トンネルが作成されていることを確認します。
BGP セッションを確立する
Cloud Router は、Border Gateway Protocol(BGP)を使用して、VPC ネットワーク(この場合は vertex-networking-vpc)とオンプレミス ネットワーク(onprem-dataservice-vpc で表される)間のルートを交換します。Cloud Router で、オンプレミス ルーターのインターフェースと BGP ピアを構成します。インターフェースと BGP ピア構成は、BGP セッションを形成します。このセクションでは、vertex-networking-vpc に 2 つ、onprem-dataservice-vpc に 2 つの BGP セッションを作成します。
ルーター間のインターフェースと BGP ピアを構成すると、ルートの交換が自動的に開始されます。
vertex-networking-vpc の BGP セッションを確立する
Cloud Shell で、
vertex-networking-vpcネットワークにvertex-networking-vpc-tunnel0用の BGP インターフェースを作成します。gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1vertex-networking-vpcネットワークに、bgp-onprem-tunnel0の BGP ピアを作成します。gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1vertex-networking-vpcネットワークに、vertex-networking-vpc-tunnel1の BGP インターフェースを作成します。gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1vertex-networking-vpcネットワークに、bgp-onprem-tunnel1の BGP ピアを作成します。gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
onprem-dataservice-vpc の BGP セッションを確立する
onprem-dataservice-vpcネットワークに、onprem-dataservice-vpc-tunnel0の BGP インターフェースを作成します。gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1onprem-dataservice-vpcネットワークに、bgp-vertex-networking-vpc-tunnel0の BGP ピアを作成します。gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1onprem-dataservice-vpcネットワークに、onprem-dataservice-vpc-tunnel1の BGP インターフェースを作成します。gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1onprem-dataservice-vpcネットワークに、bgp-vertex-networking-vpc-tunnel1の BGP ピアを作成します。gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
BGP セッションの作成を確認する
Google Cloud コンソールで、[VPN] ページに移動します。
VPN トンネルのリストで、各トンネルの [BGP セッションのステータス] 列の値が「BGP セッションを構成」から「BGP が確立されました」に変更されていることを確認します。新しい値を表示するには、 Google Cloud コンソールのブラウザタブの更新が必要となる場合があります。
onprem-dataservice-vpc の学習されたルートを検証する
Google Cloud コンソールで、[VPC ネットワーク] ページに移動します。
VPC ネットワークのリストで
onprem-dataservice-vpcをクリックします。[ルート] タブをクリックします。
[リージョン] リストで [us-central1(アイオワ)] を選択し、[表示] をクリックします。
[送信先 IP 範囲] 列で、
pipeline-networking-subnet1サブネットの IP 範囲(10.0.0.0/24)が 2 回表示されていることを確認します。両方のエントリを表示するには、 Google Cloud コンソールのブラウザタブを更新する必要があります。
vertex-networking-vpc の学習されたルートを検証する
戻る矢印 をクリックして、[VPC ネットワーク] ページに戻ります。
VPC ネットワークのリストで
vertex-networking-vpcをクリックします。[ルート] タブをクリックします。
[リージョン] リストで [us-central1(アイオワ)] を選択し、[表示] をクリックします。
[送信先 IP 範囲] 列で、
onprem-dataservice-vpc-subnet1サブネットの IP 範囲(172.16.10.0/24)が 2 回表示されていることを確認します。
Google API 用の Private Service Connect エンドポイントを作成する
このセクションでは、オンプレミス ネットワークから Agent Platform Pipelines REST API にアクセスするために使用する Google API 用に、Private Service Connect エンドポイントを作成します。
Cloud Shell で、Google API へのアクセスに使用するコンシューマー エンドポイントの IP アドレスを予約します。
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcエンドポイントを Google API およびサービスに接続する転送ルールを作成します。
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
vertex-networking-vpc のカスタムルート アドバタイズを作成する
このセクションでは、vertex-networking-vpc-router1(vertex-networking-vpc の Cloud Router)用にカスタム ルート アドバタイズを作成して、PSC エンドポイントの IP アドレスを onprem-dataservice-vpc VPC ネットワークにアドバタイズします。
Google Cloud コンソールで、[Cloud Router] ページに移動します。
[Cloud Router] リストで
vertex-networking-vpc-router1をクリックします。[ルーターの詳細] ページで、[ 編集] をクリックします。
[アドバタイズされたルート] セクションの [ルート] で、[カスタムルートの作成] を選択します。
[Cloud Router に表示されるすべてのサブネットにアドバタイズする] チェックボックスをオンにして、Cloud Router に利用可能なサブネットのアドバタイジングを継続します。このオプションを有効にすると、デフォルトのアドバタイズ モードでの Cloud Router の動作が模倣されます。
[カスタムルートの追加] をクリックします。
[ソース] で [カスタム IP 範囲] を選択します。
[IP アドレス範囲] には、次の IP アドレスを入力します。
192.168.0.1[説明] には、次のテキストを入力します。
Custom route to advertise Private Service Connect endpoint IP address[完了] をクリックし、[保存] をクリックします。
onprem-dataservice-vpc がアドバタイズされたルートを学習したことを確認する
Google Cloud コンソールで、[ルート] ページに移動します。
[適用されているルート] タブで、次の操作を行います。
- [ネットワーク] には [
onprem-dataservice-vpc] を選択します。 - [リージョン] には
us-central1 (Iowa)を選択します。 - [表示] をクリックします。
ルートのリストで、名前が
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0で始まるエントリが 2 つ、onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1で始まるエントリが 2 つあることを確認します。これらのエントリがすぐに表示されない場合は、数分待ってから、 Google Cloud コンソールのブラウザタブを更新してください。
2 つのエントリの [送信先 IP 範囲] が
192.168.0.1/32で、2 つのエントリの [送信先 IP 範囲] が10.0.0.0/24であることを確認します。
- [ネットワーク] には [
onprem-dataservice-vpc に VM インスタンスを作成する
このセクションでは、オンプレミス データサービス ホストをシミュレートする VM インスタンスを作成します。Compute Engine と IAM のベスト プラクティスに従って、この VM は Compute Engine のデフォルトのサービス アカウントではなく、ユーザー管理のサービス アカウントを使用します。
VM インスタンスのユーザー管理サービス アカウントを作成する
Cloud Shell で、次のコマンドを実行します。ここで、PROJECT_ID はプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}onprem-user-managed-saという名前のサービス アカウントを作成します。gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"サービス アカウントに Agent Platform ユーザー(
roles/aiplatform.user)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Gemini Enterprise Agent Platform 閲覧者(
roles/aiplatform.viewer)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"Filestore 編集者(
roles/file.editor)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"サービス アカウント管理者(
roles/iam.serviceAccountAdmin)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"サービス アカウント ユーザー(
roles/iam.serviceAccountUser)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"Artifact Registry 読み取り(
roles/artifactregistry.reader)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"Storage オブジェクト管理者(
roles/storage.objectAdmin)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"Logging 管理者(
roles/logging.admin)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
on-prem-dataservice-host VM インスタンスを作成する
作成する VM インスタンスには外部 IP アドレスがなく、インターネット経由の直接アクセスは許可されません。VM への管理者権限を有効にするには、Identity-Aware Proxy(IAP)TCP 転送を使用します。
Cloud Shell で、
on-prem-dataservice-hostVM インスタンスを作成します。gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"IAP が VM インスタンスに接続できるようにするファイアウォール ルールを作成します。
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
PSC エンドポイントを指すように /etc/hosts ファイルを更新する
このセクションでは、/etc/hosts ファイルに、パブリック サービス エンドポイント(us-central1-aiplatform.googleapis.com)に送信されたリクエストを PSC エンドポイント(192.168.0.1)にリダイレクトする行を追加します。
Cloud Shell で、IAP を使用して
on-prem-dataservice-hostVM インスタンスにログインします。gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapon-prem-dataservice-hostVM インスタンスで、テキスト エディタ(vimやnanoなど)を使用して/etc/hostsファイルを開きます。次に例を示します。sudo vim /etc/hosts次の行をファイルに追加します。
192.168.0.1 us-central1-aiplatform.googleapis.comこの行では、PSC エンドポイントの IP アドレス(
192.168.0.1)を Gemini Enterprise Agent Platform Google API の完全修飾ドメイン名(us-central1-aiplatform.googleapis.com)に割り当てています。編集されたファイルは、次のようになります。
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by Google次のようにファイルを保存します。
vimを使用している場合は、Escキーを押してから、「:wq」と入力してファイルを保存し、終了します。nanoを使用している場合は、「Control+O」と入力してEnterを押してファイルを保存し、「Control+X」と入力して終了します。
次のように Agent Platform API エンドポイントに対して ping を実行します。
ping us-central1-aiplatform.googleapis.compingコマンドでは、次の出力が返されます。192.168.0.1は、PSC エンドポイントの IP アドレスです。PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.「
Control+C」と入力してpingを終了します。exitと入力してon-prem-dataservice-hostVM インスタンスを終了し、Cloud Shell プロンプトに戻ります。
Filestore インスタンスのネットワークを構成する
このセクションでは、Filestore インスタンスを作成してネットワーク ファイル システム(NFS)共有としてマウントする準備として、VPC ネットワークのプライベート サービス アクセスを有効にします。このセクションと次のセクションで行う作業の詳細については、カスタム トレーニング用の NFS 共有をマウントすると VPC ネットワーク ピアリングを設定するをご覧ください。
VPC ネットワークでプライベート サービス アクセスを有効にする
このセクションでは、サービス ネットワーキング接続を作成し、これを使用して、VPC ネットワーク ピアリングを介して onprem-dataservice-vpc VPC ネットワークへのプライベート サービス アクセスを有効にします。
Cloud Shell で、
gcloud compute addresses createを使用して予約済みの IP アドレス範囲を設定します。gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpcgcloud services vpc-peerings connectを使用して、onprem-dataservice-vpcVPC ネットワークと Google のサービス ネットワーキングの間にピアリング接続を確立します。gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpcVPC ネットワーク ピアリングを更新して、カスタム学習ルートのインポートとエクスポートを有効にします。
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routesGoogle Cloud コンソールで [VPC ネットワーク ピアリング] ページに移動します。
VPC ピアリングのリストで、
servicenetworking.googleapis.comとonprem-dataservice-vpcVPC ネットワーク間のピアリングのエントリがあることを確認します。
filestore-subnet のカスタムルート アドバタイズを作成する
Google Cloud コンソールで、[Cloud Router] ページに移動します。
[Cloud Router] リストで
onprem-dataservice-vpc-router1をクリックします。[ルーターの詳細] ページで、[ 編集] をクリックします。
[アドバタイズされたルート] セクションの [ルート] で、[カスタムルートの作成] を選択します。
[Cloud Router に表示されるすべてのサブネットにアドバタイズする] チェックボックスをオンにして、Cloud Router に利用可能なサブネットのアドバタイジングを継続します。このオプションを有効にすると、デフォルトのアドバタイズ モードでの Cloud Router の動作が模倣されます。
[カスタムルートの追加] をクリックします。
[ソース] で [カスタム IP 範囲] を選択します。
[IP アドレス範囲] には、次の IP アドレス範囲を入力します。
10.243.208.0/24[説明] には、次のテキストを入力します。
Filestore reserved IP address range[完了] をクリックし、[保存] をクリックします。
onprem-dataservice-vpc ネットワークに Filestore インスタンスを作成する
VPC ネットワークでプライベート サービス アクセスを有効にしたら、Filestore インスタンスを作成し、カスタム トレーニング ジョブ用に NFS 共有としてインスタンスをマウントします。これにより、トレーニング ジョブがローカルに存在するかのようにリモート ファイルにアクセスできるようになり、高スループットと低レイテンシが実現します。
Filestore インスタンスを作成する
Google Cloud コンソールで、[Filestore インスタンス] ページに移動します。
[インスタンスを作成] をクリックし、次のようにインスタンスを構成します。
[インスタンス ID] を次のように設定します。
image-data-instance[インスタンスのタイプ] を [基本] に設定します。
[ストレージの種類] を [HDD] に設定します。
[容量の割り当て] を 1
TiBに設定します。[リージョン] を us-central1、[ゾーン] を us-central1-c に設定します。
[VPC ネットワーク] を
onprem-dataservice-vpcに設定します。[割り振られている IP 範囲] を [既存の割り振り済みの IP 範囲を使用する] に設定し、
filestore-subnetを選択します。[ファイル共有の名前] を次のように設定します。
vol1[アクセス制御] を [VPC ネットワーク上のすべてのクライアントにアクセス権を付与する] に設定します。
[作成] をクリックします。
新しい Filestore インスタンスの IP アドレスをメモしておきます。新しいインスタンスを表示するには、 Google Cloud コンソールのブラウザタブの更新が必要となる場合があります。
Filestore のファイル共有をマウントする
Cloud Shell で、次のコマンドを実行します。ここで、PROJECT_ID はプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}on-prem-dataservice-hostVM インスタンスにログインします。gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapVM インスタンスに NFS パッケージをインストールします。
sudo apt-get update -y sudo apt-get -y install nfs-commonFilestore ファイル共有のマウント ディレクトリを作成します。
sudo mkdir -p /mnt/nfsファイル共有をマウントします。FILESTORE_INSTANCE_IP は Filestore インスタンスの IP アドレスに置き換えます。
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfs接続がタイムアウトした場合は、Filestore インスタンスの正しい IP アドレスを指定しているかを確認します。
次のコマンドを実行して、NFS マウントが正常に完了したことを確認します。
df -h結果に
/mnt/nfsファイル共有が表示されていることを確認します。Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfs権限を変更し、ファイル共有にアクセスできるようにします。
sudo chmod go+rw /mnt/nfs
データセットをファイル共有にダウンロードする
on-prem-dataservice-hostVM インスタンスで、データセットをファイル共有にダウンロードします。gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursiveダウンロードには数分かかります。
次のコマンドを実行して、データセットが正常にコピーされたことを確認します。
sudo du -sh /mnt/nfs想定される出力は次のとおりです。
104M /mnt/nfsexitと入力してon-prem-dataservice-hostVM インスタンスを終了し、Cloud Shell プロンプトに戻ります。
パイプラインのステージング バケットを作成する
Agent Platform Pipelines は、Cloud Storage を使用してパイプライン実行のアーティファクトを保存します。パイプラインを実行する前に、パイプライン実行をステージングするための Cloud Storage バケットを作成する必要があります。
Cloud Shell で、Cloud Storage バケットを作成します。
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
Vertex AI Workbench のユーザー管理サービス アカウントを作成する
Cloud Shell で、サービス アカウントを作成します。
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"サービス アカウントに Agent Platform ユーザー(
roles/aiplatform.user)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Artifact Registry 管理者(
artifactregistry.admin)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"ストレージ管理者(
storage.admin)ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
Python トレーニング アプリケーションを作成する
このセクションでは、Vertex AI Workbench インスタンスを作成し、それを使用して Python カスタム トレーニング アプリケーション パッケージを作成します。
Vertex AI Workbench インスタンスを作成する
Google Cloud コンソールで、[Vertex AI Workbench] ページの [インスタンス] タブに移動します。
[新規作成] をクリックし、[詳細オプション] をクリックします。
[新しいインスタンス] ページが開きます。
[新しいインスタンス] ページの [詳細] セクションで、新しいインスタンスについて次の情報を入力し、[続行] をクリックします。
名前: PROJECT_ID をプロジェクト ID に置き換えて、次のように入力します。
pipeline-tutorial-PROJECT_IDリージョン: [us-central1] を選択します。
ゾーン: 「us-central1-a」を選択します。
[Dataproc Serverless インタラクティブ セッションを有効にする] チェックボックスをオフにします。
[環境] セクションで、[続行] をクリックします。
[マシンタイプ] セクションで、以下を指定して [続行] をクリックします。
- マシンタイプ: [N1] を選択し、[マシンタイプ] メニューから
n1-standard-4を選択します。 Shielded VM: 次のチェックボックスをオンにします。
- セキュアブート
- 仮想トラステッド プラットフォーム モジュール(vTPM)
- 整合性モニタリング
- マシンタイプ: [N1] を選択し、[マシンタイプ] メニューから
[ディスク] セクションで Google-managed encryption key が選択されていることを確認して、[続行] をクリックします。
[ネットワーキング] セクションで次の設定を行い、[続行] をクリックします。
ネットワーキング: [このプロジェクトのネットワーク] を選択し、次の操作を行います。
[ネットワーク] フィールドで、[vertex-networking-vpc] を選択します。
[サブネットワーク] フィールドで、[pipeline-networking-subnet1] を選択します。
[外部 IP アドレスを割り当て] チェックボックスをオフにします。外部 IP アドレスを割り当てると、インスタンスはインターネットまたは他の VPC ネットワークからの未承諾通信を受信できなくなります。
[プロキシ アクセスを許可] チェックボックスをオンにします。
[IAM とセキュリティ] セクションで、以下を指定して、[続行] をクリックします。
IAM とセキュリティ: インスタンスの JupyterLab インターフェースへのアクセス権を単一のユーザーに付与するには、次の操作を行います。
- [Service account] を選択します。
- [Compute Engine のデフォルトのサービス アカウントを使用する] チェックボックスをオフにします。Compute Engine のデフォルトのサービス アカウント(つまり指定した単一のユーザー)には、プロジェクトの編集者ロール(
roles/editor)が付与される可能性があるため、このステップは重要です。 [サービス アカウントのメールアドレス] フィールドに、次のように入力します。PROJECT_ID は、プロジェクト ID に置き換えます。
workbench-sa@PROJECT_ID.iam.gserviceaccount.com(これは、先ほど作成したカスタム サービス アカウントのメールアドレスです)このサービス アカウントの権限は制限されています。
アクセス権の付与の詳細については、Vertex AI Workbench インスタンスの JupyterLab インターフェースへのアクセスを管理するをご覧ください。
セキュリティ オプション: 次のチェックボックスをオフにします。
- インスタンスに対するルートアクセス
次のチェックボックスをオンにします。
- nbconvert:
nbconvertを使用すると、ユーザーはノートブック ファイルを別の形式(HTML、PDF、LaTeX など)でエクスポートして、ダウンロードできます。この設定は、Google Cloud 生成 AI GitHub リポジトリの一部のノートブックで必要になります。
以下のチェックボックスをオフにします。
- ファイルのダウンロード
本番環境以外の場合は、次のチェックボックスをオンにします。
- ターミナル アクセス: JupyterLab ユーザー インターフェースからインスタンスへのターミナル アクセスが可能になります。
[システムの状態] セクションで [環境の自動アップグレード] のチェックをはずし、次の情報を入力します。
[レポート] で、次のチェックボックスをオンにします。
- システムの状態を報告
- Cloud Monitoring にカスタム指標を報告する
- Cloud Monitoring をインストールする
- 必要な Google ドメインの DNS ステータスを報告する
[作成] をクリックし、Vertex AI Workbench インスタンスが作成されるまで数分待ちます。
Vertex AI Workbench インスタンスでトレーニング アプリケーションを実行する
Google Cloud コンソールで、[Gemini Enterprise Agent Platform Workbench] ページの [インスタンス] タブに移動します。
Vertex AI Workbench インスタンス名(
pipeline-tutorial-PROJECT_ID)の横にある [JupyterLab を開く] をクリックします(PROJECT_ID はプロジェクト ID です)。JupyterLab で Vertex AI Workbench インスタンスが開きます。
[ファイル > 新規 > ターミナル] を選択します。
(Cloud Shell ではなく)JupyterLab ターミナルで、プロジェクトの環境変数を定義します。PROJECT_ID は、プロジェクト ID で置き換えてください。
projectid=PROJECT_ID(引き続き JupyterLab ターミナルで)トレーニング アプリケーションの親ディレクトリを作成します。
mkdir fungi_training_package mkdir fungi_training_package/trainer[ File Browser] で、
fungi_training_packageフォルダをダブルクリックし、続いてtrainerフォルダをダブルクリックします。[ File Browser] で、空のファイルリスト([Name] の見出しの下)を右クリックし、[New file] を選択します。
新しいファイルを右クリックして、[Rename file] を選択します。
ファイルの名前を
untitled.txtからtask.pyに変更します。task.pyファイルをダブルクリックして開きます。次のコードを
task.pyにコピーします。# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)[File] > [Save Python file] を選択します。
JupyterLab ターミナルで、各サブディレクトリに
__init__.pyファイルを作成し、パッケージにします。touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.py[ File Browser] で、
fungi_training_packageフォルダをダブルクリックします。[File] > [New] > [Python file] を選択します。
新しいファイルを右クリックして、[Rename file] を選択します。
ファイルの名前を
untitled.pyからsetup.pyに変更します。setup.pyファイルをダブルクリックして開きます。次のコードを
setup.pyにコピーします。from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )[File] > [Save Python file] を選択します。
ターミナルで、
fungi_training_packageディレクトリに移動します。cd fungi_training_packagesdistコマンドを使用して、トレーニング アプリケーションのソース ディストリビューションを作成します。python setup.py sdist --formats=gztar親ディレクトリに移動します。
cd ..正しいディレクトリにいることを確認します。
pwd出力は次のようになります。
/home/jupyterPython パッケージをステージング バケットにコピーします。
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/ステージング バケットにパッケージが含まれていることを確認します。
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_package次のように出力されます。
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
Agent Platform Pipelines のサービス ネットワーキング接続を作成する
このセクションでは、VPC ネットワーク ピアリングを介して vertex-networking-vpc VPC ネットワークに接続されたプロデューサー サービスを確立するために使用されるサービス ネットワーキング接続を作成します。詳細については、VPC ネットワーク ピアリングをご覧ください。
Cloud Shell で、次のコマンドを実行します。ここで、PROJECT_ID はプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute addresses createを使用して予約済み IP アドレス範囲を設定します。gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpcgcloud services vpc-peerings connectを使用して、vertex-networking-vpcVPC ネットワークと Google のサービス ネットワーキングの間にピアリング接続を確立します。gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpcVPC ピアリング接続を更新して、カスタム学習ルートのインポートとエクスポートを有効にします。
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
pipeline-networking Cloud Router からパイプライン サブネットをアドバタイズする
Google Cloud コンソールで、[Cloud Router] ページに移動します。
[Cloud Router] リストで
vertex-networking-vpc-router1をクリックします。[ルーターの詳細] ページで、[ 編集] をクリックします。
[カスタムルートの追加] をクリックします。
[ソース] で [カスタム IP 範囲] を選択します。
[IP アドレス範囲] には、次の IP アドレス範囲を入力します。
192.168.10.0/24[説明] には、次のテキストを入力します。
Agent Platform Pipelines reserved subnet[完了] をクリックし、[保存] をクリックします。
パイプライン テンプレートを作成して Artifact Registry にアップロードする
このセクションでは、Kubeflow Pipelines(KFP)パイプライン テンプレートを作成してアップロードします。このテンプレートには、1 人または複数のユーザーが複数回再利用できるワークフロー定義が含まれています。
パイプラインを定義してコンパイルする
Jupyterlab の [ File Browser] で、最上位のフォルダをダブルクリックします。
[File] > [New] > [Notebook] の順に選択します。
[Select Kernel] メニューから
Python 3 (ipykernel)を選択し、[Select] をクリックします。新しいノートブックのセルで次のコマンドを実行して、
pipの最新バージョンがあることを確認します。!python -m pip install --upgrade pip次のコマンドを実行して、Python パッケージ インデックス(PyPI)から Google Cloud パイプライン コンポーネント SDK をインストールします。
!pip install --upgrade google-cloud-pipeline-componentsインストールが完了したら、[Kernel] > [Restart Kernel] の順に選択してカーネルを再起動し、ライブラリをインポートできることを確認します。
新しいノートブックのセルで次のコードを実行して、パイプラインを定義します。
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )新しいノートブックのセルで次のコードを実行して、パイプライン定義をコンパイルします。
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )[ File Browser] で、
pipeline_config.yamlという名前のファイルがファイルリストに表示されます。
Artifact Registry リポジトリを作成する
新しいノートブックのセルで次のコードを実行して、KFP タイプのアーティファクト リポジトリを作成します。
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
パイプライン テンプレートを Artifact Registry にアップロードする
このセクションでは、Kubeflow Pipelines SDK レジストリ クライアントを構成し、コンパイルされたパイプライン テンプレートを JupyterLab ノートブックから Artifact Registry にアップロードします。
JupyterLab ノートブックで次のコードを実行してパイプライン テンプレートをアップロードします。ここで、PROJECT_ID はプロジェクト ID に置き換えます。
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})テンプレートがアップロードされたことを確認するため、 Google Cloud コンソールで Agent Platform Pipelines テンプレートに移動します。
[リポジトリを選択] ペインを開くには、[リポジトリを選択] をクリックします。
リポジトリ リストで、作成したリポジトリ(
fungi-repo)をクリックし、[選択] をクリックします。パイプライン(
custom-image-classification-pipeline)がリストに表示されていることを確認します。
オンプレミスからパイプライン実行をトリガーする
パイプライン テンプレートとトレーニング パッケージの準備ができたので、このセクションでは、cURL を使用してオンプレミス アプリケーションからパイプラインの実行をトリガーします。
パイプライン パラメータを指定する
JupyterLab ノートブックで、次のコマンドを実行してパイプライン テンプレート名を確認します。
print (TEMPLATE_NAME)返されるテンプレート名は次のとおりです。
custom-image-classification-pipeline次のコマンドを実行して、パイプライン テンプレートのバージョンを取得します。
print (VERSION_NAME)返されるパイプライン テンプレートのバージョン名は次のようになります。
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7バージョン名の文字列全体をメモしておきます。
Cloud Shell で、次のコマンドを実行します。ここで、PROJECT_ID はプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}on-prem-dataservice-hostVM インスタンスにログインします。gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapon-prem-dataservice-hostVM インスタンスで、テキスト エディタ(vimやnanoなど)を使用してrequest_body.jsonファイルを作成します。次に例を示します。sudo vim request_body.jsonrequest_body.jsonファイルに次のテキストを追加します。{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }次の値を置き換えます。
- PROJECT_ID: プロジェクト ID
- PROJECT_NUMBER: プロジェクト番号。これはプロジェクト ID とは異なります。プロジェクト番号は、Google Cloud コンソールでプロジェクトの [プロジェクトの設定] ページを表示すると確認できます。
- FILESTORE_INSTANCE_IP: Filestore インスタンスの IP アドレス(
10.243.208.2など)。これは、インスタンスの Filestore インスタンス ページで確認できます。 - VERSION_NAME: ステップ 2 でメモしたパイプライン テンプレートのバージョン名(
sha256:...)。
次のようにファイルを保存します。
vimを使用している場合は、Escキーを押してから、「:wq」と入力してファイルを保存し、終了します。nanoを使用している場合は、「Control+O」と入力してEnterを押してファイルを保存し、「Control+X」と入力して終了します。
テンプレートからパイプライン実行を送信する
on-prem-dataservice-hostVM インスタンスで、次のコマンドを実行します。PROJECT_ID はプロジェクト ID に置き換えます。curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobs出力は長いですが、主に確認する必要があるのは次の行です。これは、サービスがパイプラインの実行を準備していることを示します。
"state": "PIPELINE_STATE_PENDING"パイプラインの実行全体には約 45~50 分かかります。
Google Cloud コンソールの [Gemini Enterprise Agent Platform] セクションで、[パイプライン] ページの [実行] タブに移動します。
パイプライン実行の実行名(
custom-image-classification-pipeline)をクリックします。パイプラインの実行ページが表示され、パイプラインのランタイム グラフが表示されます。パイプラインのサマリーが [パイプライン実行分析] ペインに表示されます。
ログの表示方法や、Vertex ML Metadata を使用してパイプラインのアーティファクトの詳細を確認する方法など、ランタイム グラフに表示される情報を理解するには、パイプライン結果の可視化と分析をご覧ください。
クリーンアップ
このチュートリアルで使用したリソースについて Google Cloud アカウントに課金されることのないよう、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクト内の個々のリソースを削除するには、次のように操作します。
次の手順ですべてのパイプライン実行を削除します。
Google Cloud コンソールの [Gemini Enterprise Agent Platform] セクションで、[パイプライン] ページの [実行] タブに移動します。
削除するパイプライン実行を選択し、削除アイコン をクリックします。
次の手順でパイプライン テンプレートを削除します。
[Gemini Enterprise Agent Platform] セクションで、[パイプライン] ページの [テンプレート] タブに移動します。
custom-image-classification-pipelineパイプライン テンプレートの横にある操作アイコン をクリックし、[削除] を選択します。
次の手順で Artifact Registry からリポジトリを削除します。
[Artifact Registry] ページで、[リポジトリ] タブに移動します。
fungi-repoリポジトリを選択し、削除アイコン をクリックします。
次のように、エンドポイントからモデルのデプロイを解除します。
[Gemini Enterprise Agent Platform] セクションで、[オンライン予測] ページの [エンドポイント] タブに移動します。
[
fungi-image-endpoint] をクリックして、エンドポイントの詳細ページに移動します。モデル(
fungi-image-model)の行で、操作アイコン をクリックし、[エンドポイントからモデルのデプロイを解除] を選択します。[エンドポイントからモデルのデプロイを解除] ダイアログで [デプロイ解除] をクリックします。
次の手順でエンドポイントを削除します。
[Gemini Enterprise Agent Platform] セクションで、[オンライン予測] ページの [エンドポイント] タブに移動します。
fungi-image-endpointを選択し、[削除] をクリックします。
次のようにモデルを削除します。
[Model Registry] ページに移動します。
モデル(
fungi-image-model)の行で、操作アイコン をクリックし、[モデルを削除] を選択します。
次の手順でステージング バケットを削除します。
[Cloud Storage] ページに移動します。
pipelines-staging-bucket-PROJECT_ID(PROJECT_ID はプロジェクト ID)を選択し、削除アイコン をクリックします。
次の手順で Vertex AI Workbench インスタンスを削除します。
[Gemini Enterprise Agent Platform] セクションで、[ワークベンチ] ページの [インスタンス] タブに移動します。
pipeline-tutorial-PROJECT_IDVertex AI Workbench インスタンス(PROJECT_ID はプロジェクト ID)を選択し、削除アイコン をクリックします。
次の手順で Compute Engine VM インスタンスを削除します。
[Compute Engine] ページに移動します。
on-prem-dataservice-hostVM インスタンスを選択し、削除アイコン をクリックします。
次の手順で VPN トンネルを削除します。
[VPN] ページに移動します。
[VPN] ページで、[Cloud VPN トンネル] タブをクリックします。
VPN トンネルのリストで、このチュートリアルで作成した 4 つの VPN トンネルを選択し、削除アイコン をクリックします。
次の手順で HA VPN ゲートウェイを削除します。
[VPN] ページで、[Cloud VPN ゲートウェイ] タブをクリックします。
VPN ゲートウェイのリストで
onprem-vpn-gw1をクリックします。[Cloud VPN ゲートウェイの詳細] ページで、VPN ゲートウェイの削除アイコン をクリックします。
必要に応じて、矢印 をクリックして VPN ゲートウェイのリストに戻り、
vertex-networking-vpn-gw1をクリックします。[Cloud VPN ゲートウェイの詳細] ページで、VPN ゲートウェイの削除アイコン をクリックします。
次の手順で Cloud Router を削除します。
[Cloud Router] ページに移動します。
Cloud Router のリストで、このチュートリアルで作成した 4 つのルーターを選択します。
削除アイコン をクリックして、ルーターを削除します。
これにより、Cloud Router に接続されている 2 つの Cloud NAT ゲートウェイも削除されます。
次の手順で、
vertex-networking-vpcVPC ネットワークとonprem-dataservice-vpcVPC ネットワークへのサービス ネットワーキング接続を削除します。[VPC ネットワーク ピアリング] ページに移動します。
[
servicenetworking-googleapis-com] を選択します。接続を削除するには、削除アイコン をクリックします。
次の手順で
vertex-networking-vpcVPC ネットワークのpscvertex転送ルールを削除します。[ロード バランシング] ページの [フロントエンド] タブに移動します。
転送ルールのリストで
pscvertexをクリックします。[グローバル転送ルールの詳細] ページで、削除アイコン をクリックします。
次の手順で Filestore インスタンスを削除します。
[Filestore] ページに移動します。
image-data-instanceインスタンスを選択します。インスタンスを削除するには、操作アイコン をクリックし、[インスタンスを削除] をクリックします。
次の手順で VPC ネットワークを削除します。
[VPC ネットワーク] ページに移動します。
VPC ネットワークのリストで
onprem-dataservice-vpcをクリックします。[VPC ネットワークの詳細] ページで、VPC ネットワークを削除アイコン をクリックします。
ネットワークを削除すると、そのサブネットワーク、ルート、ファイアウォール ルールも削除されます。
VPC ネットワークのリストで
vertex-networking-vpcをクリックします。[VPC ネットワークの詳細] ページで、VPC ネットワークを削除アイコン をクリックします。
次のように、
workbench-saサービス アカウントとonprem-user-managed-saサービス アカウントを削除します。[サービス アカウント] ページに移動します。
onprem-user-managed-saサービス アカウントとworkbench-saサービス アカウントを選択し、(削除)をクリックします。
次のステップ
Agent Platform Pipelines を使用して、ML モデルのビルドとデプロイのプロセスをオーケストレートする方法について学習する。
deFungi データセットについて学習する。