Addestramento del modello con codice di pre-elaborazione dei dati predefinito: notebook
Mantieni tutto organizzato con le raccolte
Salva e classifica i contenuti in base alle tue preferenze.
In qualità di data scientist, questo è un workflow comune: addestrare un modello
localmente (nel mio notebook), registrare i parametri, registrare le metriche delle serie temporali di addestramento in Vertex AI TensorBoard,
e registrare le metriche di valutazione.
In qualità di data scientist, voglio essere in grado di riutilizzare il codice di pre-elaborazione dei dati scritto da altri membri della mia azienda per semplificare e standardizzare tutte le complesse operazioni di data wrangling che eseguiamo. Voglio essere in grado di:
Utilizzare una libreria di pre-elaborazione dei dati Python per liberare spazio in un set di dati in memoria (un DataFrame Pandas) in un notebook.
Addestrare un modello utilizzando Keras (sempre in un notebook).
Notebook: sperimentazione del modello con dati pre-elaborati
Nel notebook "Build Vertex AI Experiments lineage for custom training" (Crea derivazione di Vertex AI Experiments per l'addestramento personalizzato) scoprirai come integrare il codice di pre-elaborazione in Vertex AI Experiments.
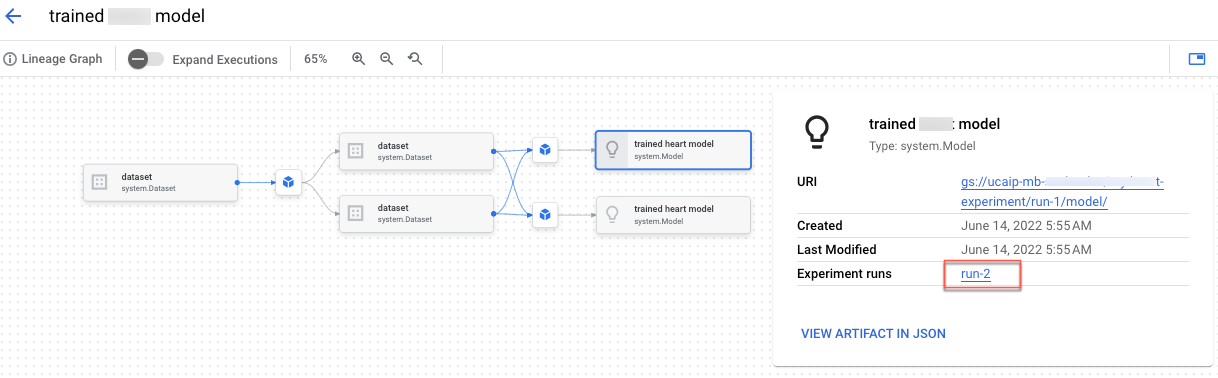
Inoltre, creerai la derivazione dell'esperimento che ti consente di registrare, analizzare, eseguire il debug e controllare i metadati e gli artefatti prodotti durante il percorso di ML.
Puoi visualizzare la derivazione degli artefatti nella Google Cloud console.
[[["Facile da capire","easyToUnderstand","thumb-up"],["Il problema è stato risolto","solvedMyProblem","thumb-up"],["Altra","otherUp","thumb-up"]],[["Difficile da capire","hardToUnderstand","thumb-down"],["Informazioni o codice di esempio errati","incorrectInformationOrSampleCode","thumb-down"],["Mancano le informazioni o gli esempi di cui ho bisogno","missingTheInformationSamplesINeed","thumb-down"],["Problema di traduzione","translationIssue","thumb-down"],["Altra","otherDown","thumb-down"]],["Ultimo aggiornamento 2026-05-31 UTC."],[],[]]