
This document describes how you can configure a LangGraph ReAct agent or a generative AI agent built with the Agent Development Kit (ADK) framework to send multimodal prompts and responses to your Google Cloud project. It also describes how you can view, analyze, and evaluate stored multimodal media:
Use the Trace Explorer page to view individual prompts or responses or to view an entire conversation. You have options to view the media in a rendered or raw format. To learn more, see View multimodal prompts and responses.
Use BigQuery services to analyze the multimodal data. For example, you might use a function like
AI.GENERATEto summarize a conversation. To learn more, see Analyze prompt-response data by using BigQuery.Use the Vertex AI SDK to evaluate a conversation. For example, you might use Google Colaboratory to perform sentiment analysis. To learn more, see Run evaluations on the prompt-response data with Colaboratory.
When you collect multimodal prompts and responses, the full contents of your end user's prompts and responses are collected. This prompt and response data is stored in a Cloud Storage bucket. For details about how to manage the storage bucket, including controlling access or deleting data, see the Cloud Storage documentation.
You can use products like Model Armor and Sensitive Data Protection to manage sensitive data that might be in the prompts and responses.
Types of media that you can collect
You can collect the following types of media:
- Audio.
- Documents.
- Images.
- Plain text and Markdown-formatted text.
- Video.
Prompts and responses can include inline content and links. Links can go to either public resources or to Cloud Storage buckets.
Where prompts and responses are stored
When your agentic application creates or receives either prompts or responses, the SDK your application uses invokes OpenTelemetry instrumentation. This instrumentation formats the prompts and responses, and the multimodal data that they might contain, according to version 1.37.0 of the OpenTelemetry GenAI semantic conventions. Higher versions are also supported.
Next, the OpenTelemetry instrumentation does the following:
It creates object identifiers for prompts and response data and then writes that data to your Cloud Storage bucket. The entries in your Cloud Storage bucket are saved in the JSON Lines format.
It sends log and trace data to your Google Cloud project, where the Logging and Trace services ingest and store the data. The OpenTelemetry semantic conventions determine many of the attributes and fields attached to your log entries or to your trace spans.
When the OpenTelemetry instrumentation creates Cloud Storage bucket objects, it also writes a log entry that contains references to those objects. The following example shows part of a log entry that includes object references:
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system_instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }In the log entry example, notice the following:
- The label
"event.name": "gen_ai.client.inference.operation.details"indicates that the log entry contains references to Cloud Storage objects. - The labels whose keys include
gen_aieach reference an object in a Cloud Storage bucket. - All log entries that contain object references are written to the same
log, which is named
projects/my-project/logs/gen_ai.client.inference.operation.details.
To learn how to show log entries that contain object references, see the Find all log entries that reference prompts and responses section of this document.
- The label
Collect multimodal prompts and responses
The SDK your application uses automatically invokes OpenTelemetry to store prompts and responses, and to send log and trace data to your Google Cloud project. You don't need to modify your application. However, you need to configure your Google Cloud project and the SDK you are using.
To collect and view multimodal prompts and responses from an application, do the following:
Configure your project:
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI, Cloud Storage, Telemetry, Cloud Logging, and Cloud Trace APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles. Make sure that you have a Cloud Storage bucket. When necessary, create a Cloud Storage bucket.
We recommend that you do the following:
Create your Cloud Storage bucket in the same location as the log bucket that stores your application's log data. This configuration makes BigQuery queries more efficient.
Make sure that the storage class of your Cloud Storage bucket supports external tables. This capability lets you query prompts and responses with BigQuery. If you don't plan to use the default settings for a new Cloud Storage bucket, then before you create the bucket, review Create Cloud Storage external tables.
Set the retention period for your Cloud Storage bucket to match the retention period of the log bucket that stores your log entries. The default retention period for log data is 30 days. To learn how to set the retention period for your Cloud Storage bucket, see Bucket Lock.
-
To ensure that the service account your application uses has the necessary permissions to store prompts and responses and to write log, metric, and trace data, ask your administrator to grant the following IAM roles to the service account your application uses:
- Storage Object User (
roles/roles/storage.objectUser) on your storage bucket - Logs Writer (
roles/logging.logWriter) on your project - Monitoring Metric Writer (
roles/monitoring.metricWriter) on your project - Cloud Telemetry Traces Writer (
roles/telemetry.tracesWriter) on your project
The Storage Object User role includes the
storage.objects.createpermission. This permission lets your application write objects to your Cloud Storage bucket. These objects store the prompts and responses that your agentic application creates or receives. For more information, see Set and manage IAM policies on buckets. - Storage Object User (
-
Configure the SDK:
Install and upgrade the following dependencies:
ADK
google-adk>=1.16.0 opentelemetry-instrumentation-google-genai>=0.4b0 fsspec[gcs]==2025.10.0LangGraph
opentelemetry-instrumentation-vertexai>=2.2b0 opentelemetry-instrumentation-google-genai>=0.4b0 fsspec[gcs]==2025.10.0Not all versions of
fsspecsupport collection of prompts and responses. The listed version is known to support this feature. You might also examine the sample to determine whether you can use a later version.If you are using ADK, then update your application's invocation to turn on the
otel_to_cloudflag:If you are using the CLI for ADK, then run the following command:
adk web --otel_to_cloud [other options]Otherwise, pass the flag when creating the FastAPI app:
get_fast_api_app(..., otel_to_cloud=True)
Set the following environment variables:
Instruct OpenTelemetry to format Cloud Storage objects as JSON Lines.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'Instruct OpenTelemetry to upload prompt and response data instead of embedding this content in trace spans. References to the uploaded objects are included in a log entry.
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'Instruct OpenTelemetry to use the most recent semantic conventions for generative AI.
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'Optional: Instruct OpenTelemetry to not attach message content as attributes on spans.
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT='NO_CONTENT'You don't need to set the previous environment variable. However, if you do, then we recommend that you set it to
NO_CONTENT. For information about the allowed values, seegenai/types.py.Specify the path for objects:
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'In the previous expression, STORAGE_BUCKET refers to the name of the Cloud Storage bucket. PATH refers to the path where objects are stored.
For LangGraph ReAct agents, instruct OpenTelemetry to automatically capture log data:
OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED='true'You might need to set other environment variables. For example, if you deploy to Gemini Enterprise Agent Platform, then you also want to set the following environment variable.
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY='true'
View multimodal prompts and responses
To determine the prompts and responses to display for a span, Cloud Trace issues queries to read log data and to read data stored in a Cloud Storage bucket. Your Identity and Access Management (IAM) roles on the queried resources determine whether data is returned. In some cases, you might see an error message. For example, if you don't have permission to read data from a Cloud Storage bucket, then attempts to access that data result in a permission-denied error.
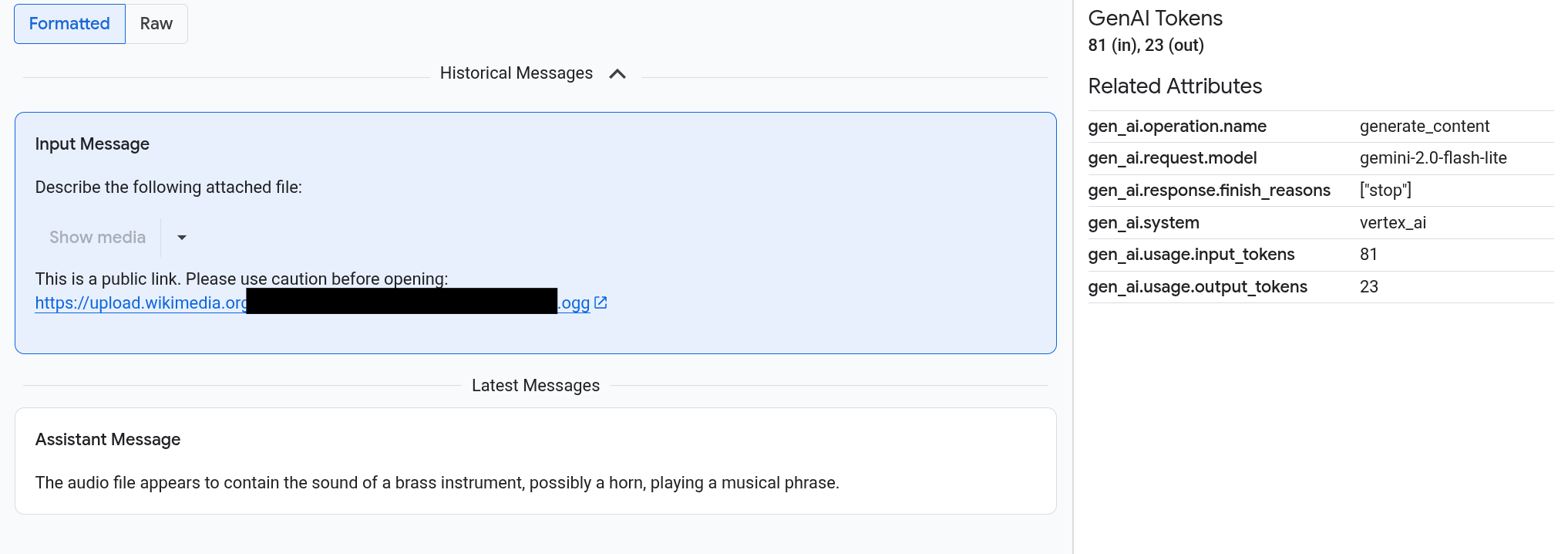
Prompts and responses appear in a chat-like format, and you select whether media like images automatically render or appear in source format. Similarly, you can view the entire conversation history or only view the prompts and responses attached to a span.
For example, the following example illustrates how prompts and responses appear, and how OpenTelemetry: Attributes are summarized:
Before you begin
To ensure that the service account your application uses has the necessary permissions to view multimodal prompts and responses, ask your administrator to grant the following IAM roles to the service account your application uses on project:
- Cloud Trace User (
roles/cloudtrace.user) - Logs Viewer (
roles/logging.viewer) - Storage Object Viewer (
roles/storage.objectViewer)
Find spans that contain multimodal prompts and responses
To find the spans that contain multimodal prompts and responses, do the following:
-
In the Google Cloud console, go to the
 Trace explorer page:
Trace explorer page:
You can also find this page by using the search bar.
In the Span filter pane, go to the Span name section and select
generate_content.Alternatively, add the filter
gen_ai.operation.name: generate_content.Select a span from the list of spans.
The Details page for the span opens. This page displays the span, within the context of the trace. If a span name has a button labeled Inputs/Outputs,
 , then there are
generative AI events available. The next section,
Explore multimodal prompts and responses, explains how
the data is presented and the visualization options.
, then there are
generative AI events available. The next section,
Explore multimodal prompts and responses, explains how
the data is presented and the visualization options.
Explore multimodal prompts and responses
The Inputs/Outputs tab contains two sections.
One section displays the prompts and
responses, and the other section displays OpenTelemetry: Attributes. This tab
appears only when spans sent to Trace
follow the OpenTelemetry GenAI semantic conventions,
version 1.37.0 or higher,
which results in messages whose names begin with gen_ai.
The Inputs/Outputs tab shows messages in a chat-like format. You control which messages appear and their format by using options on the tab:
- To view the entire conversation, expand the Historical Messages pane.
- To view only the prompts and responses in the selected span, use the Latest Messages pane.
To view images, videos, or other media, select Formatted.
The system doesn't always show media. To protect you, if a prompt or response includes a link to a public image, document, or video, then you must confirm that you want the media shown. Similarly, if a prompt or response includes media that is stored in your Cloud Storage bucket and if the media is very large, then you must confirm that you want the media shown.
Some media, like images and video, appear with an attached menu. You can use this menu to perform actions like download an image to a local drive. The menu options depend on the media type.
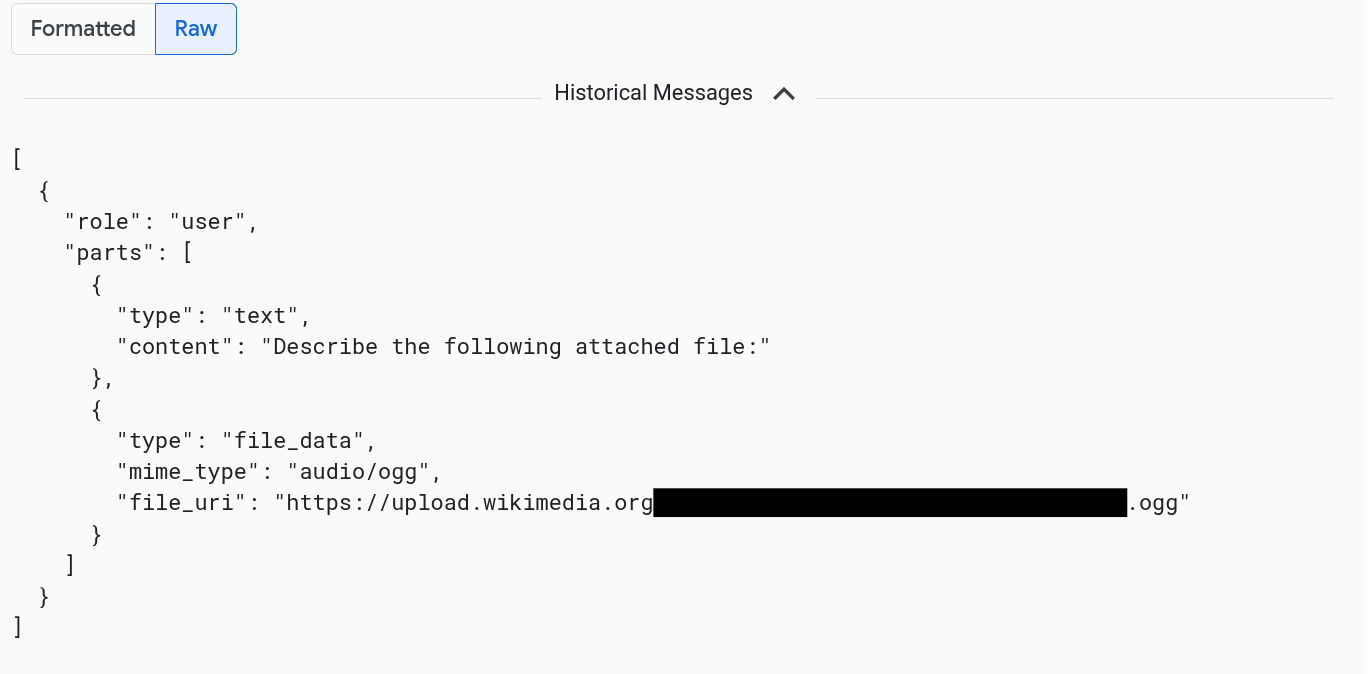
To view the messages as formatted in JSON, select Raw. With this selection, media like images aren't rendered.
For example, the following image illustrates how a conversation appears in raw format:
Find all log entries that reference prompts and responses
To list the log entries that include object references to multimodal prompts and responses, do the following:
-
In the Google Cloud console, go to the Logs Explorer page:
If you use the search bar to find this page, then select the result whose subheading is Logging.
In the project picker, select your Google Cloud project.
In the toolbar, expand All log names, enter
gen_aiin the filter, and then select the log named gen_ai.client.inference.operation.details.The previous steps add the following query to the Logs Explorer:
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"If you prefer, you can copy the statement and paste it into the Query pane of the Logs Explorer, but replace PROJECT_ID with your project ID before you copy the statement.
You can also filter log data by label value. For example, if you add the following filter, then only log entries that contain the specified label appear:
labels."event.name"="gen_ai.client.inference.operation.details"To view the prompts and responses that are referenced by a log entry, in the log entry, click
View trace details.To learn how to use the options on the Inputs/Outputs tab, see the Explore multimodal prompts and responses section of this document.
Analyze prompt-response data by using BigQuery
You can analyze the prompts and responses that your Cloud Storage bucket stores by using BigQuery. Before you perform this analysis, complete the following steps:
- Enable required APIs and make sure that you have been given the necessary IAM roles.
- Create a linked BigQuery dataset on your log bucket.
- Give BigQuery permission to read from your Cloud Storage bucket.
- Create an external table.
After you create the external table, you join the data in your log bucket with your external table, and perform your analysis on the joined data. This section illustrates how to join your tables and extract specific fields. It also illustrates how to analyze the joined table with BigQuery ML functions.
Before you begin
The IAM roles listed in this section are required to perform actions like upgrading a log bucket and create an external table. However, after the configuration is completed, fewer permissions are required to run queries.
-
Enable the BigQuery and BigQuery Connection APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles. -
To ensure that the service account your application uses has the necessary permissions to configure the system so that you can view multimodal prompts and responses in BigQuery, ask your administrator to grant the following IAM roles to the service account your application uses on project:
- Logs Configuration Writer (
roles/logging.configWriter) - Storage Admin (
roles/storage.admin) - BigQuery Connection Admin (
roles/bigquery.connectionAdmin) - BigQuery Data Viewer (
roles/bigquery.dataViewer) - BigQuery Studio User (
roles/bigquery.studioUser)
- Logs Configuration Writer (
Create a linked BigQuery dataset on your log bucket
To determine whether the log bucket that stores your log data is upgraded for Observability Analytics, run the following command:
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATIONReplace the following before you run the command:
- LOG_BUCKET_ID: The ID of the log bucket.
- LOCATION: The location of the log bucket.
When a log bucket is upgraded for Observability Analytics, the results of the
describecommand include the following statement:analyticsEnabled: trueIf your log bucket isn't upgraded, then run the following command:
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --asyncThe upgrade can take several minutes to complete. When the
describecommand reports thelifecycleStateasACTIVE, the upgrade is complete.To create a linked BigQuery dataset on your log bucket, run the following command:
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATIONReplace the following before you run the command:
- LOG_BUCKET_ID: The ID of the log bucket.
- LOCATION: The location of the log bucket.
- LINKED_DATASET_NAME: Name of the linked BigQuery dataset to create.
The linked BigQuery dataset lets BigQuery read the log data stored in your log bucket. To learn more, see Query a linked BigQuery dataset.
To confirm that the link exists, run the following command:
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATIONWhen successful, the response to the previous command includes the following line:
LINK_ID: LINKED_DATASET_NAME
Give BigQuery permission to read from your Cloud Storage bucket
To create a BigQuery connection, run the following command:
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_IDReplace the following before you run the command:
- PROJECT_ID: The identifier of the project.
- CONNECTION_ID: The ID of the connection to create.
- CONNECTION_LOCATION: The location of the connection.
When the command completes successfully, it displays a message similar to the following:
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully createdVerify the connection.
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_IDThe response to this command lists the connection ID, and it lists a service account:
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}Grant the service account for the BigQuery connection an IAM role that lets it read data stored in your Cloud Storage bucket:
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewerReplace the following before you run the command:
- STORAGE_BUCKET: The name of your Cloud Storage bucket.
- SERVICE_ACCT_EMAIL: The email address of your service account.
Create an external BigLake table
To use BigQuery to query data that BigQuery doesn't store, create an external table. Because a Cloud Storage bucket stores the prompts and responses, create a BigLake external table.
-
In the Google Cloud console, go to the BigQuery page:
You can also find this page by using the search bar.
In the query editor, enter the following statement:
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );Replace the following before you run the command:
- PROJECT_ID: The identifier of the project.
- EXT_TABLE_DATASET_NAME: The name of the dataset to create.
- EXT_TABLE_NAME: The name of the external BigLake table to create.
- CONNECTION_LOCATION: The location of your CONNECTION_ID.
- CONNECTION_ID: The ID of the connection.
- STORAGE_BUCKET: The name of the Cloud Storage bucket.
- PATH: The path to the prompts and responses. The
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATHenvironment variable specifies the path.
Click Run.
To learn more about external tables, see the following:
Join your external table with your log data
This section illustrates how you can analyze multimodal prompts in
BigQuery. The solution relies on joining your
external BigLake table with your log data, which lets you
retrieve objects from your Cloud Storage bucket. The example joins on the
URI for the input messages, gen_ai.input.messages. You can also join on
the URI for the output messages, gen_ai.output.messages, or
on the system instructions, gen_ai.system_instructions.
To join your external BigLake table with your log data, do the following:
-
In the Google Cloud console, go to the BigQuery page:
You can also find this page by using the search bar.
In the query editor, enter the following query, which joins your log data and your external table on the path to the Cloud Storage bucket entries:
-- Query the linked BigQuery dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uriReplace the following before you run the query:
- PROJECT_ID: The identifier of the project.
- LINKED_DATASET_NAME: The name of the linked BigQuery dataset.
- EXT_TABLE_DATASET_NAME: The name of the dataset for the external BigLake table.
- EXT_TABLE_NAME: The name of the external BigLake table.
Optional: The previous query filters by the log name and timestamp. If you want to also filter by a specific trace ID, then add the following statement to the
WHEREclause:AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'In the previous expression, replace TRACE_ID with the 16-byte hexadecimal string that contains a trace ID.
Use BigQuery ML functions
You can use BigQuery ML functions like
AI.GENERATE
on the prompts and responses stored in your Cloud Storage bucket.
For example, the following query joins the completion log entries with the
external table, flattens and filters the join result. Next, the prompt
runs AI.GENERATE to analyze whether entries contain an image and to generate
a summary of each entry:
-- Query the linked BigQuery dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
Replace the following before you run the query:
- PROJECT_ID: The identifier of the project.
- LINKED_DATASET_NAME: The name of the linked BigQuery dataset.
- EXT_TABLE_DATASET_NAME: The name of the dataset for the external BigLake table.
- EXT_TABLE_NAME: The name of the external BigLake table.
- CONNECTION_LOCATION: The location of your CONNECTION_ID.
- CONNECTION_ID: The ID of the connection.
Run evaluations on the prompt-response data with Colaboratory
You can evaluate prompts and responses by using the Vertex AI SDK for Python.
To run evaluations by using a Google Colaboratory notebook, do the following:
To view an example notebook, click
evaluating_observability_datasets.ipynb.GitHub opens and displays instructions for using the notebook.
Select Open in Colab.
Colaboratory opens and displays the
evaluating_observability_datasets.ipynbfile.In the toolbar, click Copy to Drive.
Colaboratory creates a copy notebook, saves it to your drive, and then opens the copy.
In your copy, go to the section titled Set Google Cloud project information and enter your Google Cloud project ID and a location that is supported by Vertex AI. For example, you might set the location to
"us-central1".Go to the section titled Load in Google Observability Gen AI datasets and enter values for the following sources:
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
You can find values for these fields by using the
gen_ailabels that are attached to your log entries. For example, for the INPUT_SOURCE, the value is similar to the following:'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'In the preceding expression, the fields have the following meanings:
- STORAGE_BUCKET: The name of the Cloud Storage bucket.
- PATH: The path to the prompts and responses.
- REFERENCE: The identifier of the data in your Cloud Storage bucket.
For information about how to find values for these sources, see Find all log entries that reference prompts and responses.
In the toolbar, click Run all.