
Com o Cloud SQL, é possível restaurar suas instâncias de um backup ou realizar uma recuperação pontual (PITR). Isso permite recuperar uma instância para um período ou horário específico, restaurando o backup para uma instância existente ou para uma nova instância. Para restaurar, use o backup de uma instância ativa ou excluída. A operação de restauração usa as configurações, os bancos de dados e os usuários da instância de origem e os define na instância de destino escolhida.
Ao restaurar para uma nova instância, a instância de destino pode estar em uma região ou projeto diferente da instância de origem. A instância de destino também pode usar um número diferente de núcleos ou quantidade de memória do que a instância de origem.
O Cloud SQL sempre define a capacidade de armazenamento da instância de destino como o valor máximo do tamanho do disco configurado e do disco de backup. O disco de backup é o tamanho do disco quando o backup é realizado.
Ao realizar uma restauração em uma instância, considere o seguinte:
- A operação de restauração substitui todos os dados na instância de destino.
- As flags da instância de origem não são restauradas. Todas as flags definidas anteriormente na instância de destino serão mantidas após a restauração.
- A instância de destino não está disponível para conexões durante a operação de restauração. As conexões atuais se perdem.
- Se você estiver restaurando para uma instância com réplicas de leitura, exclua todas as réplicas e recrie-as após a conclusão da operação de restauração.
- A operação de restauração reinicia a instância.
- Depois de restaurar de um backup, as configurações de backup da instância de destino são definidas como valores padrão. Se a instância de origem tinha configurações de backup personalizadas ou usava backups avançados, será necessário atualizar as configurações de backup após a conclusão da restauração.
Restaurar usando um backup
O Cloud SQL permite restaurar uma instância usando um backup. É possível usar um backup de uma instância ativa ou excluída para restaurar uma instância nova ou existente. É possível usar qualquer backup disponível para restaurar a instância. Para saber mais sobre como os backups funcionam no Cloud SQL, consulte Visão geral dos backups.
Ao restaurar uma instância usando um backup, você pode fazer o seguinte:
- Restaurar para uma nova instância
- Restaurar para uma instância atual
- Restaurar para uma instância em outro projeto ou região
Em caso de interrupção, ainda é possível recuperar uma lista de backups em um projeto específico para fazer a restauração.
Para restaurar sua instância usando um backup, consulte Restaurar uma instância usando um backup.
Restaurar uma instância ativada para CMEK usando backups aprimorados
Quando você usa instâncias habilitadas para CMEK com backups aprimorados, seus backups são protegidos pela mesma CMEK da instância. Isso pode ser uma parte importante do plano de backup para instâncias que exigem criptografia CMEK, porque mantém os backups criptografados com CMEK em um projeto separado, em que podem ser restaurados com sucesso, mesmo que o projeto original da carga de trabalho seja comprometido ou excluído.
Ao restaurar um backup avançado de uma instância ativada para CMEK em uma nova instância, é possível escolher qualquer uma das seguintes opções de criptografia para a nova instância:
- Use a mesma chave do Cloud KMS que a instância original. Este é o comportamento padrão.
- Selecione outra chave do Cloud KMS para a instância de destino. Para selecionar
uma chave diferente, defina a flag
--disk-encryption-keyno comando de restauração. - Reverta para Google-owned and Google-managed encryption keys na instância de destino.
Para usar o GMEK, defina a flag
--clear-disk-encryptionno comando de restauração.
Recuperação pontual (PITR)
Com a PITR, é possível restaurar a instância para um momento específico do banco de dados. Por exemplo, se houver perda de dados devido a um erro, será possível recuperar um banco de dados no estado anterior a esse evento. Ao contrário da restauração usando um backup, a PITR sempre cria uma nova instância. Não é possível executar uma PITR em uma instância atual. A nova instância herda as configurações da instância de origem, assim como quando você cria um clone.
Se você criar uma instância da edição Cloud SQL Enterprise Plus, a PITR será ativada por padrão. É necessário desativar o recurso manualmente se não quiser que ele fique ativado.
Se você criar uma instância da edição Cloud SQL Enterprise no console Google Cloud , a PITR será ativada por padrão. Caso contrário, se você criar a instância usando a CLI gcloud, o Terraform ou a API Cloud SQL Admin, a PITR será desativada por padrão. Para ativar a PITR nessas instâncias, é necessário fazer isso manualmente.
Para instruções detalhadas sobre como realizar a PITR, consulte Usar a recuperação pontual (PITR, na sigla em inglês).
Armazenamento de registros para PITR
A PITR usa para arquivar registros. Quando você restaura uma instância usando um backup, esses registros de arquivo são excluídos e não ficam disponíveis para realizar uma PITR. Somente os novos registros gerados após a conclusão da restauração podem ser usados para PITR.
Em 31 de maio de 2024, lançamos o armazenamento de registros de transação para PITR no Cloud Storage. Desde esse lançamento, as seguintes condições se aplicam:
Todas as instâncias da edição Cloud SQL Enterprise Plus armazenam os registros de transação usados para PITR no Cloud Storage. Apenas as instâncias da edição Cloud SQL Enterprise Plus que você fez upgrade do Cloud SQL Enterprise antes de 1o de abril de 2024 e ativou a PITR antes de 31 de maio de 2024 continuam armazenando os registros da PITR no disco.
As instâncias da edição Cloud SQL Enterprise criadas com a PITR ativada antes de 31 de maio de 2024 continuam armazenando os registros da PITR no disco.
Se você fizer upgrade de uma instância do Cloud SQL Enterprise após 31 de maio de 2024 que armazena registros de transação para PITR em disco para a edição Cloud SQL Enterprise Plus, o processo de upgrade vai mudar o local de armazenamento dos registros de transações usados para a PITR. para o Cloud Storage. Para mais informações, consulte Fazer upgrade de uma instância para o Cloud SQL Enterprise Plus usando o upgrade no local.
Todas as instâncias da edição Cloud SQL Enterprise que você criar com a PITR ativada após 31 de maio de 2024 armazenam os registros usados para a PITR no Cloud Storage.
Se a instância usar o Cloud Storage para armazenar registros de transações, eles serão armazenados na mesma região da instância principal. Esses registros são armazenados por até 35 dias para a edição Cloud SQL Enterprise Plus e 7 dias para a edição Cloud SQL Enterprise, sem gerar custos extras por instância.
Para mais informações sobre como verificar o local de armazenamento dos registros de transações usados para a PITR, consulte verificar onde os registros de transações são armazenados para sua instância.
Para instâncias que armazenam registros de transação apenas no disco, é possível mudar o local de armazenamento dos registros de transação usados para PITR do disco para o Cloud Storage usando a CLI gcloud ou a API Cloud SQL Admin. Para mais informações, consulte Mudar o armazenamento de registros de transações para o Cloud Storage.
Para garantir que os registros da sua instância sejam armazenados no Cloud Storage em vez de no disco, siga estas etapas:
- Verifique a arquitetura de rede da instância. Se a instância estiver na arquitetura de rede antiga, faça upgrade para a nova arquitetura de rede.
Se o tamanho dos registros no disco estiver causando problemas de desempenho para sua instância, desative a PITR e reative-a. Essa ação garante que novos registros sejam armazenados no Cloud Storage em vez de no disco.
Período de armazenamento de registros
O Cloud SQL mantém os registros de transação no Cloud Storage até o valor definido na configuração da PITR transactionLogRetentionDays. Esse valor pode variar de 1 a 35 dias para a edição Cloud SQL Enterprise Plus e de 1 a 7 dias para a edição Cloud SQL Enterprise. Se um valor não for definido para esse parâmetro, o período de armazenamento de registros de transações padrão será de 14 dias para as instâncias da edição Cloud SQL Enterprise Plus e de sete dias para as instâncias da edição Cloud SQL Enterprise. Para mais
informações sobre como definir os dias de retenção de registros de transações,
consulte Definir retenção de registros de transações.
Uma instância armazena os registros de transações usados para a PITR no Cloud Storage, mas também mantém um número menor de registros de transações duplicados no disco para permitir a replicação dos registros no Cloud Storage. Por padrão, quando você cria uma instância com a PITR
ativada, ela armazena os registros de transação para a PITR
no Cloud Storage. O Cloud SQL também define o valor das flags
expire_logs_days e binlog_expire_logs_seconds como o equivalente
de um dia automaticamente. Isso significa um dia de registros no disco.
Para os registros de transação da PITR armazenados no disco, que estão sendo ou que já foram transferidos para o Cloud Storage, o Cloud SQL mantém os registros pelo valor mínimo definido para uma das seguintes configurações:
- A configuração de backup de
transactionLogRetentionDays. - A flag
expire_logs_daysoubinlog_expire_logs_seconds.
O Cloud SQL não define valores para essas flags
quando os registros de transações estão armazenados no disco, estão sendo transferidos
para o Cloud Storage ou já foram transferidos
para o Cloud Storage. Quando os registros são armazenados no disco, a modificação dos valores
dessas flags pode afetar o comportamento da recuperação PITR e o número de dias
em que os registros ficam armazenados no disco. Enquanto o local de armazenamento de registros estiver sendo
transferido para o Cloud Storage, não será possível modificar os valores das flags.
Também não recomendamos configurar o valor de nenhuma flag como 0. Para mais
informações, consulte
Configurar flags de banco de dados.
- Configuração do
transactionLogRetentionDays - Flag do banco de dados
expire_logs_days - Flag do banco de dados
binlog_expire_logs_seconds
Por exemplo, para evitar problemas de desempenho, reduza o valor das flags em um dia, a cada dia, ao longo de vários dias. Como resultado, o Cloud SQL não limpa todos os registros de transações simultaneamente.
Para
instâncias ativadas por chave de criptografia gerenciada pelo cliente (CMEK),
os registros de transações são criptografados usando a versão mais recente da
CMEK. Para realizar uma restauração, a versão mais recente da chave é necessária para todos os dias
mantidos como parte do parâmetro retained-transaction-log-days.
Limitações da PITR
As seguintes limitações estão associadas à sua instância com a PITR ativada e ao tamanho dos registros de transação no disco causando um problema para a instância:
- É possível desativar a PITR e reativá-la para garantir que o Cloud SQL armazene registros no Cloud Storage na mesma região da instância. No entanto, o Cloud SQL exclui todos os registros atuais. Portanto, não é possível realizar uma operação de PITR antes do momento em que você reativou a PITR.
- É possível aumentar o tamanho do armazenamento da instância, mas o aumento do tamanho do registro de transações no uso do disco pode ser temporário.
- Para evitar problemas de armazenamento inesperados, recomendamos ativar os aumentos automáticos de armazenamento. Essa recomendação se aplica somente se a instância tiver a PITR ativada e seus registros estiverem armazenados no disco.
- A recuperação pontual (PITR) não pode ser ativada na instância de destino do Cloud SQL se ela tiver vários bancos de dados com o mesmo nome físico.
Snapshots de banco de dados
Não é possível usar snapshots de banco de dados do SQL Server em nenhum banco de dados em uma instância em que a PITR está ativada.
Os snapshots de banco de dados podem interferir no backup completo do banco de dados e no backup do registro de transações em que a PITR se baseia. Essa interferência pode impedir operações de PITR bem-sucedidas para qualquer banco de dados na instância.
Modelo de recuperação de banco de dados para PITR
Se você ativar a PITR em uma instância, o Cloud SQL definirá automaticamente o modelo de recuperação dos bancos de dados atuais e subsequentes como o modelo de recuperação completa.
Para mais informações sobre os modelos de recuperação do SQL Server, consulte a documentação da Microsoft.
Para instruções detalhadas sobre como realizar a PITR, consulte [Usar a recuperação pontual (PITR)][perform-pitr].
Restaurar uma instância excluída usando a PITR
É possível usar a PITR para restaurar uma instância do Cloud SQL após a exclusão. Para usar esse recurso, sua instância precisa ter PITR e backups retidos ativados antes da exclusão. Quando ativados, os registros da PITR são retidos após a exclusão da instância.
Depois que uma instância é excluída, os registros da PITR continuam seguindo as configurações de retenção definidas pela instância quando ela estava ativa. Os registros da PITR expiram com base nas configurações de retenção de forma contínua após a exclusão da instância. O período contínuo é definido com base no período de retenção da PITR definido na instância antes da exclusão. Por exemplo, se a instância do Cloud SQL Enterprise Plus tiver a retenção de PITR definida como 14 dias, o registro de PITR mais recente será excluído 14 dias após a exclusão da instância. Quando um registro de PITR expira, ele não pode ser recuperado.
Como os nomes de instâncias podem ser reutilizados depois que uma instância é excluída no Cloud SQL, os registros de PITR retidos podem ser identificados em Google Cloud com os seguintes campos:
instance_deletion_timelog_retention_days
Esses campos permitem identificar se um registro de PITR pertence a uma instância excluída.
A janela de recuperação da PITR é definida como os horários de recuperação mais antigos e mais recentes disponíveis para restaurar sua instância usando a PITR. Para encontrar os horários de recuperação mais antigos e mais recentes da sua instância excluída, consulte Receber o horário de recuperação mais antigo e mais recente.
Para restaurar uma instância usando a PITR após a exclusão, consulte Realizar a PITR em uma instância excluída.
Requisitos para restaurar em uma nova instância
Ao restaurar sua instância para uma nova, observe os seguintes requisitos:
- A instância de destino precisa ter a mesma versão do banco de dados que a instância de origem do backup.
Ao criar uma instância, o recurso
storageAutoResizeé ativado por padrão. Qualquer backup criado posteriormente herda a mesma configuração destorageAutoResize. Isso significa que, ao restaurar um backup para uma instância nova ou atual, a capacidade de armazenamento será redimensionada automaticamente conforme necessário. As instâncias legadas não têm esse recurso ativado. Para verificar as configurações da instância, consulte Visualizar as configurações da instância. Esse requisito é aplicável mesmo que você esteja ou não realizando a PITR de um único banco de dados.A instância de destino deve estar no estado
RUNNABLE.
Limitações de taxa de restauração
É permitido um máximo de três operações de restauração a cada 30 minutos por instância por região e por projeto. Se uma operação de restauração falhar, ela não será contabilizada nessa cota. Se você atingir o limite, a operação vai falhar com uma mensagem de erro que informa quando é possível executá-la novamente.
O Cloud SQL usa tokens de um bucket para determinar quantas operações de restauração estão disponíveis por vez. Para cada backup, há um bucket para cada projeto e região de destino. As instâncias de destino do mesmo projeto compartilham um bucket se estiverem na mesma região. É possível usar no máximo três tokens em cada bucket para operações de restauração. A cada 10 minutos, um novo token é adicionado ao bucket. Se o bucket estiver cheio, o token vai estourar.
Cada vez que você emite uma operação de restauração, um token é concedido a partir do bucket. Se a operação for bem-sucedida, o token será removido do bucket. Se falhar, o token será retornado. O diagrama a seguir mostra como isso funciona:

Por exemplo, na figura a seguir, os backups Backup1, Backup2 e Backup3 são da mesma instância de origem.
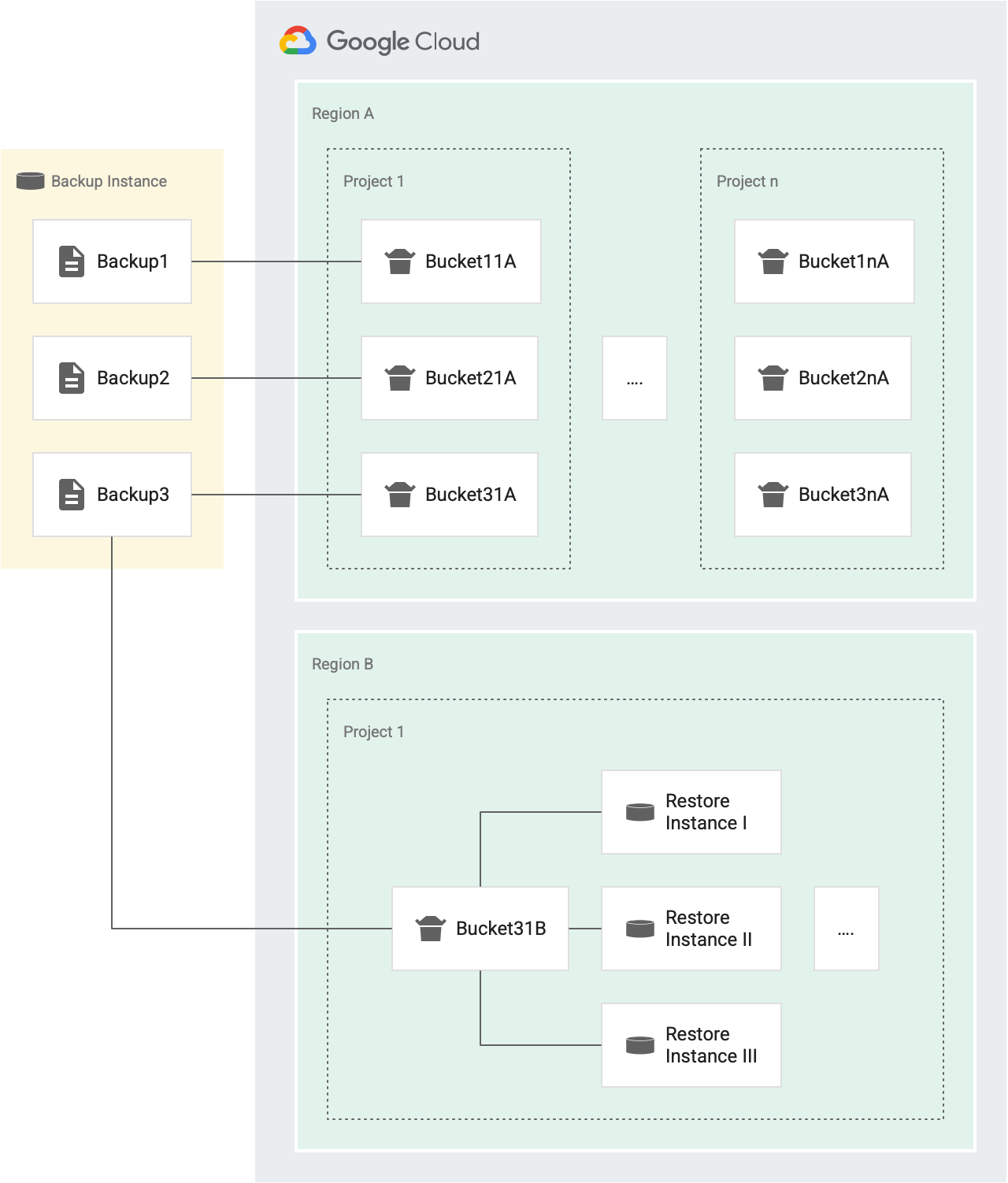
- Cada backup (Backup1, Backup2 e Backup3) tem o próprio bucket de tokens para operações de restauração que visam instâncias diferentes no Projeto 1 na Região A (Bucket11A, Bucket21A e Bucket31A). Como cada backup tem o próprio bucket, é possível restaurar cada backup para a mesma instância três vezes a cada 30 minutos.
- Cada backup tem um bucket para um projeto e uma região separados.
Por exemplo, se houver cinco projetos em uma região, haverá cinco buckets para esse backup nessa região, um em cada projeto. Na figura
anterior, temos dois projetos na região A: Projeto 1 e Projeto n.
- O Backup1 tem dois buckets de tokens para operações de restauração na região A. Um bucket para o projeto 1 (bucket11A) e um bucket para o projeto n (bucket1nA).
- Da mesma forma, o Backup3 tem dois buckets para operações de restauração na região A. Uma para o Projeto 1 (Bucket31A) e outra para o Projeto n (Bucket3nA).
- O Backup3 tem um bucket na região B, para o Projeto 1, porque todas as instâncias no mesmo projeto de destino e na mesma região de destino compartilham um bucket.