
In Cloud SQL können Sie Ihre Instanzen aus einer Sicherung oder durch die Wiederherstellung zu einem bestimmten Zeitpunkt (Point-in-Time Recovery, PITR) wiederherstellen. So können Sie eine Instanz zu einem bestimmten Zeitraum oder Zeitpunkt wiederherstellen, indem Sie entweder die Sicherung in einer vorhandenen Instanz oder in einer neuen Instanz wiederherstellen. Für die Wiederherstellung können Sie die Sicherung einer aktiven oder gelöschten Instanz verwenden. Beim Wiederherstellungsvorgang werden die Einstellungen, Datenbanken und Nutzer der Quellinstanz übernommen und in der von Ihnen ausgewählten Zielinstanz festgelegt.
Wenn Sie eine Wiederherstellung in einer neuen Instanz durchführen, kann sich die Zielinstanz in einer anderen Region oder einem anderen Projekt als die Quellinstanz befinden. Die Zielinstanz kann auch eine andere Anzahl von Kernen oder eine andere Menge an Arbeitsspeicher als die Quellinstanz verwenden.
Cloud SQL setzt die Speicherkapazität der Zielinstanz immer auf den Höchstwert der Größe des konfigurierten Laufwerks und des Sicherungslaufwerks. Das Sicherungslaufwerk ist die Größe des Laufwerks zum Zeitpunkt der Sicherung.
Beachten Sie Folgendes, wenn Sie eine Wiederherstellung in einer Instanz durchführen:
- Mit der Wiederherstellung werden alle Daten in der Zielinstanz überschrieben.
- Die Flags aus der Quellinstanz werden nicht wiederhergestellt. Alle Flags, die zuvor für die Zielinstanz festgelegt wurden, werden nach der Wiederherstellung beibehalten.
- Während der Wiederherstellung ist die Zielinstanz nicht für Verbindungen verfügbar. Bestehende Verbindungen werden getrennt.
- Wenn Sie die Wiederherstellung in einer Instanz durchführen, die Lesereplikate hat, müssen Sie alle Replikate löschen und nach Abschluss der Wiederherstellung neu erstellen.
- Durch den Wiederherstellungsvorgang wird die Instanz neu gestartet.
- Nachdem Sie eine Wiederherstellung aus einer Sicherung durchgeführt haben, werden die Sicherungskonfigurationen der Zielinstanz auf die Standardwerte gesetzt. Wenn Ihre Quellinstanz benutzerdefinierte Sicherungskonfigurationen hatte oder erweiterte Sicherungen verwendet wurden, müssen Sie die Sicherungskonfigurationen nach Abschluss der Wiederherstellung aktualisieren.
Wiederherstellung mit einer Sicherung
In Cloud SQL können Sie eine Instanz mit einer Sicherung wiederherstellen. Sie können eine Sicherung aus einer aktiven oder gelöschten Instanz verwenden und sie in einer neuen oder vorhandenen Instanz wiederherstellen. Sie können jede verfügbare Sicherung verwenden, um die Instanz wiederherzustellen. Weitere Informationen zur Funktionsweise von Sicherungen in Cloud SQL finden Sie unter Übersicht über Sicherungen.
Wenn Sie eine Instanz mit einer Sicherung wiederherstellen, haben Sie folgende Möglichkeiten:
- In einer neuen Instanz wiederherstellen
- In einer vorhandenen Instanz wiederherstellen
- In einer Instanz in einem anderen Projekt oder einer anderen Region wiederherstellen
Im Falle eines Ausfalls können Sie weiterhin eine Liste der Sicherungen in einem bestimmten Projekt abrufen, um eine Wiederherstellung durchzuführen.
Informationen zum Wiederherstellen Ihrer Instanz mit einer Sicherung finden Sie unter Instanz mit einer Sicherung wiederherstellen.
CMEK-fähige Instanz mit erweiterten Sicherungen wiederherstellen
Wenn Sie CMEK-fähige Instanzen mit erweiterten Sicherungen verwenden, werden Ihre Sicherungen mit demselben CMEK wie die Instanz geschützt. Dies kann ein wichtiger Bestandteil Ihres Sicherungsplans für Instanzen sein, für die eine CMEK-Verschlüsselung erforderlich ist, da Ihre CMEK-verschlüsselten Sicherungen in einem separaten Projekt aufbewahrt werden, in dem sie auch dann erfolgreich wiederhergestellt werden können, wenn Ihr ursprüngliches Arbeitslastprojekt kompromittiert oder gelöscht wurde.
Wenn Sie eine erweiterte Sicherung einer CMEK-fähigen Instanz in einer neuen Instanz wiederherstellen, können Sie eine der folgenden Verschlüsselungsoptionen für die neue Instanz auswählen:
- Verwenden Sie denselben Cloud KMS-Schlüssel wie die ursprüngliche Instanz. Dies ist das Standardverhalten.
- Wählen Sie einen anderen Cloud KMS-Schlüssel für die Zielinstanz aus. Wenn Sie einen anderen Schlüssel auswählen möchten, legen Sie das Flag
--disk-encryption-keyim Wiederherstellungsbefehl fest. - Kehren Sie zu Google-owned and Google-managed encryption keys für die Zielinstanz zurück.
Wenn Sie GMEK verwenden möchten, legen Sie das Flag
--clear-disk-encryptionim Wiederherstellungsbefehl fest.
Wiederherstellung zu einem bestimmten Zeitpunkt (PITR)
Mit der Wiederherstellung zu einem bestimmten Zeitpunkt können Sie Ihre Instanz zu einem bestimmten Zeitpunkt der Datenbank wiederherstellen. Wenn beispielsweise ein Fehler zu einem Datenverlust geführt hat, haben Sie die Möglichkeit, den Zustand der Datenbank wiederherzustellen, den sie vor dem Auftreten des Fehlers hatte. Im Gegensatz zur Wiederherstellung mit einer Sicherung wird bei der Wiederherstellung zu einem bestimmten Zeitpunkt immer eine neue Instanz erstellt. Diese Art der Wiederherstellung kann nicht für eine vorhandene Instanz durchgeführt werden. Die neue Instanz übernimmt die Einstellungen der Quellinstanz, ähnlich wie beim Erstellen eines Klons.
Wenn Sie eine Cloud SQL Enterprise Plus-Instanz erstellen, ist die Wiederherstellung zu einem bestimmten Zeitpunkt standardmäßig aktiviert. Sie müssen die Funktion manuell deaktivieren, wenn sie nicht aktiviert sein soll.
Wenn Sie eine Cloud SQL Enterprise-Instanz in der Google Cloud Console erstellen, ist die Wiederherstellung zu einem bestimmten Zeitpunkt standardmäßig aktiviert. Wenn Sie die Instanz mit der gcloud CLI, Terraform oder der Cloud SQL Admin API erstellen, ist die Wiederherstellung zu einem bestimmten Zeitpunkt standardmäßig deaktiviert. Wenn Sie die Wiederherstellung zu einem bestimmten Zeitpunkt für diese Instanzen aktivieren möchten, müssen Sie sie manuell aktivieren.
Eine detaillierte Anleitung zur Durchführung einer Wiederherstellung zu einem bestimmten Zeitpunkt finden Sie unter Wiederherstellung zu einem bestimmten Zeitpunkt verwenden.
Logspeicher für die Wiederherstellung zu einem bestimmten Zeitpunkt
Bei der Wiederherstellung zu einem bestimmten Zeitpunkt werden Logs mit archiviert. Wenn Sie eine vorhandene Instanz mit einer Sicherung wiederherstellen, werden diese Archivlogs gelöscht und sind für die Wiederherstellung zu einem bestimmten Zeitpunkt nicht verfügbar. Nur neue Logs, die nach Abschluss der Wiederherstellung generiert wurden, können für die Wiederherstellung zu einem bestimmten Zeitpunkt verwendet werden.
Am 31. Mai 2024 haben wir die Speicherung von Transaktionslogs für die Wiederherstellung zu einem bestimmten Zeitpunkt in Cloud Storage eingeführt. Seit dieser Einführung gelten die folgenden Bedingungen:
Alle Cloud SQL Enterprise Plus-Instanzen speichern ihre Transaktionslogs, die für die Wiederherstellung zu einem bestimmten Zeitpunkt verwendet werden, in Cloud Storage. Nur Cloud SQL Enterprise Plus-Instanzen, die Sie vor dem 1. April 2024 von der Cloud SQL Enterprise-Version aktualisiert und für die Sie die Wiederherstellung zu einem bestimmten Zeitpunkt vor dem 31. Mai 2024 aktiviert haben, speichern ihre Logs weiterhin auf dem Laufwerk für die Wiederherstellung zu einem bestimmten Zeitpunkt.
Cloud SQL Enterprise-Instanzen, die vor dem 31. Mai 2024 mit aktivierter Wiederherstellung zu einem bestimmten Zeitpunkt erstellt wurden, speichern ihre Logs weiterhin auf dem Laufwerk für die Wiederherstellung zu einem bestimmten Zeitpunkt.
Wenn Sie nach dem 31. Mai 2024 eine Cloud SQL Enterprise-Instanz aktualisieren, in der Transaktionslogs für die Wiederherstellung zu einem bestimmten Zeitpunkt auf dem Laufwerk auf Cloud SQL Enterprise Plus gespeichert werden, wechselt der Upgradeprozess den Speicherort der für die Wiederherstellung zu einem bestimmten Zeitpunkt verwendeten Transaktionslogs auf Cloud Storage. Weitere Informationen finden Sie unter Instanz mithilfe eines direkten Upgrades auf Cloud SQL Enterprise Plus aktualisieren.
Alle Cloud SQL Enterprise-Instanzen, die Sie nach dem 31. Mai 2024 mit aktivierter Wiederherstellung zu einem bestimmten Zeitpunkt erstellen, speichern Logs, die für die Wiederherstellung zu einem bestimmten Zeitpunkt in Cloud Storage verwendet werden.
Wenn Ihre Instanz Cloud Storage zum Speichern von Transaktionslogs verwendet, werden die Logs in derselben Region wie die primäre Instanz gespeichert. Diese Logs werden bis zu 35 Tage lang für Cloud SQL Enterprise Plus und 7 Tage lang für Cloud SQL Enterprise gespeichert. Es fallen keine zusätzlichen Kosten pro Instanz an.
Weitere Informationen zum Prüfen des Speicherorts der für die Wiederherstellung zu einem bestimmten Zeitpunkt verwendeten Transaktions logs finden Sie unter Prüfen, wo Transaktionslogs für Ihre Instanz gespeichert sind.
Bei Instanzen, die Transaktionslogs nur auf dem Laufwerk speichern, können Sie den Speicherort der für die Wiederherstellung zu einem bestimmten Zeitpunkt verwendeten Transaktionslogs mit der gcloud CLI oder der Cloud SQL Admin API von Laufwerk zu Cloud Storage ändern. Weitere Informationen finden Sie unter Transaktionslogspeicher zu Cloud Storage wechseln.
So sorgen Sie dafür, dass Logs für Ihre Instanz in Cloud Storage statt auf dem Laufwerk gespeichert werden:
- Prüfen Sie die Netzwerkarchitektur der Instanz. Wenn sich die Instanz in der alten Netzwerkarchitektur befindet, dann aktualisieren Sie sie auf die neue Netzwerkarchitektur.
Wenn die Größe Ihrer Logs auf dem Laufwerk Leistungsprobleme für Ihre Instanz verursacht, deaktivieren Sie die Wiederherstellung zu einem bestimmten Zeitpunkt und aktivieren Sie sie noch einmal. Dadurch wird sichergestellt, dass neue Logs in Cloud Storage statt auf dem Laufwerk gespeichert werden.
Aufbewahrungsdauer für Logs
Cloud SQL speichert Transaktionslogs in Cloud Storage bis zu dem
Wert, der in der
transactionLogRetentionDays
Konfigurationseinstellung für die Wiederherstellung zu einem bestimmten Zeitpunkt festgelegt ist. Dieser Wert kann zwischen 1 und 35 Tagen für Cloud SQL Enterprise Plus und 1 bis 7 Tage für Cloud SQL Enterprise liegen. Wenn für diesen Parameter kein Wert festgelegt ist, beträgt die Standardaufbewahrungsdauer für Transaktionslogs 14 Tage für Cloud SQL Enterprise Plus-Instanzen und 7 Tage für Cloud SQL Enterprise-Instanzen. Weitere
Informationen zum Festlegen der Aufbewahrungsdauer für Transaktionslogs
finden Sie unter Aufbewahrungsdauer für Transaktionslogs festlegen.
Obwohl eine Instanz die für die Wiederherstellung zu einem bestimmten Zeitpunkt verwendeten Transaktionslogs in Cloud Storage speichert, werden auch eine kleinere Anzahl doppelter Transaktionslogs auf dem Laufwerk aufbewahrt, um die Replikation der Logs in Cloud Storage zu ermöglichen. Wenn Sie eine Instanz mit aktivierter Wiederherstellung zu einem bestimmten Zeitpunkt erstellen, speichert die Instanz ihre Transaktionslogs für die Wiederherstellung zu einem bestimmten Zeitpunkt standardmäßig in Cloud Storage. Cloud SQL legt außerdem den Wert der Flags expire_logs_days und binlog_expire_logs_seconds automatisch auf den Wert fest, der einem Tag entspricht. Das entspricht einem Tag Logs auf dem Laufwerk.
Bei Transaktionslogs für die Wiederherstellung zu einem bestimmten Zeitpunkt, die auf dem Laufwerk gespeichert sind, die zu Cloud Storage verschoben werden oder bereits zu Cloud Storage verschoben wurden , speichert Cloud SQL die Logs für den Mindestwert, der für eine der folgenden Konfigurationen festgelegt ist:
- Die Konfigurationseinstellung
transactionLogRetentionDaysfür Sicherungen - Das
expire_logs_daysoder dasbinlog_expire_logs_secondsFlag
Cloud SQL legt keine Werte für diese Flags fest, wenn die Transaktionslogs auf dem Laufwerk gespeichert sind, zu Cloud Storage verschoben werden oder bereits zu Cloud Storage verschoben wurden. Wenn Logs auf dem Laufwerk gespeichert sind, kann das Ändern der Werte dieser Flags das Verhalten der Wiederherstellung zu einem bestimmten Zeitpunkt und die Anzahl der Tage beeinflussen, für die Logs auf dem Laufwerk gespeichert werden. Während der Speicherort der Logs zu Cloud Storage verschoben wird, können Sie die Flagwerte nicht ändern.
Wir empfehlen außerdem, keinen der Flagwerte auf 0 zu setzen. Weitere
Informationen finden Sie unter
Datenbank-Flags konfigurieren.
- Konfigurationseinstellung
transactionLogRetentionDays - Datenbank-Flag
expire_logs_days - Datenbank-Flag
binlog_expire_logs_seconds
Um Leistungsprobleme zu vermeiden, sollten Sie den Wert der Flags beispielsweise über mehrere Tage hinweg jeden Tag um einen Tag senken. So werden nicht alle Transaktionslogs gleichzeitig von Cloud SQL gelöscht.
Bei
Instanzen mit kundenverwaltetem Verschlüsselungsschlüssel (CMEK),
werden Transaktionslogs mit der neuesten Version des
CMEK verschlüsselt. Für die Wiederherstellung ist die neueste Schlüsselversion für alle Tage erforderlich, die im Parameter retained-transaction-log-days aufbewahrt werden.
Einschränkungen der Wiederherstellung zu einem bestimmten Zeitpunkt
Die folgenden Einschränkungen gelten, wenn die Wiederherstellung zu einem bestimmten Zeitpunkt für Ihre Instanz aktiviert ist und die Größe Ihrer Transaktionslogs auf dem Laufwerk ein Problem für Ihre Instanz verursacht:
- Sie können die Wiederherstellung zu einem bestimmten Zeitpunkt deaktivieren und wieder aktivieren, damit Cloud SQL Logs in Cloud Storage in derselben Region wie die Instanz speichert. Cloud SQL löscht jedoch alle vorhandenen Logs, sodass Sie die Wiederherstellung zu einem bestimmten Zeitpunkt erst wieder ab dem Zeitpunkt ausführen können, zu dem Sie sie wieder aktiviert haben.
- Sie können die Speichergröße der Instanz erhöhen, die erhöhte Speichernutzung der Größe des Transaktionslogs könnte jedoch nur temporär sein.
- Damit unerwartete Speicherprobleme vermieden werden, empfehlen wir die Aktivierung von automatischen Speichererweiterungen. Diese Empfehlung gilt nur, wenn die Wiederherstellung zu einem bestimmten Zeitpunkt für Ihre Instanz aktiviert ist und Ihre Logs auf dem Laufwerk gespeichert sind.
- Die Wiederherstellung zu einem bestimmten Zeitpunkt kann für Ihre Zielinstanz Cloud SQL nicht aktiviert werden, wenn sie mehrere Datenbanken mit demselben physischen Namen hat.
Datenbank-Snapshots
Sie können SQL Server-Datenbank-Snapshots nicht für Datenbanken in einer Instanz verwenden, für die die Wiederherstellung zu einem bestimmten Zeitpunkt aktiviert ist.
Datenbank-Snapshots können die vollständige Datenbanksicherung und Transaktionslogsicherung beeinträchtigen, auf die die Wiederherstellung zu einem bestimmten Zeitpunkt angewiesen ist. Diese Beeinträchtigung kann verhindern, dass die Wiederherstellung zu einem bestimmten Zeitpunkt für Datenbanken in der Instanz erfolgreich durchgeführt wird.
Datenbankwiederherstellungsmodell für die Wiederherstellung zu einem bestimmten Zeitpunkt
Wenn Sie die Wiederherstellung zu einem bestimmten Zeitpunkt für eine Instanz aktivieren, legt Cloud SQL das Wiederherstellungsmodell der vorhandenen und nachfolgenden Datenbanken automatisch auf das vollständige Wiederherstellungsmodell fest.
Weitere Informationen zu SQL Server-Wiederherstellungsmodellen finden Sie in der Microsoft-Dokumentation.
Eine detaillierte Anleitung zur Durchführung einer Wiederherstellung zu einem bestimmten Zeitpunkt finden Sie unter [Wiederherstellung zu einem bestimmten Zeitpunkt verwenden][perform-pitr].
Gelöschte Instanz mit der Wiederherstellung zu einem bestimmten Zeitpunkt wiederherstellen
Mit der Wiederherstellung zu einem bestimmten Zeitpunkt können Sie eine Cloud SQL-Instanz nach dem Löschen wiederherstellen. Damit Sie diese Funktion verwenden können, müssen die Wiederherstellung zu einem bestimmten Zeitpunkt und die Aufbewahrung von Sicherungen für Ihre Instanz aktiviert sein, bevor die Instanz gelöscht wird. Wenn die Wiederherstellung zu einem bestimmten Zeitpunkt aktiviert ist, werden die entsprechenden Logs auch nach dem Löschen der Instanz aufbewahrt.
Nachdem eine Instanz gelöscht wurde, gelten für die Logs der Wiederherstellung zu einem bestimmten Zeitpunkt weiterhin die Aufbewahrungseinstellungen, die für die Instanz festgelegt wurden, als sie aktiv war. Die Logs der Wiederherstellung zu einem bestimmten Zeitpunkt laufen nach dem Löschen der Instanz gemäß den Aufbewahrungseinstellungen ab. Der Zeitraum wird basierend auf der Aufbewahrungsdauer für die Wiederherstellung zu einem bestimmten Zeitpunkt definiert, die für die Instanz vor dem Löschen festgelegt wurde. Wenn für Ihre Cloud SQL Enterprise Plus-Instanz beispielsweise eine Aufbewahrungsdauer von 14 Tagen für die Wiederherstellung zu einem bestimmten Zeitpunkt festgelegt ist, wird der letzte Log der Wiederherstellung zu einem bestimmten Zeitpunkt 14 Tage nach dem Löschen der Instanz gelöscht. Wenn ein Log der Wiederherstellung zu einem bestimmten Zeitpunkt abläuft, kann es nicht wiederhergestellt werden.
Da Instanznamen nach dem Löschen einer Instanz in Cloud SQL wiederverwendet werden können, können aufbewahrte Logs der Wiederherstellung zu einem bestimmten Zeitpunkt in Google Cloud mit den folgenden Feldern identifiziert werden:
instance_deletion_timelog_retention_days
Mithilfe dieser Felder können Sie feststellen, ob ein Log der Wiederherstellung zu einem bestimmten Zeitpunkt zu einer gelöschten Instanz gehört.
Der Zeitraum für die Wiederherstellung zu einem bestimmten Zeitpunkt wird als frühester und spätester Wiederherstellungszeitpunkt definiert, zu dem Sie Ihre Instanz mit der Wiederherstellung zu einem bestimmten Zeitpunkt wiederherstellen können. Informationen zum Ermitteln des frühesten und spätesten Wiederherstellungszeitpunkts für Ihre gelöschte Instanz finden Sie unter Frühesten und spätesten Wiederherstellungszeitpunkt abrufen.
Informationen zum Wiederherstellen einer Instanz mit der Wiederherstellung zu einem bestimmten Zeitpunkt nach dem Löschen der Instanz finden Sie unter Wiederherstellung zu einem bestimmten Zeitpunkt für eine gelöschte Instanz durchführen.
Anforderungen für die Wiederherstellung in einer neuen Instanz
Wenn Sie Ihre Instanz in einer neuen Instanz wiederherstellen, beachten Sie die folgenden Anforderungen:
- Die Zielinstanz muss eine Datenbank der gleichen Version haben wie die Instanz, von der die Sicherung erstellt wurde.
Beim Erstellen einer neuen Instanz ist die Funktion
storageAutoResizestandardmäßig aktiviert. Alle nachfolgend erstellten Sicherungen übernehmen dieselbe Einstellung fürstorageAutoResize. Das bedeutet, dass die Speicherkapazität der Instanz bei der Wiederherstellung einer Sicherung in einer neuen oder vorhandenen Instanz nach Bedarf automatisch angepasst wird. Für ältere Instanzen ist diese Funktion nicht aktiviert. Informationen zum Prüfen der Instanzeinstellungen finden Sie unter Instanzeinstellungen anzeigen. Diese Anforderung gilt unabhängig davon, ob Sie die Wiederherstellung zu einem bestimmten Zeitpunkt für eine einzelne Datenbank durchführen.Die Zielinstanz muss den Status
RUNNABLEhaben.
Einschränkungen der Wiederherstellungsrate
Es sind maximal drei Wiederherstellungsvorgänge alle 30 Minuten pro Instanz, Region und Projekt möglich. Wenn ein Wiederherstellungsvorgang fehlschlägt, wird er nicht auf dieses Kontingent angerechnet. Wenn Sie das Limit erreichen, schlägt der Vorgang mit einer Fehlermeldung fehl, die Sie darüber informiert, wann Sie den Vorgang noch einmal ausführen können.
Cloud SQL verwendet Tokens aus einem Bucket, um zu ermitteln, wie viele Wiederherstellungsvorgänge gleichzeitig verfügbar sind. Für jede Sicherung gibt es für jedes Zielprojekt und jede Zielregion eine Bucket. Die Zielinstanzen aus demselben Projekt teilen einen Bucket, wenn sie sich in derselben Region befinden. Jeder Bucket kann maximal drei Tokens enthalten, die Sie für Wiederherstellungsvorgänge verwenden können. Alle 10 Minuten wird dem Bucket ein neues Token hinzugefügt. Wenn der Bucket voll ist, läuft das Token über.
Jedes Mal, wenn Sie einen Wiederherstellungsvorgang ausführen, wird ein Token aus dem Bucket gewährt. Wenn der Vorgang erfolgreich ist, wird das Token aus dem Bucket entfernt. Wenn der Vorgang fehlschlägt, wird das Token an den Bucket zurückgegeben. Dies wird im folgenden Diagramm veranschaulicht:

In der folgenden Abbildung sind beispielsweise Backup1, Backup2 und Backup3 die Sicherungen derselben Quellinstanz.
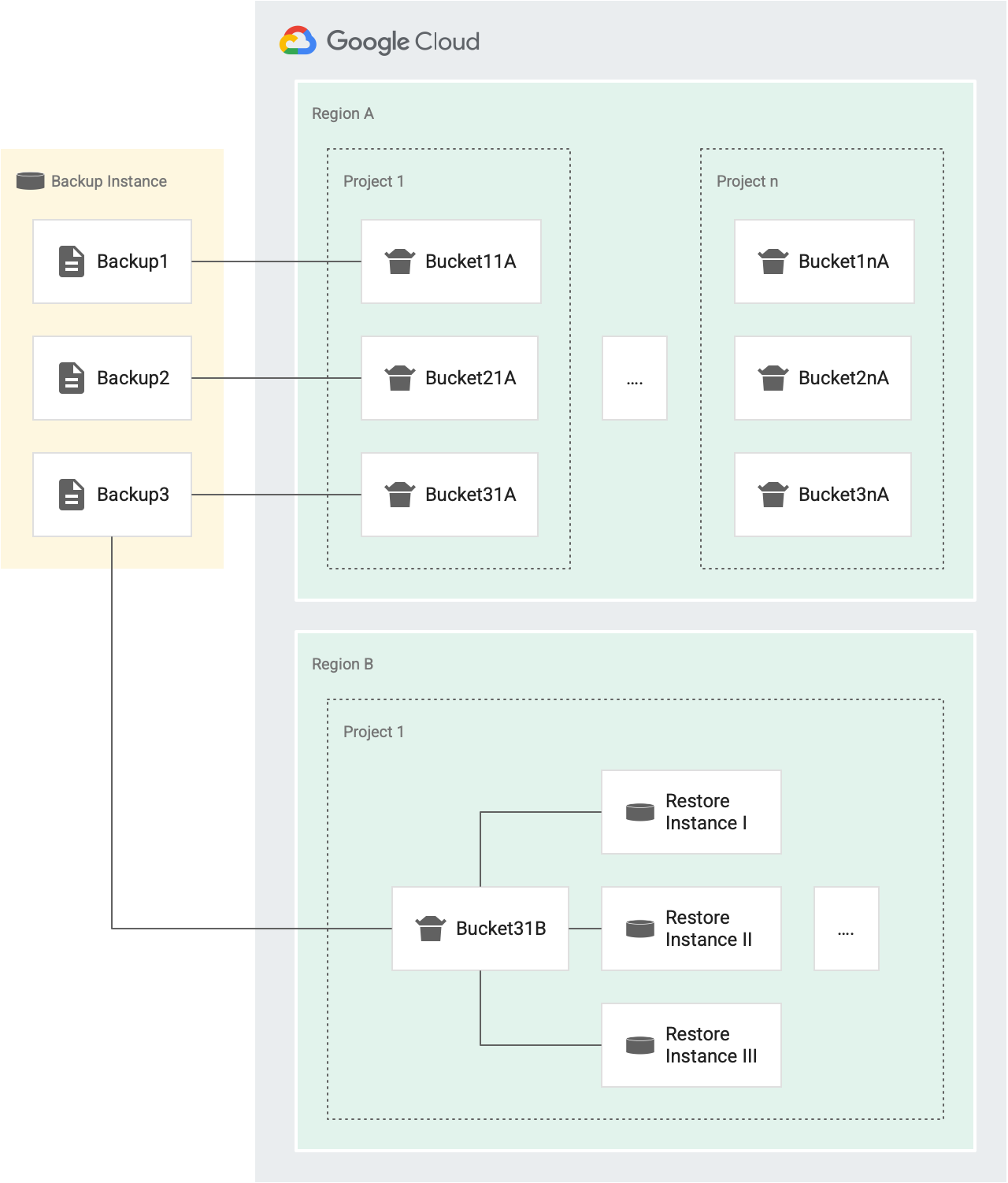
- Jede Sicherung (Backup1, Backup2 und Backup3) hat einen eigenen Bucket mit Tokens für Wiederherstellungsvorgänge, die auf verschiedene Instanzen in Projekt 1 in Region A (Bucket11A, Bucket21A und Bucket31A) ausgerichtet sind. Da jede Sicherung einen eigenen Bucket hat, können Sie jede Sicherung dreimal alle 30 Minuten wiederherstellen.
- Jede Sicherung hat einen Bucket für ein separates Projekt und für eine separate Region.
Wenn es beispielsweise fünf Projekte in einer Region gibt, gibt es fünf Buckets für diese Sicherung in dieser Region, einer in jedem Projekt. In der vorherigen Abbildung haben wir zwei Projekte in Region A: Projekt 1 und Projekt n.
- Backup1 hat zwei Buckets mit Tokens für Wiederherstellungsvorgänge in Region A. Einen Bucket für Projekt 1 (Bucket11A) und einen Bucket für Projekt n (Bucket1nA).
- In ähnlicher Weise hat Backup3 zwei Buckets für Wiederherstellungsvorgänge in Region A. Eine für Projekt 1 (Bucket31A) und eine für Projekt n (Bucket3nA).
- Backup3 hat einen Bucket in Region B für Projekt1, da alle Instanzen im selben Zielprojekt und in derselben Zielregion einen Bucket gemeinsam nutzen.
Nächste Schritte
- Daten aus einer Sicherung wiederherstellen
- Wiederherstellung zu einem bestimmten Zeitpunkt (PITR) verwenden