
Cloud SQL vous permet de restaurer vos instances à partir d'une sauvegarde ou d'effectuer une récupération à un moment précis (PITR). Vous pouvez ainsi récupérer une instance à une période ou à un moment spécifique en restaurant la sauvegarde sur une instance existante ou sur une nouvelle instance. Pour effectuer une restauration, vous pouvez utiliser la sauvegarde d'une instance active ou supprimée. L'opération de restauration prend les paramètres, les bases de données et les utilisateurs de l'instance source, et les définit dans l'instance cible que vous choisissez.
Lorsque vous effectuez une restauration sur une nouvelle instance, l'instance cible peut se trouver dans une région ou un projet différent de celui de l'instance source. L'instance cible peut également utiliser un nombre de cœurs ou une quantité de mémoire différents de ceux de l'instance source.
Cloud SQL définit toujours la capacité de stockage de l'instance cible sur la valeur maximale de la taille du disque configuré et du disque de sauvegarde. La taille du disque de sauvegarde est égale à celle du disque au moment de la sauvegarde.
Lorsque vous effectuez une restauration sur une instance, tenez compte des points suivants :
- L'opération de restauration écrase toutes les données de l'instance cible.
- Les options de l'instance source ne sont pas restaurées. Toutes les options précédemment définies sur l'instance cible sont conservées après la restauration.
- L'instance cible n'est pas disponible pour les connexions pendant l'opération de restauration ; les connexions existantes sont perdues.
- Si vous restaurez une instance qui possède des instances dupliquées avec accès en lecture, vous devez supprimer toutes les instances dupliquées et les recréer une fois l'opération de restauration terminée.
- L'opération de restauration redémarre l'instance.
- Une fois la restauration effectuée à partir d'une sauvegarde, les configurations de sauvegarde de l'instance cible sont définies sur les valeurs par défaut. Si votre instance source disposait de configurations de sauvegarde personnalisées ou utilisait des sauvegardes améliorées, vous devrez mettre à jour les configurations de sauvegarde une fois la restauration terminée.
Restaurer à l'aide d'une sauvegarde
Cloud SQL vous permet de restaurer une instance à l'aide d'une sauvegarde. Vous pouvez utiliser une sauvegarde d'une instance active ou supprimée, et l'utiliser pour effectuer une restauration sur une instance nouvelle ou existante. Vous pouvez utiliser n'importe quelle sauvegarde disponible pour restaurer l'instance. Pour en savoir plus sur le fonctionnement des sauvegardes dans Cloud SQL, consultez la présentation des sauvegardes.
Lorsque vous restaurez une instance à l'aide d'une sauvegarde, vous pouvez effectuer les opérations suivantes :
- Restaurer dans une nouvelle instance
- Restaurer sur une instance existante
- Restaurer sur une instance d'un autre projet ou d'une autre région
En cas de panne, vous pouvez toujours récupérer la liste des sauvegardes d'un projet particulier à partir duquel effectuer une restauration.
Pour restaurer votre instance à l'aide d'une sauvegarde, consultez la section Restaurer une instance à l'aide d'une sauvegarde.
Restaurer une instance configurée pour utiliser les CMEK à l'aide de sauvegardes améliorées
Lorsque vous utilisez des instances configurées pour utiliser les CMEK avec des sauvegardes améliorées, vos sauvegardes sont protégées par la même CMEK que l'instance. Cela peut être un élément important de votre plan de sauvegarde pour les instances qui nécessitent un chiffrement CMEK, car il conserve vos sauvegardes chiffrées avec une CMEK dans un projet distinct où elles peuvent être restaurées même si votre projet de charge de travail d'origine est compromis ou supprimé.
Lorsque vous restaurez une sauvegarde améliorée d'une instance configurée pour utiliser les CMEK dans une nouvelle instance, vous pouvez choisir l'une des options de chiffrement suivantes pour la nouvelle instance :
- Utiliser la même clé Cloud KMS que l'instance d'origine. Il s'agit du comportement par défaut.
- Sélectionner une autre clé Cloud KMS pour l'instance cible. Pour sélectionner une autre clé, définissez l'option
--disk-encryption-keydans la commande de restauration. - Revenir à Google-owned and Google-managed encryption keys pour l'instance cible.
Pour utiliser GMEK, définissez l'option
--clear-disk-encryptiondans la commande de restauration.
Récupération à un moment précis (PITR)
La récupération PITR vous permet de restaurer votre instance à un moment spécifique de la base de données. Par exemple, en cas de perte de données due à une erreur, vous pouvez restaurer une base de données pour qu'elle revienne à l'état qu'elle avait avant que l'erreur se produise. Contrairement à la restauration à l'aide d'une sauvegarde, la récupération PITR crée toujours une nouvelle instance. Vous ne pouvez pas effectuer de récupération PITR sur une instance existante. La nouvelle instance hérite des paramètres de l'instance source, comme lorsque vous créez un clone.
Si vous créez une instance Cloud SQL Enterprise Plus, la récupération PITR est activée par défaut. Vous devez désactiver manuellement la fonctionnalité si vous ne souhaitez pas qu'elle soit activée.
Si vous créez une instance Cloud SQL Enterprise dans la Google Cloud console, la récupération PITR est activée par défaut. Sinon, si vous créez l'instance à l'aide de la gcloud CLI, de Terraform ou de l'API Cloud SQL Admin, la récupération PITR est désactivée par défaut. Pour activer la récupération PITR pour ces instances, vous devez l'activer manuellement.
Pour obtenir des instructions détaillées sur l'exécution d'une récupération PITR, consultez la page Utiliser la récupération à un moment précis (PITR).
Stockage des journaux pour la récupération PITR
La récupération PITR utilise la journalisation WAL (Write-Ahead Logging) pour archiver les journaux. Lorsque vous restaurez une instance existante à l'aide d'une sauvegarde, ces journaux d'archive sont supprimés et ne sont pas disponibles pour effectuer une récupération PITR. Seuls les nouveaux journaux générés une fois la restauration terminée peuvent être utilisés pour la récupération PITR.
Le 9 janvier 2023 , nous avons lancé le stockage des journaux de transactions pour la récupération PITR dans Cloud Storage. Depuis ce lancement, les conditions suivantes s'appliquent :
Toutes les instances de l'édition Cloud SQL Enterprise Plus stockent leurs journaux WAL utilisés pour la récupération PITR dans Cloud Storage. Seules les instances Cloud SQL Enterprise Plus que vous avez mises à niveau depuis l'édition Cloud SQL Enterprise avant le 1er avril 2024 et pour lesquelles la récupération PITR a été activée avant le 9 janvier 2023 continuent de stocker leurs journaux pour la récupération PITR sur le disque.
Les instances Cloud SQL Enterprise créées avec la récupération PITR activée avant le 9 janvier 2023 continuent de stocker leurs journaux pour la récupération PITR sur le disque.
Si vous mettez à niveau une instance Cloud SQL Enterprise après le 9 janvier 2023 qui stocke les journaux de transactions pour la récupération PITR sur disque vers l'édition Cloud SQL Enterprise Plus, le processus de mise à niveau change l'emplacement de stockage des journaux de transactions utilisés pour la récupération PITR vers Cloud Storage pour vous. Pour en savoir plus, consultez Mettre à niveau une instance vers Cloud SQL Enterprise Plus en utilisant la mise à niveau sur place.
Toutes les instances Cloud SQL Enterprise que vous créez avec la récupération PITR activée après le 9 janvier 2023 stockent les journaux utilisés pour la récupération PITR dans Cloud Storage.
Si votre instance utilise Cloud Storage pour stocker les journaux WAL, les journaux sont stockés dans la même région que l'instance principale. Ces journaux sont stockés pendant 35 jours maximum pour l'édition Cloud SQL Enterprise Plus et 7 jours pour l'édition Cloud SQL Enterprise, sans générer de coûts supplémentaires par instance.
Pour savoir comment vérifier l'emplacement de stockage des journaux de transactions utilisés pour la récupération PITR, consultez la section Vérifier où les journaux de transactions sont stockés pour votre instance.
Pour les instances qui ne stockent les journaux WAL que sur le disque, vous pouvez changer l'emplacement de stockage des journaux de transactions utilisés pour la récupération PITR du disque vers Cloud Storage à l'aide de gcloud CLI ou de l'API Cloud SQL Admin. Pour en savoir plus, consultez la section Passer au stockage des journaux de transactions dans Cloud Storage.
Pour vous assurer que les journaux de votre instance sont stockés dans Cloud Storage plutôt que sur le disque, procédez comme suit :
- Vérifiez l'architecture réseau de l'instance. Si l'instance utilise l'ancienne architecture réseau, alors mettez-la à niveau vers la nouvelle architecture réseau.
Si la taille de vos journaux sur le disque entraîne des problèmes de performances pour votre instance, désactivez la récupération PITR, puis réactivez-la. Cela garantit que les nouveaux journaux sont stockés dans Cloud Storage plutôt que sur le disque.
Durée de conservation des journaux
Cloud SQL conserve les journaux de transactions dans Cloud Storage jusqu'à atteindre la
valeur définie dans le
transactionLogRetentionDays
paramètre de configuration de la récupération PITR. Cette valeur peut aller de 1 à 35 jours pour l'édition Cloud SQL Enterprise Plus et de 1 à 7 jours pour l'édition Cloud SQL Enterprise. Si aucune valeur n'est définie pour ce paramètre, la période de conservation des journaux de transactions par défaut est de 14 jours pour les instances Cloud SQL Enterprise Plus et de sept jours pour les instances de l'édition Cloud SQL Enterprise. Pour en savoir plus sur la définition des jours de conservation des journaux de transactions,
consultez Définir la durée de conservation des journaux de transactions.
Bien qu'une instance stocke les journaux WAL utilisés pour la récupération PITR dans Cloud Storage, elle conserve également un nombre plus faible de journaux WAL sur le disque pour permettre leur réplication sur Cloud Storage. Par défaut, lorsque vous créez une instance pour laquelle la récupération PITR est activée, l'instance stocke ses journaux WAL pour la récupération PITR dans Cloud Storage. Cloud SQL définit également la valeur des options expire_logs_days et binlog_expire_logs_seconds sur l'équivalent d'un jour automatiquement. Cela se traduit par un jour de journaux sur le disque.
Pour les journaux WAL de récupération PITR stockés sur le disque, qui sont en cours de transfert vers Cloud Storage ou qui ont déjà été transférés vers Cloud Storage, Cloud SQL conserve les journaux selon la valeur minimale définie pour l'une des configurations suivantes :
- Le paramètre de configuration de sauvegarde
transactionLogRetentionDays - L'option
expire_logs_daysoubinlog_expire_logs_seconds
Cloud SQL ne définit aucune valeur pour ces options si les journaux WAL sont stockés sur le disque, sont en cours de transfert vers Cloud Storage ou ont déjà été transférés vers Cloud Storage. Lorsque les journaux sont stockés sur le disque, la modification des valeurs de ces options peut affecter le comportement de la récupération PITR et le nombre de jours durant lesquels les journaux sont stockés sur le disque. Pendant le transfert de l'emplacement de stockage des journaux vers Cloud Storage, vous ne pouvez pas modifier les valeurs des options.
Nous vous déconseillons également de configurer la valeur de l'une ou l'autre des options sur 0. Pour en savoir plus, consultez la page
Configurer des options de base de données.
- Paramètre de configuration
transactionLogRetentionDays - Option de base de données
expire_logs_days - Option de base de données
binlog_expire_logs_seconds
Par exemple, pour éviter les problèmes de performances, réduisez la valeur des options d'un jour, chaque jour, sur plusieurs jours. Par conséquent, Cloud SQL ne supprime pas tous les journaux WAL simultanément.
Pour
les instances où la clé de chiffrement gérée par le client (CMEK) est activée,
les journaux WAL sont chiffrés à l'aide de la dernière version de la
CMEK. Pour effectuer une restauration, la dernière version de la clé est requise pour tous les jours conservés dans le cadre du paramètre retained-transaction-log-days.
Limites de la récupération PITR
Les limites suivantes sont associées à l'activation de la récupération PITR sur votre instance et à la taille de vos journaux de transactions sur le disque qui pose problème pour votre instance :
- Vous pouvez désactiver la récupération PITR et la réactiver pour vous assurer que Cloud SQL stocke les journaux dans Cloud Storage dans la même région que l'instance. Toutefois, Cloud SQL supprime tous les journaux existants. Vous ne pouvez donc pas effectuer d'opération de récupération PITR antérieure à l'heure à laquelle vous avez réactivé la récupération PITR.
- Vous pouvez augmenter l'espace de stockage disponible sur l'instance. Sachez toutefois qu'une augmentation importante de l'espace disque occupé par vos journaux de transaction peut être temporaire.
- Pour éviter les problèmes de stockage inattendus, nous vous recommandons d'activer l'augmentation automatique de l'espace de stockage. Cette recommandation ne s'applique que si la récupération PITR est activée sur votre instance et que vos journaux sont stockés sur le disque.
Pour obtenir des instructions détaillées sur l'exécution d'une récupération PITR, consultez la section [Utiliser la récupération à un moment précis (PITR)][perform-pitr].
Restaurer une instance indisponible
Vous pouvez utiliser la récupération PITR pour restaurer une instance Cloud SQL indisponible. La récupération PITR propose généralement un objectif de point de récupération de cinq minutes ou moins.
Si l'instance est indisponible, vous pouvez utiliser l'API pour obtenir l' heure de récupération la plus ancienne et la plus récente à laquelle vous pouvez restaurer l'instance et effectuer la récupération à ce moment précis. Si la zone dans laquelle l'instance est configurée n'est pas accessible, vous pouvez restaurer l'instance dans une autre zone principale ou secondaire en fournissant des valeurs pour les zones préférées.
Supposons qu'une instance Cloud SQL devienne indisponible à 16h00 EST. Si le dernier horaire de récupération est 15h55 EST, vous pouvez restaurer l'instance à ce moment précis.
Restaurer une instance supprimée à l'aide de la récupération PITR
Vous pouvez utiliser la récupération PITR pour restaurer une instance Cloud SQL après sa suppression. Pour utiliser cette fonctionnalité, la récupération PITR et les sauvegardes conservées doivent être activées sur votre instance avant sa suppression. Une fois activés, les journaux PITR sont conservés après la suppression de l'instance.
Une fois l'instance supprimée, les journaux PITR continuent de suivre les paramètres de conservation définis par l'instance lorsqu'elle était active. Les journaux PITR expirent en fonction des paramètres de conservation de manière continue après la suppression de l'instance. La période continue est définie en fonction de la période de conservation PITR définie sur l'instance avant sa suppression. Par exemple, si la période de conservation PITR de votre instance Cloud SQL Enterprise Plus est définie sur 14 jours, le dernier journal PITR sera supprimé 14 jours après la suppression de l'instance. Lorsqu'un journal PITR expire, il ne peut pas être récupéré.
Étant donné que les noms d'instance peuvent être réutilisés après la suppression d'une instance dans Cloud SQL, les journaux PITR conservés peuvent être identifiés dans Google Cloud avec les champs suivants :
instance_deletion_timelog_retention_days
Ces champs vous permettent de déterminer si un journal PITR appartient à une instance supprimée.
La fenêtre de récupération PITR est définie comme les heures de récupération les plus anciennes et les plus récentes disponibles pour restaurer votre instance à l'aide de la récupération PITR. Pour connaître les heures de récupération les plus anciennes et les plus récentes de votre instance supprimée, consultez la section Obtenir l'heure de récupération la plus ancienne et la plus récente.
Pour restaurer une instance à l'aide de la récupération PITR après sa suppression, consultez la section Effectuer une récupération PITR sur une instance supprimée.
Conditions requises pour la restauration sur une nouvelle instance
Lorsque vous restaurez votre instance sur une nouvelle instance, tenez compte des conditions requises suivantes :
- L'instance cible doit avoir la même version de base de données que l'instance à partir de laquelle la sauvegarde a été effectuée.
Lors de la création d'une instance, la fonctionnalité
storageAutoResizeest activée par défaut. Toute sauvegarde créée par la suite hérite du même paramètrestorageAutoResize. Cela signifie que, que vous restauriez une sauvegarde sur une instance nouvelle ou existante, la capacité de stockage de l'instance sera automatiquement redimensionnée si nécessaire. Cette fonctionnalité n'est pas activée sur les instances héritées. Pour vérifier les paramètres de votre instance, consultez la section Afficher les paramètres d'instance.L'instance cible doit être à l'état
RUNNABLE.
Limitations de la fréquence de restauration
Vous êtes autorisé à effectuer au maximum trois opérations de restauration toutes les 30 minutes par instance, par région et par projet. Si une opération de restauration échoue, elle n'est pas comptabilisée dans ce quota. Si vous atteignez la limite, l'opération échoue avec un message d'erreur vous indiquant quand vous pouvez relancer l'opération.
Cloud SQL utilise les jetons d'un bucket pour déterminer combien d'opérations de restauration sont disponibles à un moment donné. Pour chaque sauvegarde, il existe un bucket pour chaque projet et région cible. Les instances cibles d'un même projet partagent un bucket si elles se trouvent dans la même région. Vous pouvez utiliser jusqu'à trois jetons par bucket pour les opérations de restauration. Toutes les 10 minutes, un nouveau jeton est ajouté au bucket. Si le bucket est plein, le jeton "déborde".
Chaque fois que vous effectuez une opération de restauration, un jeton est attribué à partir du bucket. Si l'opération réussit, le jeton est supprimé du bucket. En cas d'échec, le jeton est renvoyé au bucket. Le schéma suivant illustre ce fonctionnement :

Par exemple, dans la figure suivante, "Backup1", "Backup2" et "Backup3" sont les sauvegardes de la même instance source.
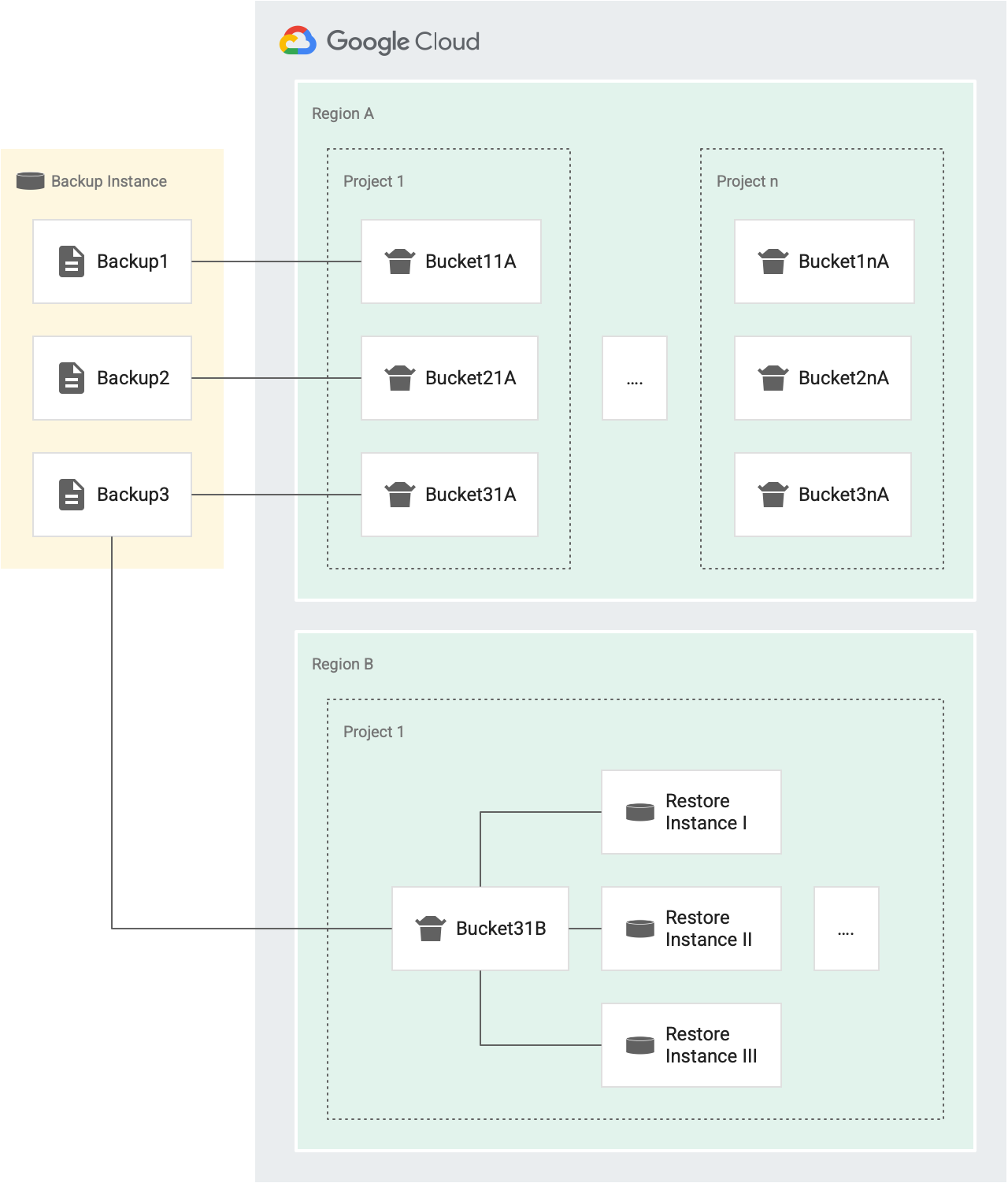
- Chaque sauvegarde (Backup1, Backup2 et Backup3) dispose de son propre bucket de jetons pour les opérations de restauration qui ciblent différentes instances du Projet 1 dans la Région A (Bucket11A, Bucket21A et Bucket31A). Comme chaque sauvegarde possède son propre bucket, vous pouvez restaurer chaque sauvegarde sur la même instance trois fois toutes les trente minutes.
- Chaque sauvegarde comporte un bucket pour un projet distinct et pour une région distincte.
Par exemple, s'il existe cinq projets dans une région, il existe cinq buckets pour cette sauvegarde dans cette région, un dans chaque projet. Dans la figure précédente, nous avons deux projets dans la région A : le Projet 1 et le Projet n.
- Backup1 comporte deux buckets de jetons pour les opérations de restauration dans la Région A. Un bucket pour le Projet 1 (Bucket11A) et un bucket pour le Projet n (Bucket1nA).
- De même, Backup3 comporte deux buckets pour les opérations de restauration dans la Région A. Un pour le Projet 1 (Bucket31A) et un pour le Projet n (Bucket3nA).
- Backup3 comporte un bucket dans la Région B, pour le Projet 1, car toutes les instances du même projet cible et de la même région cible partagent un bucket.
Étapes suivantes
- Effectuer une restauration à partir d'une sauvegarde
- Utiliser la récupération à un moment précis (PITR)