
このドキュメントでは、Cloud SQL の AI アシスタンスを使用して、Cloud SQL でのデータベース負荷が高い場合のトラブルシューティングを行う方法について説明します。Cloud SQL と Gemini Cloud Assist の AI アシスタント機能を使用して、調査、分析、推奨事項の取得を行い、最終的に推奨事項を実装して Cloud SQL のクエリを最適化できます。
Google Cloud コンソールの [Query Insights] ダッシュボードを利用すると、システムでデータベースの負荷が平均よりも高い場合に、データベースを分析し、イベントのトラブルシューティングを行うことができます。Cloud SQL では、選択した期間の 24 時間前のデータを基に、データベースの予想負荷が算出されます。負荷イベントの増加の原因を調べ、パフォーマンス低下の原因を分析できます。最後に、Cloud SQL は、データベースを最適化してパフォーマンスを高めるための推奨事項を提供します。
始める前に
AI アシスタンス機能を使用してデータベースの負荷が高い問題のトラブルシューティングを行うには、次の操作を行います。
必要なロールと権限
AI アシスタンス機能を使ってデータベースの負荷が高い問題のトラブルシューティングを行うために必要なロールと権限については、AI によるモニタリングとトラブルシューティングをご確認ください。
AI アシスタンスを使用する
データベースの負荷が高い場合のトラブルシューティングに AI アシスタンス機能を使用するには、 Google Cloud コンソールの [インスタンスの概要] ページまたは [Query Insights] ダッシュボードに移動します。
インスタンスの概要ページ
次の手順に沿って、[インスタンスの概要] ページで AI アシスタンス機能を使用してデータベースの負荷が高い問題のトラブルシューティングを行います。
-
Google Cloud コンソールで、Cloud SQL の [インスタンス] ページに移動します。
- インスタンスの [概要] ページを開くには、インスタンス名をクリックします。
- [概要] ページの [グラフ] メニューで、データベースの指標を選択します。任意の指標を選択できます。
- 省略可: 特定の分析期間を選択するには、[期間] フィルタを使用して、1 時間、6 時間、1 日、7 日、30 日、またはカスタム範囲を選択します。
- [インスタンスのパフォーマンスを分析] をクリックし、AI アシスタンスを使用してデータベース負荷が高い問題のトラブルシューティングを開始します。これにより、[データベースの負荷を分析する] ページが生成されます。
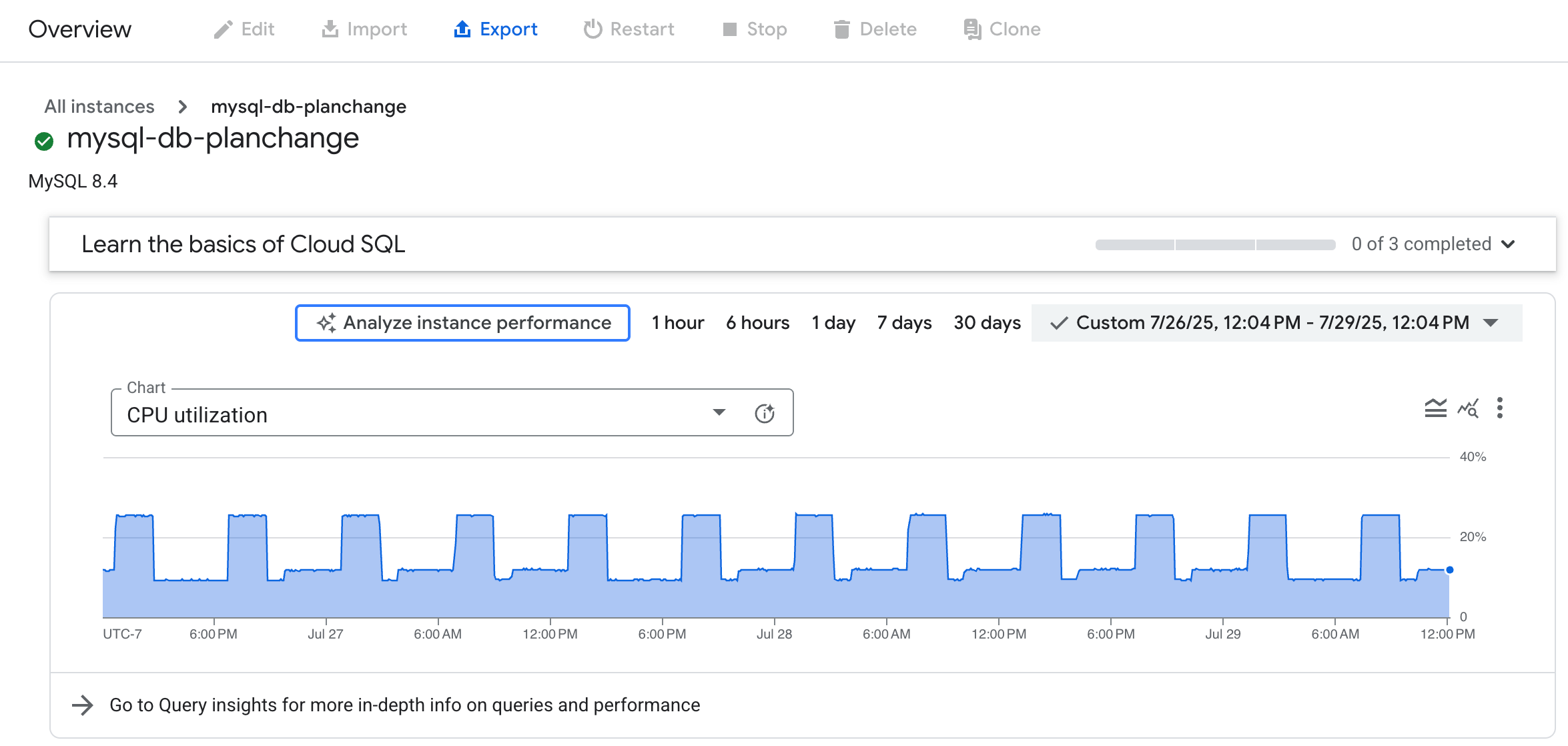
負荷が高いと思われる特定の箇所のデータを見るには、グラフのその部分を拡大します。たとえば、負荷が高い箇所では、CPU 使用率が 100% に近い値で示されている可能性があります。拡大表示するには、グラフの一部をクリックして選択します。

Query Insights ダッシュボード
次の手順に沿って、[Query Insights] ダッシュボードで AI アシスタンス機能を使用してデータベースの負荷が高い問題のトラブルシューティングを行います。
-
Google Cloud コンソールで、Cloud SQL の [インスタンス] ページに移動します。
- インスタンスの [概要] ページを開くには、インスタンス名をクリックします。
- [Query Insights] をクリックして [Query Insights] ダッシュボードを開きます。
- 省略可: [期間] フィルタを使用して、1 時間、6 時間、1 日、7 日、30 日、またはカスタム範囲を選択します。
- [データベースの負荷グラフ] で [インスタンスのパフォーマンスを分析する] をクリックして、データベース負荷について AI アシスタント機能を使ったトラブルシューティングを開始します。これにより、[データベースの負荷を分析する] ページが生成されます。

クエリ実行時間別のデータベース負荷が高いと思われる特定の箇所のデータを見るには、グラフのその部分を拡大します。拡大表示するには、グラフの一部をクリックして選択します。
高いデータベース負荷について分析する
AI アシスタント機能を使用すると、データベースの負荷について詳しく分析し、トラブルシューティングを行うことができます。
[データベースの負荷を分析する] ページで、Cloud SQL インスタンスについての次の詳細を確認できます。
- 分析期間
- CPU 使用率(p99)
- メモリ使用率(p99)
Cloud SQL には、選択した期間のクエリ アクティビティを確認できる MySQL クエリのグラフが表示されます。特定の期間にアクティビティが急増していないかを確認できます。
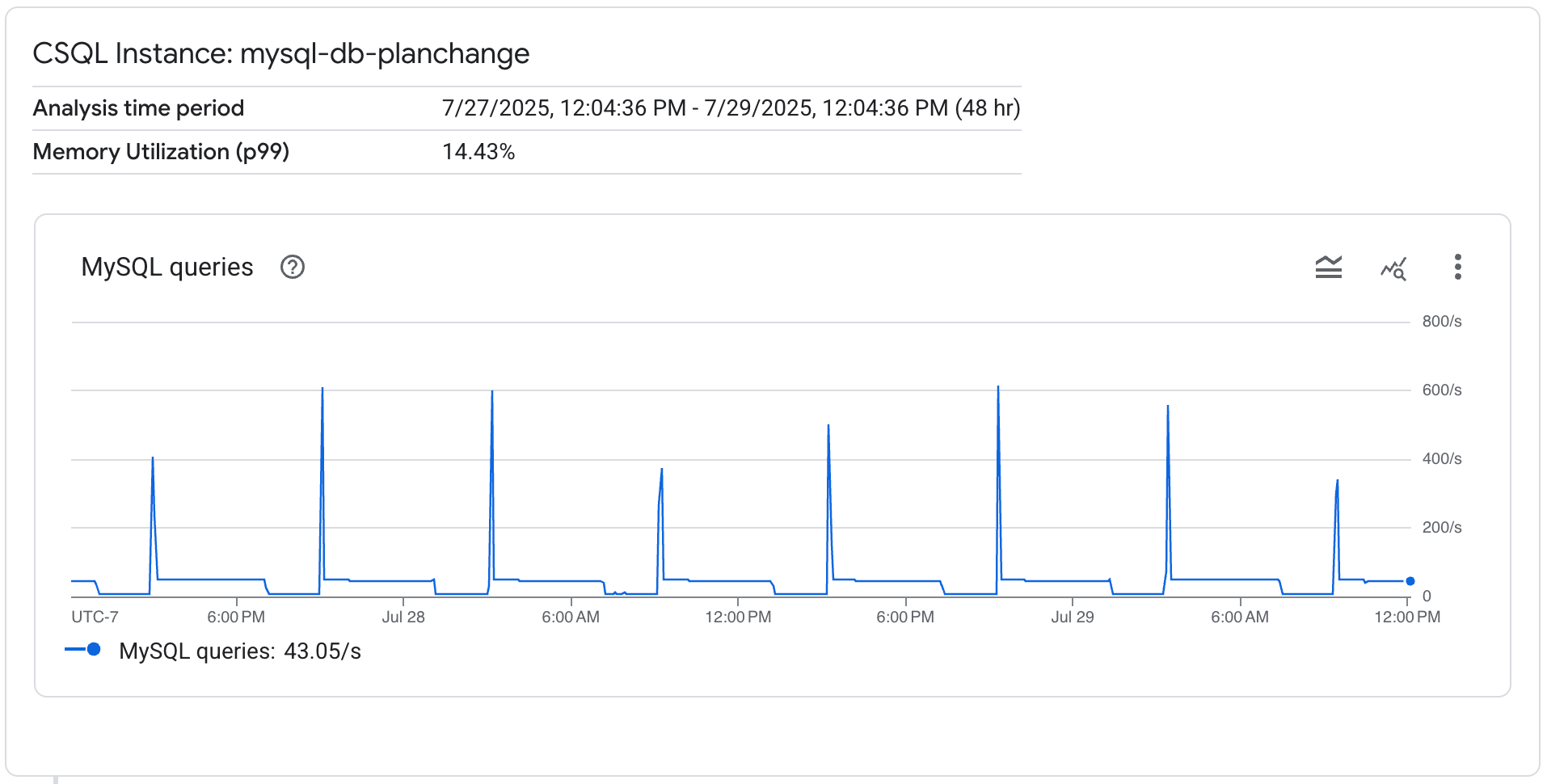
分析期間
Cloud SQL では、[Query Insights] ダッシュボードまたは [インスタンスの概要] ページのデータベース負荷グラフで選択した期間に基づいて、データベースが分析されます。24 時間未満の期間を選択した場合は、Cloud SQL ではその期間全体が分析されます。24 時間を超える期間を選択した場合は、Cloud SQL では直近の 24 時間のみが分析対象となります。
データベースのベースライン パフォーマンス分析の計算を行うために、Cloud SQL では分析期間には 24 時間のベースライン期間が含まれます。選択した期間が月曜日以外の曜日である場合、Cloud SQL では選択した期間の直前 24 時間がベースラインとして使用されます。選択した期間が月曜日の場合は、Cloud SQL では選択した期間の直前 7 日間がベースラインとして使用されます。
状況
Cloud SQL で分析を開始すると、次の主要指標に大幅な変化がないかどうかが確認されます。
- 秒間クエリ数(QPS)
- CPU
- メモリ
- ディスク I/O
Cloud SQL では、分析期間におけるパフォーマンス データ内のデータベースのベースライン集計データが比較されます。主要な指標のしきい値の大幅な変化が検出されると、Cloud SQL ではデータベースで発生するおそれのある状況が示されます。特定された状況は、選択した期間においてデータベースの負荷が高くなっている根本原因を説明している可能性があります。
たとえば、データベースで負荷が高い理由として、次のような状況が複数特定される場合があります。
- スレッドの同時実行が多い
- CPU 使用率の大幅な変化
- ディスク IOPS の大幅な変化
- QPS の大幅な変化

根拠
Cloud SQL では、状況ごとに検出結果の根拠のリストが表示されます。Cloud SQL では、インスタンスから収集された指標に基づいて根拠が生成されます。
各状況には、システム パフォーマンスの異常を検出するために使用される補足的な根拠があります。Cloud SQL では、システム パフォーマンスが特定のしきい値を超えた場合、または特定の時間制限付き条件に合致した場合に異常が検出されます。Cloud SQL では、状況ごとにこれらのしきい値または条件が定義されています。
主な指標の大幅な変化が検出された状況を裏付ける根拠として、次のようなものがあります。
- 合計 QPS: 平均が 18,534.22 から 37,619.86 に、p20 が 3.55 から 5.45 に、p80 が 5.62 から 112,050.8 にそれぞれ変更されています。
- 読み取り QPS: 平均が 1,802.98 から 3,657.93 に、p20 が 1.17 から 2.1 に、p80 が 2.12 から 10,908.8 にそれぞれ変更されています。
- 書き込み QPS: 平均が 1,751.61 から 3,553.48 に、p20 が 0.2 から 0.2 に、p80 が 0.2 から 10,600.13 にそれぞれ変更されています。
- CPU 使用率の変化: CPU 使用率が大きく変化しています。平均が 183.85% 変化しました。p80 が 2,630.49% 変化しました。p20 が 6.75% 変化しました。
- ディスク IOPS: ディスク IOPS が大きく変化しています。平均が 173.39% 変化しました。p80 が 20,832.44% 変化しました。p20 が 1.88% 変化しました。
- 実行中のスレッド: 実行中のスレッド数が 3,166.67% 増加しています。
分析中に取得された証拠を表示するには、各状況をクリックします。証拠は、対応する状況の横のペインに表示されます。
推奨事項
分析されたすべての状況に基づいて、Cloud SQL ではデータベースの負荷が高い問題を解決するために講じることのできる 1 つ以上の推奨事項が提示されます。Cloud SQL は、費用対効果分析とともに推奨事項を提示するため、推奨事項を実装するかどうかを十分な情報に基づいて判断できます。
場合によっては、分析結果に基づいた推奨事項が得られないこともあります。

たとえば、次のような推奨事項が表示されます。
同時実行ワークロードを確認する: Query Insights を使用して、過去と現在のワークロードを分析します。
- CPU 使用率が上昇した場合は、リソースを最も多く消費するクエリに注目して、潜在的な非効率性を特定します。
- CPU 使用率が低下した場合は、待機イベントを確認して、競合の可能性を特定します。
IO 関連のデータベース フラグを確認する: データベース フラグを変更すると、ディスク IOPS が変動する可能性があります。
IOPS に影響する可能性がある主なフラグには、次のようなものがあります(これらに限定されません)。
innodb_buffer_pool_sizeinnodb_redo_log_capacityinnodb_io_capacityinnodb_flush_neighborsinnodb_lru_scan_depthtemptable_max_ram
これらの設定を確認することで、IO の変動の潜在的な原因を特定できる場合があります。
その他の IO 指標を確認する: IOPS の変化をより深く理解するには、次の システム分析情報指標を分析します。
Disk read/write operationsRead/write InnoDB pages
また、Metrics Explorer で他の InnoDB I/O 指標を確認します。
Gemini Cloud Assist でも、トラブルシューティングを続行するヒントやシステムのパフォーマンスについてのサポートが得られます。詳細については、AI アシスタンスによる観察とトラブルシューティングをご覧ください。