
このドキュメントでは、データ エージェント アプリケーションで高い QueryData クエリ精度を実現するために役立つコンテキスト セットを作成して最適化する方法について説明します。コンテキスト エンジニアリング エージェントは、コンテキスト セットの作成と最適化を自動化することで、コンテキスト セットの構築、評価、改善に役立ちます。
コンテキスト セットと QueryData については、コンテキスト セットの概要と QueryData の概要をご覧ください。エンタープライズ グレードのデータ アプリケーションを構築するには、通常、Text-to-SQL モデルの精度を 100% 近くにする必要があります。クエリ結果が正しくないと、アプリケーション全体の使いやすさとユーザー エクスペリエンスに影響します。ビジネスに関連する説明可能な回答を高い精度で実現するには、コンテキスト エンジニアリングが必要です。これは、最適な精度を実現するためにコンテキストを作成して反復的に最適化するプロセスです。
QueryData にビジネス アプリケーションを対象としたコンテキストを提供することで、微妙なユーザーの意図を解決するために必要な正確な ビジネスルールをシステムに提供できます。
コンテキスト エンジニアリング エージェント
コンテキスト エンジニアリング エージェントは、この最適化ワークフローを自動化します。エージェントと会話して、アドホック タスクを処理し、コンテキストを最適化できます。次のリストは、エージェントに指示するために使用できる自然言語プロンプトの例と、エージェントのレスポンスの説明を示しています。これらの例は、コンテキストの構築と最適化に役立ちます。
- 失敗分析のプロンプトの例: "'disney world flights' のようなクエリで空港を正しく識別できるようにコンテキストを更新してください。"エージェントは失敗を分析し、ギャップについて推論し、値検索クエリなどの適切なコンテキスト アイテムを追加することをおすすめします。
- コンテキスト候補のプロンプトの例: "アプリのコードを読み取り、追加する コンテキストを提案してください。"エージェントはコードを解析し、アプリケーションのドメインについて推論し、関連するコンテキスト アイテムを提案します。
- 一括処理のプロンプトの例: "質問 と SQL クエリの例を 10 個示します。これらをテンプレートに変換してください。」エージェントは入力を一括処理し、コンテキスト セットを更新します。
ゴールデン データセットの重要性
コンテキストを最適化するには、まずアプリケーションの自然言語入力に一致するデータセットを作成する必要があります。エージェントは、ユーザーの質問とその想定されるデータベース クエリで構成されるこのゴールデン データセットの構築に役立ちます。ゴールデン データセットを使用すると、次のことができます。
- クエリ パフォーマンスのベースラインを確立する。
- グラウンド トゥルースのデータベース クエリに対して更新を検証する。
- 反復処理全体の精度向上を測定する。
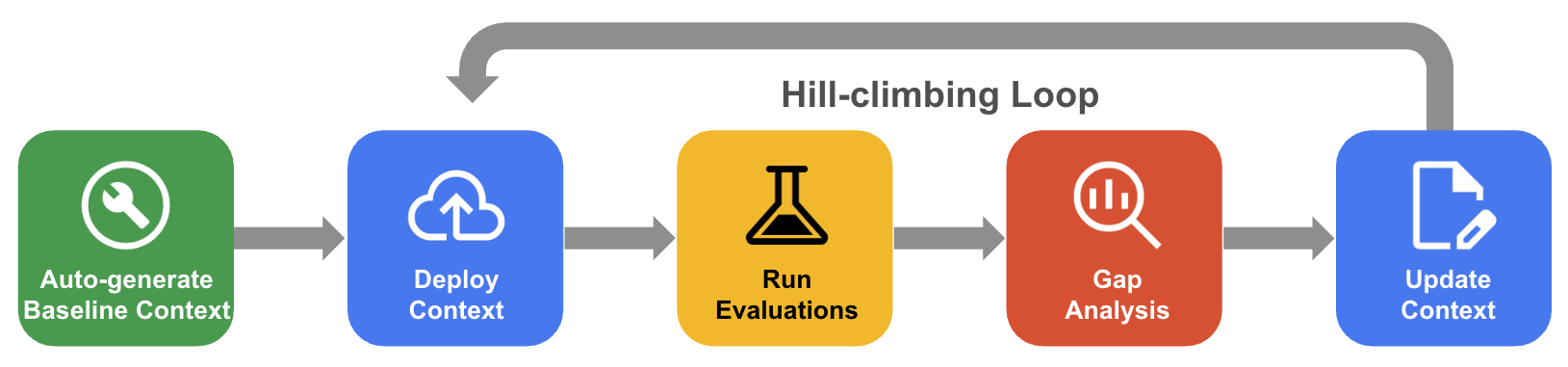
体系的なヒルクライミング プロセス
体系的なヒルクライミングでは、エージェントはゴールデン データセットの評価、ギャップ分析、更新を通じてコンテキスト セットを反復的に改善し、精度を 100% 近くまで高めます。
- ベースライン コンテキストの自動生成: データベース スキーマとアプリケーション アーティファクト から派生した開始コンテキスト セットを作成します。
- ヒルクライミング最適化ワークフロー: エージェントに QueryData の精度を評価させ、失敗のギャップ分析を行い、精度を高めるための 改善案を自動的に提案します。
次の図は、体系的なヒルクライミング ワークフローを示しています。
始める前に
コンテキスト エンジニアリング エージェントを使用する前に、次の前提条件を満たす必要があります。
必要なサービスを有効にする
プロジェクトで次のサービスを有効にします。Cloud SQL インスタンスを準備する
- 既存の Cloud SQL インスタンスにアクセスできることを確認するか、新しいインスタンスを作成します。詳細については、Cloud SQL のインスタンスを作成する をご覧ください。
- テーブルを作成するインスタンスにデータベースを作成します。詳細については、Cloud SQL インスタンスでデータベースを作成する をご覧ください。
必要なロールと権限
- インスタンス レベルで IAM ユーザーまたはサービス アカウントを追加します。詳細については、ユーザー、サービス アカウント、またはグループに IAM ポリシー バインディングを追加するをご覧ください。
- プロジェクト レベルで IAM ユーザーまたはサービス アカウントに
cloudsql.studioUser、cloudsql.instanceUser、geminidataanalytics.queryDataUserのロールを付与します。詳細については、プロジェクトの IAM ポリシー バインディングを追加するをご覧ください。 - 特権ユーザーが IAM ユーザーまたはサービス アカウントにデータベース権限を付与する必要があります。
GRANT SELECT PRIVILEGES ON * TO "IAM_USERNAME";.
詳細については、個々の IAM ユーザーまたはサービス アカウントにデータベース権限を付与するをご覧ください。
Cloud SQL インスタンスに executesql 権限を付与する
Cloud SQL インスタンスに executesql 権限を付与し、Cloud SQL Data API を有効にするには、次のコマンドを実行します。
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
PROJECT_ID: 実際の Google Cloud プロジェクト ID。INSTANCE_ID: Cloud SQL インスタンスの ID。
値検索用にデータベースを準備する
セマンティック値検索とトライグラム値検索を使用するには、ベクトル エンベディングと n-gram インデックスをサポートするように Cloud SQL for MySQL インスタンスを構成する必要があります。
Cloud SQL for MySQL インスタンスでセマンティック値検索を実行できるようにするには、次のフラグを有効にします。
cloudsql_vectorフラグを有効にします。gcloud sql instances patch INSTANCE_NAME --database-flags=cloudsql_vector=onenable-google-ml-integrationフラグを有効にして、Cloud SQL for MySQL インスタンスを Vertex AI と統合できるようにします。gcloud sql instances patch INSTANCE_NAME --enable-google-ml-integration都市のエンベディングを格納するベクトル列を作成する
ALTER TABLE `airports` ADD COLUMN `city_embedding` VECTOR(768);都市名のベクトル エンベディングを生成して保存する
UPDATE `airports` SET `city_embedding` = mysql.ml_embedding('text-embedding-005', `city`) WHERE `city` IS NOT NULL;
Cloud SQL for MySQL インスタンスでトライグラム値検索を実行できるようにするには、次の操作を行います。
ngram_token_sizeフラグを有効にします。gcloud sql instances patch INSTANCE_NAME --database-flags=ngram_token_size=3空港名でトライグラム マッチングを行う FULLTEXT インデックスを作成します。
CREATE FULLTEXT INDEX `idx_ngram_airports_name` ON `airports`(`name`) WITH PARSER ngram;
環境を準備する
コンテキスト セット ファイルは、任意のローカル開発環境または IDE から作成できます。 環境を準備するには、次の手順を行います。
- コンテキスト エンジニアリング エージェントをインストールする
- データベース接続を設定する
コンテキスト エンジニアリング エージェントをインストールする
コンテキスト エンジニアリング エージェントは、基盤となる Python パッケージを管理するために uv を必要とする Model Context Protocol(MCP)サーバーを実行します。
uvをインストールするの手順に沿って、uvをインストールします。uvがインストールされ、コマンドラインからアクセスできることを確認します。uv --version
環境を準備するには、選択したエージェント ハーネス(Antigravity CLI、Claude Code、Gemini CLI など)にコンテキスト エンジニアリング エージェントをインストールします。
選択したエージェント ハーネスに応じて、対応するインストール手順を行います。
Antigravity CLI
Antigravity CLI にコンテキスト エンジニアリング エージェントをインストールする手順は次のとおりです。
- Antigravity CLI をインストールします。Antigravity CLI を使ってみるをご覧ください。
- コンテキスト生成のワークフローを含むコンテキスト エンジニアリング エージェント プラグインをインストールします。VERSION は、必要な リリース バージョンに置き換えます。
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- Antigravity CLI を起動します。
agy
- 省略可。プラグインを更新します。
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
Claude Code にコンテキスト エンジニアリング エージェントをインストールする手順は次のとおりです。
- プラグイン マーケットプレイスを追加します。
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- プラグインをインストールします。
/plugin install db-context-engineering@db-context-enrichment-marketplace
- プラグインを再読み込みして変更を有効にします。
/reload-plugins
- 省略可。プラグインを更新します。
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI(非推奨)
Gemini CLI にコンテキスト エンジニアリング エージェントをインストールする手順は次のとおりです。
- Gemini CLI をインストールします。Gemini CLI を使ってみるをご覧ください。
- 拡張機能をインストールします。
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- 省略可。拡張機能を更新します。
gemini extensions update mcp-db-context-enrichment
データベース接続を設定する
エージェントは、スキーマを取得し、生成された SQL コンテキストの構文を検証するためにデータベース接続を必要とします。エージェントがデータベースとやり取りできるようにするには、認証情報を構成し、データベース接続構成を定義します。
アプリケーションのデフォルト認証情報を構成する
コンテキスト エンジニアリング エージェントから リソースにアクセスするためのユーザー認証情報を提供するには、アプリケーションのデフォルト認証情報(ADC) を構成します。 Google Cloud
- Toolbox MCP サーバー: 認証情報を使用してデータベースに接続し、スキーマを取得して、検証用の SQL を実行します。
- Evalbench: 認証情報を使用して、評価のために QueryData を呼び出します。
ターミナルで次のコマンドを実行して認証します。
gcloud auth application-default loginデータベース接続ファイルを構成する
エージェントはコンテキスト生成にデータベース接続を必要とします。 MCP ツールボックスは、構成ファイル内でこれをサポートし、 定義します。
構成ファイルでは、スキーマの取得または SQL の実行に必要なデータベース ソースとツールを指定します。コンテキスト エンジニアリング エージェントには、構成の生成に役立つエージェント スキルがプリインストールされています。
エージェント環境を起動します。
エージェントにデータベース接続の設定を依頼します(例: 「データベース接続の設定を手伝ってください」)。 エージェントの手順に沿って、現在の作業ディレクトリに
autoctx/tools.yamlとして構成ファイルを作成します。新しい
tools.yaml構成を適用するには、接続を再読み込みします。- Antigravity CLI で
/mcpを実行し、toolboxを選択して再起動します。 - Gemini CLI で
/mcp reloadを実行します。 - Claude Code で
/mcpを実行し、toolboxを選択してReconnectを選択します。
- Antigravity CLI で
データベース構成ファイルを手動で構成する方法の詳細については、 MCP ツールボックスの構成をご覧ください。
コンテキストを生成して最適化する
コンテキスト エンジニアリング エージェントは、コーディング エージェントのコンテキスト エンジニアリング機能を強化するための一連のエージェント スキルと MCP ツールを提供します。これらのツールを組み合わせて使用して、ベースラインを生成し、有効性を測定し、反復的に改善を適用できます。ただし、ワークフローのどの段階からでも開始できます。
- コンテキスト セットがすでにある場合は、評価に直接進むことができます。
- 修正するクエリが失敗している場合は、ギャップ分析に直接進むことができます。
各機能では、エージェントのアクション、ユースケース、呼び出しコマンドについて説明します。
プロンプトの例は、自然言語でエージェントにクエリを実行する方法を示しています。リクエストを完了するために追加の詳細が必要な場合は、エージェントから明確化を求められます。
評価データセットを構築して拡張する
パフォーマンスを改善するには、まずパフォーマンスを測定する必要があります。ユーザーの質問と想定される SQL で構成されるゴールデン データセットがないコンテキスト エンジニアリングでは、体系的な検証ができません。ゴールデン データセットを使用すると、すべての変更が測定可能な改善となり、グラウンド トゥルースに対して検証できます。
代表的なゴールデン データセットを手動で作成するには時間がかかり、小さなデータセットではユーザーの言い回しのバリエーションが見落とされる可能性があります。エージェントは次の方法でこれを解決します。
- データベース スキーマに基づいて候補となる質問と SQL のペアを生成する。
- フィルタのバリエーション、同義語、言い換えを使用して、小さなシード データセットを拡張する。
必要に応じて、生成された SQL をデータベースに対して実行するようにエージェントに指示できます。この検証により、クエリをデータセットに追加する前に、クエリが正常に実行されることを確認できます。
データセットは、質問と SQL のペアを含む JSON ファイルです。
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
承認されたペアは、ワークスペースの autoctx/golden.json
ファイルに入力され、評価の準備が整います。既存のファイルを提供することも、エージェントが展開する評価例をインラインで記述することもできます。
次のプロンプトの例を使用して、エージェントに指示できます。
- 「スキーマから評価データセットを生成してください。」
- 「シードの質問と SQL を示します。これをより広範なデータセットに展開し、クエリが実行されることを確認してください。」
ベースライン コンテキスト セットを生成する
コンテキストをゼロから作成するのではなく、エージェントにデータベース スキーマとアプリケーション アーティファクト(ビジネスルール、サンプルクエリ、README ファイルなど)から初期コンテキスト セットを派生させることができます。このベースライン コンテキストは最終的なものではありませんが、データベース モデルに基づいた検証済みの開始点を提供します。
次のプロンプトの例を使用して、エージェントに指示できます。
- 「スキーマからコンテキスト セットを生成してください。」
- 「これらのスキーマと
requirements.mdのビジネスルールを使用して、初期コンテキストを生成してください。」
エージェントは、生成されたアーティファクトを整理するテストの名前を指定するように求めます。データベース スキーマが大きい場合は、スコープを絞り込むように求められることがあります。Cloud SQL Studio を使用してコンテキストをアップロードするには、エージェントが JSON ファイルを生成した後の 手順に沿って操作します。
コンテキストの有効性を評価する
コンテキスト セットとゴールデン データセットを確立したら、各ゴールデン質問でデータ エージェントの QueryData API にクエリを実行して、コンテキストのパフォーマンスを測定できます。エージェントは、Evalbench を使用して、生成された SQL とその実行結果を想定される回答と比較します。
評価を実行すると、次のようになります。
- 合格と不合格の結果や集計スコアなどの定量的な指標を使用して、コンテキストの反復処理の進捗状況を追跡します。
- インラインの会話の概要と、テストフォルダの
eval_reports/ディレクトリに書き込まれた詳細な CSV レポート。
評価を開始するには、ゴールデン データセットのパスとコンテキスト セット ID を指定します。 コンテキスト セット ID を確認する方法については、エージェントのコンテキスト ID を確認するをご覧ください。
次のプロンプトの例を使用して、エージェントに指示できます。
- 「
golden.jsonに対してコンテキストを評価してください。」 - 「前回のテストの構成を使用して評価を再実行してください。」
以前に生成した評価構成を再設定せずに再実行するには、エージェントに依頼するか、CLI を直接呼び出します。
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
評価構成スキーマの詳細と評価実行をカスタマイズする方法については、 Evalbench のドキュメントをご覧ください。
ギャップ分析を実行して改善案を提案する
クエリの失敗を解決するには、根本原因(列の誤り、テーブル結合の欠落、未解決のあいまいな用語など)を特定する必要があります。これらの問題を特定するには、評価レポートを詳細に分析する必要があります。
エージェントは、この分析と修正のループを自動化します。
- ギャップ分析: エージェントは評価結果とコンテキスト セットを読み取り、同様の失敗をグループ化し、テンプレート、ファセット、値検索などのターゲット コンテキストの追加を推奨します。
- 提案された修正: エージェントは具体的な編集を提案し、必要に応じてデータベースに対して SQL をテストして解決策を検証します。
- ベースラインの保持: エージェントは、改善点をベースライン コンテキストとともに新しい JSON ファイルに書き込み、元のファイルを保持します。
次のプロンプトの例を使用して、エージェントに指示できます。
- 「前回の評価でギャップ分析を実行し、修正案を提案してください。」
- 「 _`
golden.json` に対してこのコンテキスト セットを最適化してください。_」
次の反復処理に備えて、Data Agents Studio を使用して改善されたコンテキストをターゲット コンテキスト セットにアップロードします。 手順に沿って操作してください。
必要に応じて特定のコンテキスト アイテムを作成する
特定の質問のテンプレート、繰り返されるフィルタのファセット、特定の列の値検索など、必要なコンテキストがすでにわかっている場合、コンテキスト JSON を手動で記述すると、パラメータ名、型メタデータ、フラグメント構文でシリアル化エラーが発生する可能性があります。エージェントは JSON のフォーマットを処理するため、ビジネスの意図に集中できます。
この機能は、新しいクエリ パターンをサポートする必要がある場合や、スキーマの詳細が欠落している場合など、アドホック アップデートにも使用できます。JSON を取得するには、評価を実行したり、テストを設定したりせずに、必要なコンテキストをエージェントに説明します。
これは、1 回限りのタスクを処理する場合にも適しています。たとえば、サポートが必要な新しい質問と SQL のペアが関係者から提供された場合や、コードレビュー中にファセットが欠落していることに気づいた場合などです。修正するためにテストを設定したり、評価を実行したりする必要はありません。必要なものを説明すると、エージェントが JSON を生成します。
次のプロンプトの例を使用して、エージェントに指示できます。
- 「'カリフォルニア州にある空港はどこですか?' のテンプレートを作成してください。SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'。」 - 「'red eye' というラベルのフィルタ
departure_time BETWEEN '00:00:00' AND '06:00:00'のファセットを作成してください。」 - 「
airports.iataの値検索を作成してください。」
コンテキスト タイプの選択について推論する
テンプレート、ファセット、値検索のいずれであっても、正しいコンテキスト タイプを選択すると、コンテキストの肥大化やデータベースのクエリの回帰を防ぐことができます。たとえば、ファセットの代わりにテンプレートを使用するとルールが重複する可能性があり、テンプレートで十分な場合に値検索を導入するとクエリのレイテンシが増加する可能性があります。正しいスキーマ形式を見つけるには、コンテキスト アイテムを作成する前に、クエリ構造またはデータベース列に基づいてタイプを推奨するようにエージェントに指示します。エージェントは、コンテキスト オプションを理解できるように、その推論を説明します。
次のプロンプトの例を使用して、エージェントに指示できます。
- 「多くのクエリでフィルタ
departure_time BETWEEN '00:00:00' AND '06:00:00'を記述しています。これをキャプチャする最適な方法は何ですか?」 - 「ユーザーはフライトのステータスをフリーテキストで説明します。これを
に一致させたいと考えています。」
flights.statusどのような値検索を設定すればよいですか?」 - 「テンプレートとファセットの違いは何ですか?また、それぞれをいつ 使用すればよいですか?」
コンテキスト セット全体に一括オペレーションを適用する
エージェントは、大規模なコンテキスト セットを一貫して管理するための一括更新をサポートしています。データベース列の名前が変更された場合、コード値の形式が変更された場合、テンプレートが非推奨のテーブルを参照している場合など、複数のコンテキスト アイテムを同時に更新する必要がある場合、エージェントは関連のないエントリを変更せずに、影響を受けるすべてのアイテムに変更を適用できます。
次のプロンプトの例を使用して、エージェントに指示できます。
- 「
golden.txtを読み取り、すべてのペアをテンプレートに変換してください。」 - 「
context_set.jsonで、airline = 'UA'をairline = 'United Airlines'「United」を参照するアイテムに置き換えてください。関連のないアイテムはそのままにしてください。」
次のステップ
- コンテキスト セットの詳細を確認する。
- Cloud SQL Studio でコンテキスト セットを作成または削除する方法を確認する。
- コンテキスト セットをテストする方法を確認する。