
באמצעות ה-API, ללא צורך בכתיבת קוד, אפשר ליצור ולאמן מודל מותאם אישית של תמלול דיבור לטקסט כדי לשפר את דיוק הזיהוי ממודל קיים של Cloud Speech-to-Text. השירות שמנוהל במלואו מקצה אוטומטית משאבי מחשוב, מריץ את קוד האפליקציה לאימון ומבטיח מחיקה של משאבי המחשוב אחרי משימת האימון. מקבלים מודל תמלול מכוונן במלואו שמתאים לכל אפליקציה במורד הזרם.
בדומה למודלים של למידת מכונה, אימון של מודל מותאם אישית של תמלול הוא בדרך כלל תהליך איטרטיבי שכולל בחירה של מודל בסיס כנקודת התחלה, כוונון עדין שלו באמצעות מערכי נתונים של טקסט ואודיו, ולאחר מכן בדיקה של איכות הזיהוי של המודל. אם התוצאות לא תואמות לציפיות שלכם, אתם יכולים לאמן מחדש מודל חדש עם שילוב שונה של נתונים, לבצע בדיקה נוספת או להשתמש בו ישירות לתמלול בדומיין שלכם.
לפני שמתחילים
מוודאים שנרשמתם לחשבון ב- Google Cloud , יצרתם פרויקט ב- Google Cloudוהפעלתם את Cloud Speech-to-Text API: עוברים אל Speech במסוףGoogle Cloud ומנווטים אל Cloud Speech-to-Text API. פועלים בקטע מודלים בהתאמה אישית בסרגל הניווט שמימין.
יצירת מודל בהתאמה אישית
מתחילים ביצירת מודל מותאם אישית של Speech-to-Text והגדרת הפרמטרים שלו, כמו מודל בסיסי ושפת תמלול:
- לוחצים על יצירה כדי ליצור מודל בהתאמה אישית.
- מזינים שם מודל, שיוצג ויופיע כהפניה בבקשות ה-API ובמסוף Speech. Google Cloud
- מזינים תיאור למודל.
- בוחרים מודל בסיס שמתאים לתרחיש לדוגמה שלכם.
- בוחרים את השפה של התמלול במודל.
- בוחרים את האזור שבו יתבצע האימון.
- לוחצים על Continue.
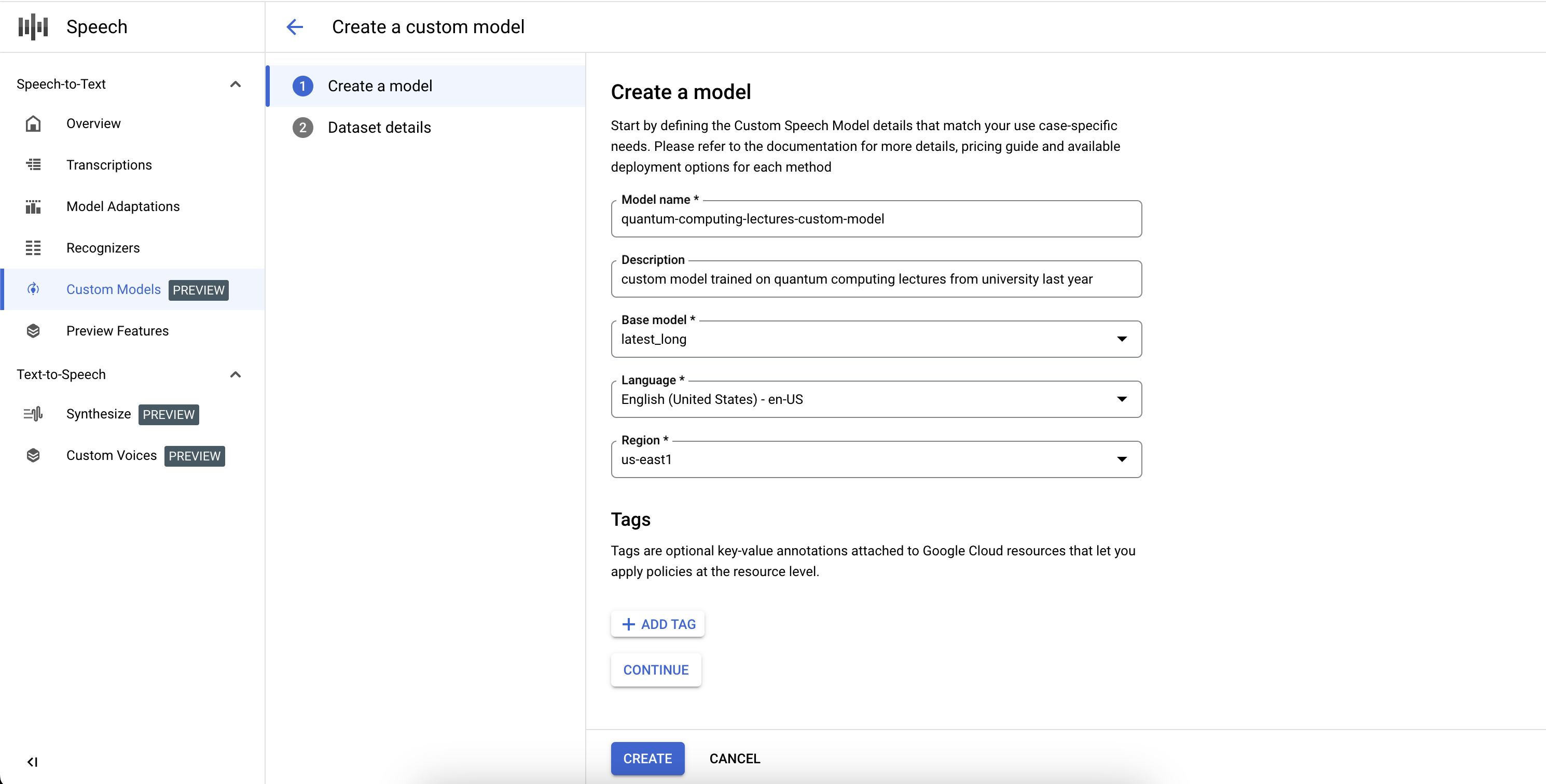
כדי להשלים את ההגדרה של מודל מותאם אישית של תמלול ולהתחיל את ההכשרה, צריך להגדיר את מערכי הנתונים של ההכשרה והאימות.
- בוחרים מערך נתונים לאימון על ידי הזנת URI תקין של ספרייה ב-Cloud Storage. מוודאים שיש רק קובצי אודיו וטקסט, ושאורך האודיו הכולל עומד בדרישות של מערך נתוני האימון.
- בוחרים מערך נתונים לאימות על ידי הזנת URI תקין של ספרייה ב-Cloud Storage. מוודאים שיש רק קובצי אודיו וטקסט, ומשך האודיו הכולל עומד בדרישות של ערכת האימות.
- לוחצים על יצירה כדי להתחיל בתהליך האימון.
- בוחרים מערך נתונים לאימות על ידי הזנת URI תקין של ספרייה ב-Cloud Storage. מוודאים שיש רק קובצי אודיו וטקסט, ומשך האודיו הכולל עומד בדרישות של ערכת האימות.
אם לא נוספו מספיק שעות אודיו לאינדקס או שהקבצים לא עומדים בהנחיות, תהליך האימון ייכשל.
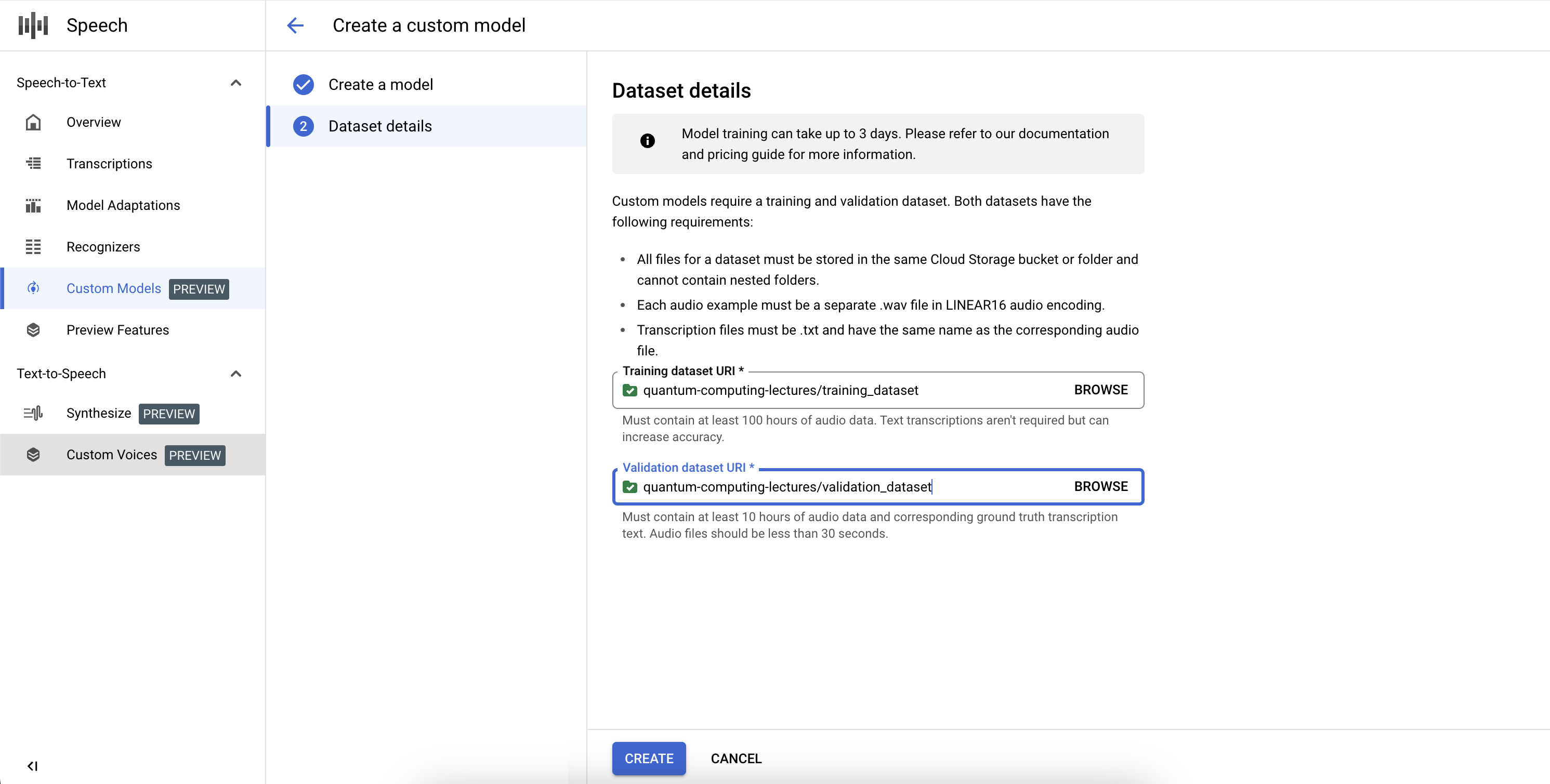
יכול להיות שעבודות אימון יתווספו לתור אחרי עבודות אחרות במערכת שלנו, והאימון של מודל יכול להימשך בין כמה שעות לכמה ימים, בהתאם לגודל של מערך הנתונים. אחרי אימון המודל, הסטטוס שלו יהיה פעיל.
מחיקה של מודל בהתאמה אישית
לפני שמתחילים, חשוב לוודא שאין תנועה שמנותבת למודל המותאם אישית שלכם להמרת דיבור לטקסט דרך נקודת קצה כלשהי, כי מחיקת המודל תגרום להפסקת הטיפול בכל הבקשות.
- עוברים לכרטיסייה Models (מודלים) בקטע Custom Models (מודלים בהתאמה אישית).
- לוחצים כדי להרחיב את האפשרויות ואז לוחצים על מחיקה. תוך כמה רגעים, מודל הדיבור לטקסט בהתאמה אישית יימחק, יחד עם כל נקודות הקצה שלו, ולא ישרת יותר תנועה.
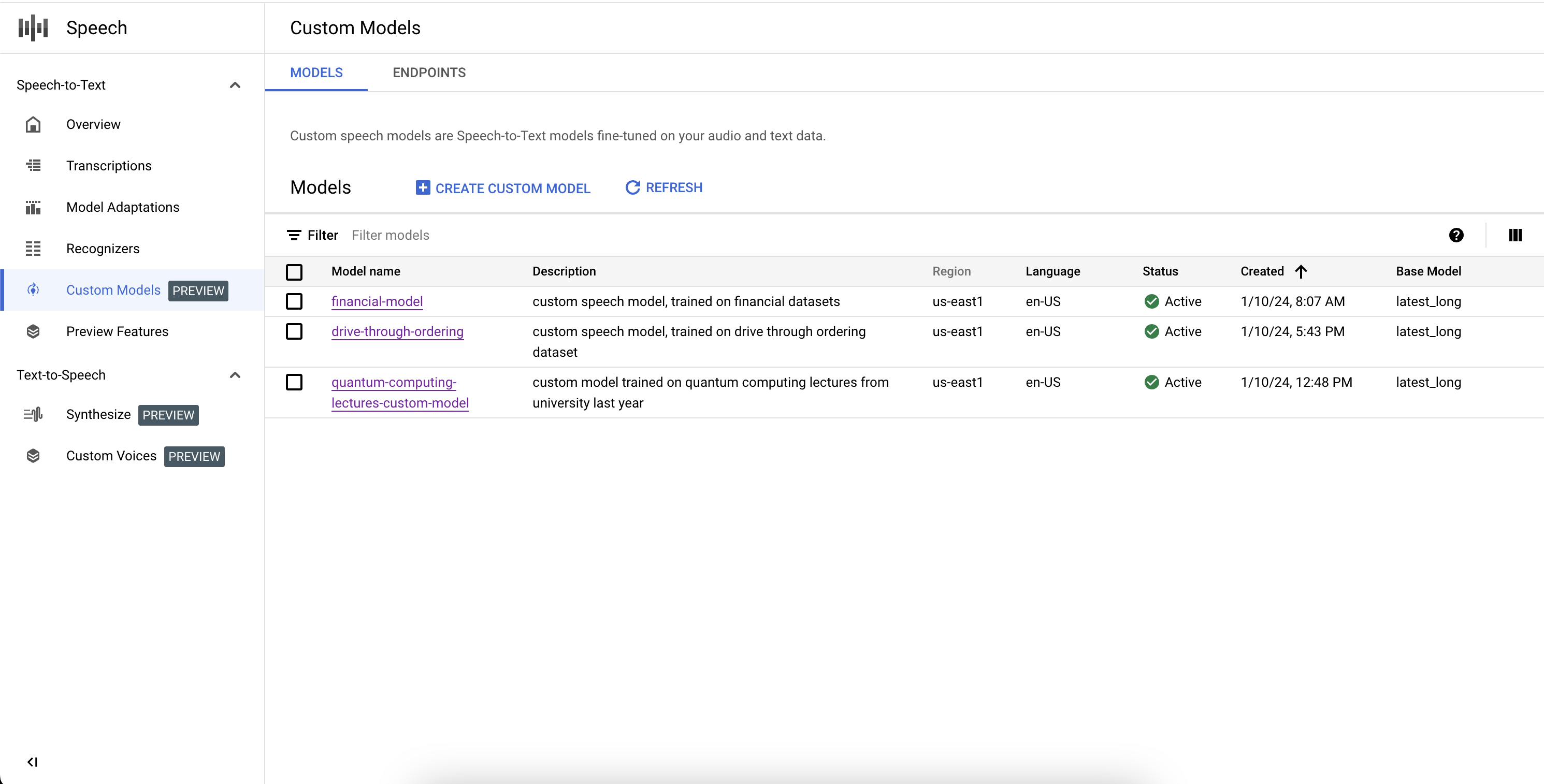
הצגת רשימה של מודלים בהתאמה אישית
בקטע מודלים בהתאמה אישית, אפשר ללחוץ על מודלים כדי לראות רשימה של כל המודלים המותאמים אישית של Speech-to-Text, כולל אלה שנמצאים בתהליך אימון, פעילים או בתהליך מחיקה.
המאמרים הבאים
כדי להשתמש במודלים מותאמים אישית של דיבור באפליקציה, אפשר להיעזר במקורות המידע הבאים: