
A pseudonimização é uma técnica de desidentificação que substitui os valores de dados confidenciais por tokens gerados criptograficamente. A pseudonimização é amplamente usada em setores como o financeiro e o de cuidados de saúde para ajudar a reduzir o risco de dados em utilização, restringir o âmbito da conformidade e minimizar a exposição de dados confidenciais a sistemas, preservando a utilidade e a precisão dos dados.
A proteção de dados confidenciais suporta três técnicas de pseudonimização de desidentificação e gera tokens aplicando um de três métodos de transformação criptográficos aos valores de dados confidenciais originais. Em seguida, cada valor confidencial original é substituído pelo respetivo token correspondente. Por vezes, a pseudonimização é designada tokenização ou substituição por substituto.
As técnicas de pseudonimização permitem tokens unidirecionais ou bidirecionais. Um token unidirecional foi transformado irreversivelmente, enquanto um token bidirecional pode ser revertido. Uma vez que o token é criado através da encriptação simétrica, a mesma chave criptográfica que pode gerar novos tokens também pode reverter tokens. Para situações em que não precisa de reversibilidade, pode usar tokens unidirecionais que usam mecanismos de hash seguros.
É útil compreender como a pseudonimização pode ajudar a proteger os dados confidenciais, ao mesmo tempo que permite que as operações empresariais e os fluxos de trabalho analíticos acedam facilmente aos dados de que precisam e os usem. Este tópico explora o conceito de pseudonimização e os três métodos criptográficos para transformar dados que o Sensitive Data Protection suporta.
Para ver instruções sobre como implementar estes métodos de pseudonimização e mais exemplos de utilização da proteção de dados confidenciais, consulte o artigo Remova a identificação de dados confidenciais.
Métodos criptográficos suportados na Proteção de dados confidenciais
A proteção de dados confidenciais suporta três técnicas de pseudonimização, todas as quais usam chaves criptográficas. Seguem-se os métodos disponíveis:
- Encriptação determinística com AES-SIV: um valor de entrada é substituído por um valor que foi encriptado através do algoritmo de encriptação AES-SIV com uma chave criptográfica, codificado com base64 e, em seguida, anteposto com uma anotação substituta, se especificado. Este método produz um valor com hash, pelo que não preserva o conjunto de carateres nem o comprimento do valor de entrada. Os valores encriptados com hash podem ser reidentificados através da chave criptográfica original e do valor de saída completo, incluindo a anotação substituta. Saiba mais sobre o formato dos valores tokenizados através da encriptação AES-SIV.
- Encriptação de preservação do formato: um valor de entrada é substituído por um valor que foi encriptado através do algoritmo de encriptação FPE-FFX com uma chave criptográfica e, em seguida, é adicionada uma anotação substituta, se especificado. Por predefinição, o conjunto de carateres e o comprimento do valor de entrada são preservados no valor de saída. Os valores encriptados podem ser reidentificados através da chave criptográfica original e do valor de saída completo, incluindo a anotação substituta. (Para algumas considerações importantes acerca da utilização deste método de encriptação, consulte a secção Encriptação de preservação do formato mais adiante neste tópico.)
- Aplicação de hash criptográfico: um valor de entrada é substituído por um valor que foi encriptado e com hash através do código de autenticação de mensagens baseado em hash (HMAC) – algoritmo hash seguro (SHA) – 256 no valor de entrada com uma chave criptográfica. A saída com hash da transformação tem sempre o mesmo comprimento e não pode ser reidentificada. Saiba mais sobre o formato dos valores tokenizados através da aplicação de hash criptográfico.
Estes métodos de pseudonimização estão resumidos na tabela seguinte. As linhas da tabela são explicadas após a tabela.
| Encriptação determinística com AES-SIV | Encriptação de preservação do formato | Aplicação de hash criptográfico | |
|---|---|---|---|
| Tipo de encriptação | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| Valores de entrada suportados | Pelo menos 1 carater; sem limitações de conjunto de carateres. | Tem de ter, pelo menos, 2 carateres e ser codificado como ASCII. | Tem de ser um valor de string ou um número inteiro. |
| Anotação substituta | Opcional. | Opcional. | N/A |
| Ajuste do contexto | Opcional. | Opcional. | N/A |
| Conjunto de carateres e comprimento preservados | ✗ | ✓ | ✗ |
| Reversível | ✓ | ✓ | ✗ |
| Integridade referencial | ✓ | ✓ | ✓ |
- Tipo de encriptação: o tipo de encriptação usado na transformação de desidentificação.
- Valores de entrada suportados: requisitos mínimos para valores de entrada.
- Anotação substituta: uma anotação especificada pelo utilizador que é adicionada antes dos valores encriptados para fornecer contexto aos utilizadores e informações para a proteção de dados confidenciais usar na reidentificação de um valor anonimizado. É necessária uma anotação substituta para a reidentificação de dados não estruturados. É opcional quando transforma uma coluna de dados estruturados ou tabulares com um
RecordTransformation. - Ajuste de contexto: uma referência a um campo de dados que "ajusta" o valor de entrada para que os valores de entrada idênticos possam ser desidentificados em valores de saída diferentes. O ajuste de contexto é opcional quando transforma uma coluna de dados estruturados ou tabulares com um
RecordTransformation. Para saber mais, consulte o artigo Usar ajustes de contexto. - Conjunto de carateres e comprimento preservados: se um valor desidentificado é composto pelo mesmo conjunto de carateres que o valor original e se o comprimento do valor desidentificado corresponde ao do valor original.
- Reversível: pode ser reidentificado através da chave criptográfica, da anotação substituta e de qualquer ajuste de contexto.
- Integridade referencial: a integridade referencial permite que os registos mantenham a respetiva relação entre si, mesmo depois de os dados terem sido anonimizados individualmente. Com a mesma chave criptográfica e ajuste de contexto, uma tabela de dados é substituída pela mesma forma ocultada sempre que é transformada, o que garante que as ligações entre valores (e, com dados estruturados, registos) são preservadas, mesmo entre tabelas.
Como funciona a tokenização na Proteção de dados confidenciais
O processo básico de tokenização é o mesmo para todos os três métodos suportados pela proteção de dados confidenciais.
Passo 1: a proteção de dados confidenciais seleciona os dados a tokenizar. A forma mais comum de o fazer é usar um infoType detetor integrado ou personalizado para fazer a correspondência com os valores de dados confidenciais desejados. Se estiver a analisar dados estruturados (como uma tabela do BigQuery), também pode realizar a tokenização em colunas inteiras de dados através de transformações de registos.
Para mais informações sobre as duas categorias de transformações (infoType e transformações de registos), consulte o artigo Transformações de desidentificação.
Passo 2: usando uma chave criptográfica, a Proteção de dados confidenciais encripta cada valor de entrada. Pode fornecer esta chave de uma de três formas:
- Ao envolvê-lo através do Cloud Key Management Service (Cloud KMS). (Para máxima segurança, o Cloud KMS é o método preferencial.)
- Através da utilização de uma chave transitória, que a proteção de dados confidenciais gera no momento da desidentificação e, em seguida, rejeita. Uma chave transitória só mantém a integridade por pedido da API. Se precisar de integridade ou planear reidentificar estes dados, não use este tipo de chave.
- Diretamente no formato de texto simples. (Não recomendado.)
Para mais detalhes, consulte a secção Usar chaves criptográficas mais adiante neste tópico.
Passo 3 (hash criptográfico e encriptação determinística apenas com AES-SIV): a proteção de dados confidenciais codifica o valor encriptado através de base64. Com a hash criptográfica, este valor codificado e encriptado é o token, e o processo continua com o passo 6. Com a encriptação determinística através do AES-SIV, este valor encriptado e codificado é o valor substituto, que é apenas um componente do token. O processo continua com o passo 4.
Passo 4 (preservação do formato e encriptação determinística apenas com AES-SIV):
a proteção de dados confidenciais adiciona uma anotação substituta opcional ao valor encriptado. A anotação de substituição ajuda a identificar valores de substituição encriptados ao
adicionar-lhes uma string descritiva que define. Por exemplo, sem uma anotação, pode não conseguir distinguir um número de telefone desidentificado de um número de identificação da segurança social ou outro número de identificação desidentificado. Além disso,
para voltar a identificar valores em dados não estruturados que foram desidentificados através
da encriptação de preservação do formato ou da encriptação determinística, tem de
especificar uma anotação substituta. (As anotações substitutas não são necessárias quando transforma uma coluna de dados estruturados ou tabulares com um RecordTransformation.)
Passo 5 (Preservação do formato e encriptação determinística com AES-SIV apenas de dados estruturados): a proteção de dados confidenciais pode usar contexto opcional de outro campo para "ajustar" o token gerado. Isto permite-lhe alterar o âmbito do token. Por exemplo, suponha que tem uma base de dados de dados de campanhas de marketing que inclui endereços de email e quer gerar tokens únicos para o mesmo endereço de email "ajustado" pelo ID da campanha. Isto permitiria que alguém associasse dados do mesmo utilizador na mesma campanha, mas não em campanhas diferentes. Se for usado um ajuste de contexto para criar o token, este ajuste de contexto também é necessário para que as transformações de desidentificação sejam revertidas. Encriptação determinística e de preservação do formato com suporte de AES-SIV contextos. Saiba como usar ajustes de contexto.
Passo 6: a proteção de dados confidenciais substitui o valor original pelo valor desidentificado.
Comparação de valores tokenizados
Esta secção demonstra o aspeto dos tokens típicos após a anonimização
através de cada um dos três métodos abordados neste tópico. O valor de dados confidenciais de exemplo é um número de telefone da América do Norte (1-206-555-0123).
Encriptação determinística com AES-SIV
Com a desidentificação através da encriptação determinística e do AES-SIV, é encriptado um valor de entrada (e, opcionalmente, qualquer ajuste de contexto especificado) com o AES-SIV com uma chave criptográfica, codificado com base64 e, em seguida, opcionalmente, é adicionada uma anotação substituta, se especificado. Este método não preserva o conjunto de carateres (ou "alfabeto") do valor de entrada. Para gerar resultados imprimíveis, o valor resultante é codificado em base64.
O token resultante, partindo do princípio de que foi especificado um infoType substituto, tem o seguinte formato:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
O diagrama anotado seguinte mostra um exemplo de token, o resultado de uma operação de desidentificação que usa a encriptação determinística com AES-SIV no valor 1-206-555-0123. O infoType substituto opcional foi definido como
NAM_PHONE_NUMB:

- Anotação substituta
- infoType substituto (definido pelo utilizador)
- Comprimento de carateres do valor transformado
- Valor substituto (transformado)
Se não especificar uma anotação substituta, o token resultante é igual ao valor transformado ou #4 no diagrama anotado. Para reidentificar dados não estruturados, é necessário este token completo, incluindo a anotação substituta. Quando transforma dados estruturados, como uma tabela, a anotação
substituta é opcional. A proteção de dados confidenciais pode realizar a
desidentificação e a reidentificação numa coluna inteira através de um
RecordTransformation
sem uma anotação substituta.
Encriptação com preservação do formato
Com a anulação da identificação através da encriptação de preservação do formato, um valor de entrada (e, opcionalmente, qualquer ajuste de contexto especificado) é encriptado através do modo FFX da encriptação de preservação do formato ("FPE-FFX") com uma chave criptográfica e, em seguida, opcionalmente, é adicionada uma anotação substituta, se especificado.
Ao contrário dos outros métodos de tokenização descritos neste tópico, o valor substituto de saída tem o mesmo comprimento que o valor de entrada e não é codificado através de base64. Define o conjunto de carateres, ou "alfabeto", de que o valor encriptado é composto. Existem três formas de especificar o alfabeto que a proteção de dados confidenciais deve usar no valor de saída:
- Use um de quatro valores enumerados que representam os quatro conjuntos de carateres/alfabetos mais comuns.
- Use um valor de base, que especifica o tamanho do alfabeto. A especificação do valor mínimo da base de
2resulta num alfabeto que consiste apenas em0e1. A especificação do valor radix máximo de95resulta num alfabeto que inclui todos os carateres numéricos, carateres alfabéticos em maiúsculas, carateres alfabéticos em minúsculas e carateres de símbolos. - Crie um alfabeto listando os carateres exatos a usar. Por exemplo, se especificar
1234567890-*, o resultado é um valor substituto composto apenas por números, hífenes e asteriscos.
A tabela seguinte apresenta quatro conjuntos de carateres comuns pelo valor enumerado de cada um (FfxCommonNativeAlphabet), valor radix e lista dos carateres do conjunto. A linha final apresenta o conjunto de carateres completo, que corresponde ao valor radix máximo.
| Nome do alfabeto/conjunto de carateres | Radix | Lista de caracteres |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
O token resultante, partindo do princípio de que foi especificado um infoType substituto, tem o seguinte formato:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
O diagrama anotado seguinte é o resultado de uma operação de desidentificação da proteção de dados confidenciais que usa a encriptação de preservação do formato no valor 1-206-555-0123 com uma base de 95. O infoType substituto opcional foi definido como NAM_PHONE_NUMB:
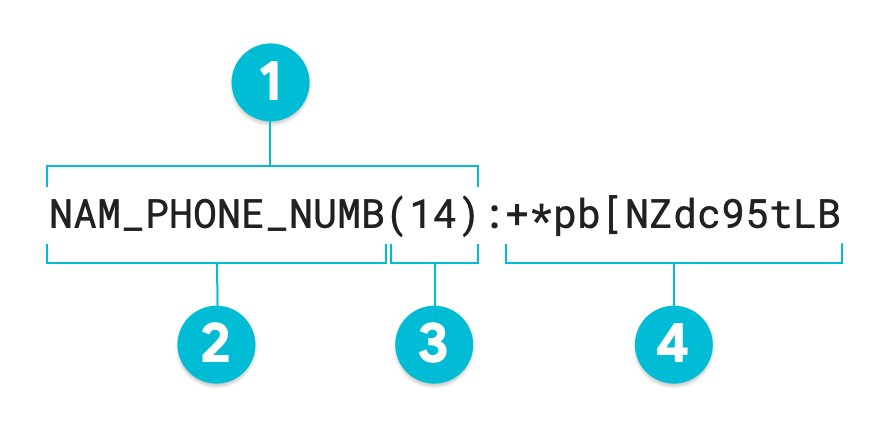
- Anotação substituta
- infoType substituto (definido pelo utilizador)
- Comprimento de carateres do valor transformado
- Valor substituto (transformado): o mesmo comprimento que o valor de entrada
Se não especificar uma anotação substituta, o token resultante é igual ao valor transformado ou #4 no diagrama anotado. Para reidentificar dados não estruturados, é necessário este token completo, incluindo a anotação substituta. Quando transforma dados estruturados, como uma tabela, a anotação
substituta é opcional. A proteção de dados sensíveis pode realizar a
desidentificação e a reidentificação numa coluna inteira através de um
RecordTransformation
sem um substituto.
Aplicação de hash criptográfico
Com a desidentificação através da aplicação de hash criptográfico, é aplicado hash a um valor de entrada com HMAC-SHA-256 com uma chave criptográfica e, em seguida, é codificado com base64. O valor anonimizado tem sempre um comprimento uniforme, consoante a dimensão da chave.
Ao contrário dos outros métodos de tokenização abordados neste tópico, a aplicação de hash criptográfico cria um token unidirecional. Ou seja, não é possível reverter a desidentificação através da aplicação de hash criptográfico.
Segue-se o resultado de uma operação de desidentificação que usa a aplicação de hash criptográfica no valor 1-206-555-0123. Esta saída é uma representação codificada em Base64 do valor com hash:
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
Usar chaves criptográficas
Existem três opções para chaves criptográficas que pode usar com os métodos de anonimização criptográfica na proteção de dados confidenciais:
Chave criptográfica envolvida do Cloud KMS: este é o tipo de chave criptográfica mais seguro disponível para utilização com os métodos de desidentificação da proteção de dados confidenciais. Uma chave envolvida do Cloud KMS consiste numa chave criptográfica de 128, 192 ou 256 bits que foi encriptada com outra chave. Fornece a primeira chave criptográfica, que é depois envolvida com uma chave criptográfica armazenada no Cloud Key Management Service. Estes tipos de chaves são armazenados no Cloud KMS para reidentificação posterior. Para mais informações sobre como criar e encapsular uma chave para fins de anonimização e reidentificação, consulte o Início rápido: anonimização e reidentificação de texto sensível.
Chave criptográfica transitória: uma chave criptográfica transitória é gerada pelo Sensitive Data Protection no momento da desidentificação e, em seguida, descartada. Por este motivo, não use uma chave criptográfica transitória com qualquer método de desidentificação criptográfica que queira reverter. As chaves criptográficas transitórias só mantêm a integridade por pedido de API. Se precisar de integridade em mais do que um pedido de API ou planear voltar a identificar os seus dados, não use este tipo de chave.
Chave criptográfica não processada: uma chave não processada é uma chave criptográfica de 128, 192 ou 256 bits codificada em base64 que fornece no pedido de desidentificação à API DLP. É responsável por manter este tipo de chaves criptográficas seguras para reidentificação posterior. Devido ao risco de divulgação acidental da chave, não recomendamos estes tipos de chaves. Estas chaves podem ser úteis para testes, mas, para cargas de trabalho de produção, recomenda-se uma chave criptográfica envolvida do Cloud KMS.
Para saber mais acerca das opções disponíveis quando usa chaves criptográficas, consulte o artigo
CryptoKey
na referência da API DLP.
Usar ajustes de contexto
Por predefinição, todos os métodos de transformação criptográfica de desidentificação têm integridade referencial, quer os tokens de saída sejam unidirecionais ou bidirecionais. Isto é, dada a mesma chave criptográfica, um valor de entrada é sempre transformado no mesmo valor encriptado. Em situações em que podem ocorrer dados repetitivos ou padrões de dados, o risco de reidentificação aumenta. Em alternativa, para que o mesmo valor de entrada seja sempre transformado num valor encriptado diferente, pode especificar um ajuste de contexto único.
Especifica um ajuste de contexto (denominado simplesmente a
context
na API DLP) quando transforma dados tabulares, uma vez que o ajuste é
efetivamente um ponteiro para uma coluna de dados, como um identificador.
A proteção de dados confidenciais usa o valor no campo especificado pelo ajuste de contexto ao encriptar o valor de entrada. Para garantir que o valor encriptado é sempre um valor único, especifique uma coluna para o ajuste que contenha identificadores únicos.
Considere este exemplo simples. A tabela seguinte mostra vários registos médicos, alguns dos quais incluem IDs de pacientes duplicados.
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| … | ... | … |
Se indicar à proteção de dados confidenciais que desidentifique os IDs dos pacientes na tabela, esta desidentifica os IDs dos pacientes repetidos para os mesmos valores por predefinição, conforme mostrado na tabela seguinte. Por exemplo, ambas as instâncias do ID do paciente "43789" são anonimizadas para "47222". (A coluna patient_id mostra os valores dos tokens após a pseudonimização com FPE-FFX e não inclui anotações substitutas. Consulte Encriptação de preservação do formato para mais informações.)
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| … | ... | … |
Isto significa que o âmbito da integridade referencial abrange todo o conjunto de dados.
Para restringir o âmbito de modo a evitar este comportamento, especifique um ajuste de contexto. Pode especificar qualquer coluna como um ajuste de contexto, mas para garantir que cada valor anónimo é único, especifique uma coluna para a qual cada valor seja único.
Suponhamos que quer ver se o mesmo paciente aparece por valor de icd10_codes, mas não se o mesmo paciente aparece em diferentes valores de icd10_codes. Para
o fazer, especifique a coluna icd10_codes como o ajuste de contexto.
Esta é a tabela após a desidentificação da coluna patient_id através da coluna icd10_codes como um ajuste de contexto:
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| … | ... | … |
Tenha em atenção que o quarto e o quinto valores patient_id anonimizados (29460) são iguais porque, além de os valores patient_id originais serem idênticos, os valores icd10_codes de ambas as linhas também eram idênticos. Uma vez que precisava de executar a análise com IDs de pacientes consistentes no âmbito do icd10_codes
valor, este comportamento é o que procura.
Para separar completamente a integridade referencial entre os valores patient_id e os valores icd10_codes, pode usar a coluna record_id como um ajuste de contexto:
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| … | ... | … |
Tenha em atenção que cada valor patient_id anonimizado na tabela é agora único.
Para saber como usar ajustes de contexto na API DLP, tenha em atenção a utilização de context nos seguintes tópicos de referência do método de transformação:
- Encriptação de preservação do formato:
CryptoReplaceFfxFpeConfig - Encriptação determinística com AES-SIV:
CryptoDeterministicConfig - Alteração de datas:
DateShiftConfig
O que se segue?
Trabalhe num exemplo completo que demonstra como criar uma chave envolvida, tokenizar conteúdo e reidentificar conteúdo tokenizado.
Consulte exemplos de código que demonstram como tokenizar dados confidenciais.
Saiba como desidentificar dados através da API DLP.