
Tipo
Manufacturing Data Engine (MDE) ti aiuta a trasformare una classe di messaggi di origine in record di un tipo specifico tramite l'analisi.
I tipi sono entità di configurazione che rappresentano il target dell'operazione di analisi e descrivono un insieme di record strutturalmente e semanticamente simili con un livello di granularità comune che, facoltativamente, condividono un contesto di metadati specifico.
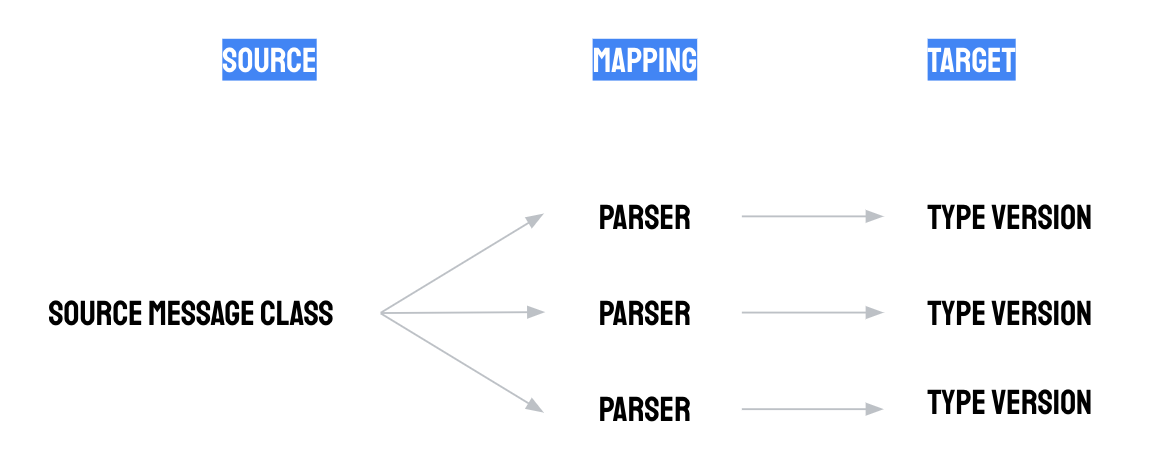
Ad esempio, puoi creare i tipi "stato macchina" e "letture del sensore di vibrazioni". Il primo tipo potrebbe essere utilizzato per modellare eventi di modifica dello stato della macchina, ad esempio "In esecuzione", "Inattivo", "Manutenzione pianificata" e "Manutenzione non pianificata", mentre il secondo potrebbe essere utilizzato per modellare un flusso di letture numeriche del sensore di vibrazione.
MDE viene fornito con un insieme di tipi predefiniti, ma puoi crearne di nuovi. I tipi sono definiti dalle seguenti caratteristiche:
- Nome: il nome del tipo.
- Archetipo: il nome dell'archetipo su cui si basa un tipo. Un tipo in MDE è sempre associato a un solo archetipo.
- Specifiche di archiviazione: un elenco di impostazioni per ogni data sink. Le specifiche di archiviazione consentono di configurare se i record vengono scritti in un sink di dati e di fornire ulteriori impostazioni specifiche per il sink.
- Parametri di configurazione facoltativi, tra cui:
- Lo schema JSON del campo data (applicabile solo ai tipi di archetipi discreti e continui).
- Associazioni di bucket di metadati: un elenco di bucket di metadati per i quali i record del tipo devono fornire riferimenti all'istanza.
Tipi e data sink
Il flusso di record di un determinato tipo viene elaborato dai sink di dati abilitati per un tipo. I sink di dati possono essere attivati (abilitati o disabilitati) per i tipi. Ad esempio, i record di un tipo possono essere configurati per essere scritti in BigQuery, ma non in Cloud Storage.
Data sink supportati
MDE supporta i seguenti sink di dati:
- BigQuery
- API Bigtable/Federation
- Cloud Storage
- Pub/Sub (JSON e Protobuf)
Data sink BigQuery
Quando viene creato un nuovo tipo, MDE crea automaticamente una
tabella dei tipi corrispondente in BigQuery nel set di dati mde_data.
I record di ogni tipo vengono scritti nella tabella del tipo corrispondente.
Sink dati Cloud Storage
I record vengono archiviati in un bucket Cloud Storage denominato
<project_id>-gcs-ingestion in file AVRO utilizzando il partizionamento Hive con una finestra di 10
minuti e 10 partizioni per finestra. I record sono raggruppati in cartelle per
tipo.
Sink dati Pub/Sub
Il sink Pub/Sub pubblica i record in un argomento dedicato. Lo schema dei messaggi Pub/Sub è descritto nello schema dei messaggi del sink Pub/Sub.
Materializzazione dei metadati
Ogni data sink di un tipo può essere configurato per materializzare i metadati nei
record. Se questa impostazione è abilitata, i riferimenti alle istanze dei metadati vengono risolti in
oggetti istanza dei metadati e gli oggetti vengono inclusi nei record. Il modo
preciso in cui i metadati vengono archiviati o restituiti dipende dal sink dei dati.
In BigQuery, ad esempio, i metadati materializzati vengono scritti in materialized_metadata_field con lo schema seguente:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"additionalProperties": {
"type": "object",
"description": "Metadata instance"
}
}
Archetipi
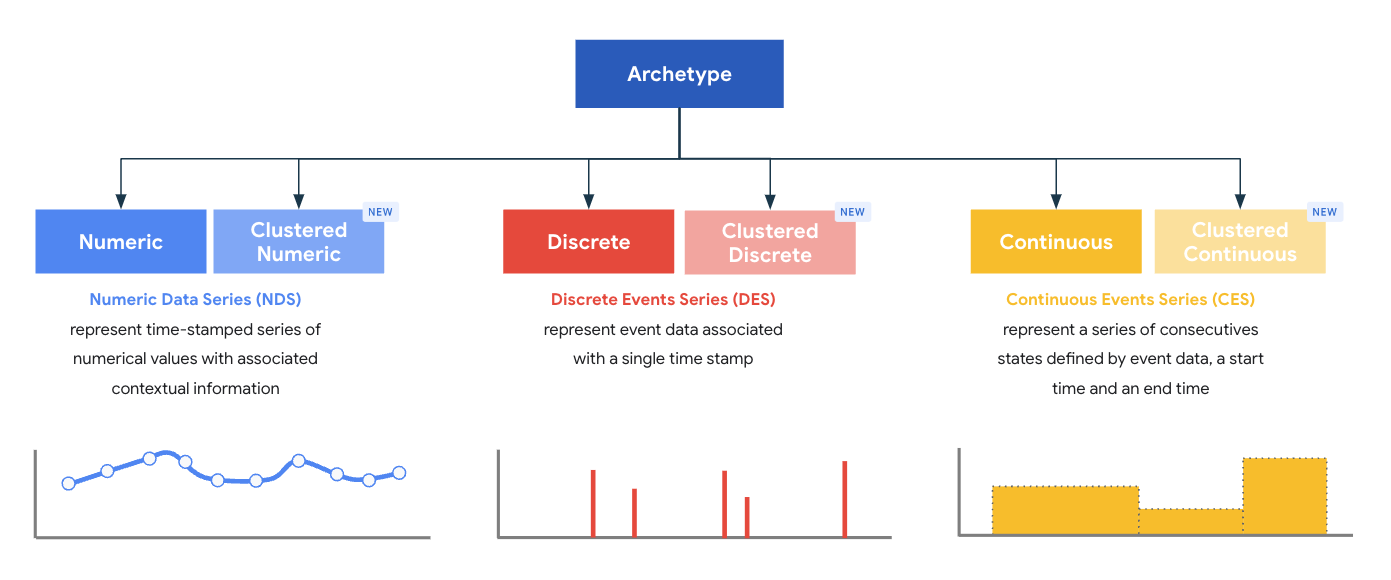
Gli archetipi rappresentano una superclasse di tipi e ogni archetipo è progettato per fornire un modello ottimale di elaborazione e archiviazione per i record. Gli archetipi definiscono i campi obbligatori principali che devono essere presenti in un record di un determinato tipo emesso da un parser. MDE viene fornito con un insieme di sei archetipi standard e cluster definiti dal sistema raggruppati in tre famiglie di archetipi:
- Serie di dati numerici (NDS)
- Serie di dati discreti (DDS)
- Serie di dati continua (CDS)
Un tipo in MDE è sempre associato a un solo archetipo e l'archetipo di un tipo viene definito al momento della creazione.
Puoi utilizzare i tipi per definire ulteriori vincoli sui record proto emessi
dai parser oltre a quelli imposti dagli archetipi. Ad esempio, puoi specificare la
forma del campo data per un tipo oppure puoi definire che i record di un tipo
devono essere contestualizzati da metadati specifici.
In sintesi, lo schema del record proto è una combinazione di:
- Schema dell'archetipo
- Schema del tipo
Famiglie di archetipi
Ogni famiglia di archetipi contiene due tipi di archetipi:
- Standard
- Raggruppato in cluster
MDE v1.3 introduce il concetto di archetipi cluster, che estendono la funzionalità degli archetipi standard. Gli archetipi raggruppati forniscono quattro campi generici che possono essere compilati con valori nel parser. Ogni data sink utilizza questi quattro campi per fornire funzionalità aggiuntive di query e accesso ai dati:
- BigQuery: le tabelle di tipo cluster in BigQuery sono raggruppate in cluster in base ai quattro campi generici in ordine. In questo modo puoi filtrare i dati in BigQuery in modo efficiente nei campi in cluster.
- API Bigtable Federation: l'API Federation utilizzava i campi clusterizzati per costruire le chiavi di riga in Bigtable, consentendo nuovi pattern di accesso ai dati.
- Pub/Sub: i campi vengono passati come campi di primo livello nel messaggio Pub/Sub.
Famiglia di archetipi numerici
La famiglia di archetipi numerici è progettata per fungere da base per i tipi che modellano una serie di messaggi numerici con timestamp, ad esempio un sensore di temperatura che emette un flusso di letture.
Le versioni standard e cluster dell'archetipo definiscono i seguenti schemi di record di base:
Standard
| Campo | Tipo di dati | Obbligatorio |
|---|---|---|
tagName |
Stringa | Sì |
value |
Numerico | Sì |
eventTimestamp |
Numero intero (formattato come ms epoca) | Sì |
Raggruppato in cluster
| Campo | Tipo di dati | Obbligatorio |
|---|---|---|
tagName |
Stringa | Sì |
value |
Numerico | Sì |
eventTimestamp |
Numero intero (formattato come ms epoca) | Sì |
clustered_column_1 |
Stringa | No |
clustered_column_2 |
Stringa | No |
clustered_column_3 |
Stringa | No |
clustered_column_4 |
Stringa | No |
Famiglia di archetipi discreti
La famiglia di archetipi discreti è progettata per fungere da base per i tipi che modellano eventi con timestamp, ad esempio una modifica dei parametri guidata dall'operatore in una macchina o un processo specifico.
Le versioni standard e cluster dell'archetipo definiscono i seguenti schemi di record di base:
Standard
| Campo | Tipo di dati | Obbligatorio |
|---|---|---|
tagName |
Stringa | Sì |
data |
Oggetto JSON | Sì |
eventTimestamp |
Numero intero (formattato come ms epoca) | Sì |
Raggruppato in cluster
| Campo | Tipo di dati | Obbligatorio |
|---|---|---|
tagName |
Stringa | Sì |
data |
Oggetto JSON | Sì |
eventTimestamp |
Numero intero (formattato come ms epoca) | Sì |
clustered_column_1 |
Stringa | No |
clustered_column_2 |
Stringa | No |
clustered_column_3 |
Stringa | No |
clustered_column_4 |
Stringa | No |
Famiglia di archetipi continua
La famiglia di archetipi continui è progettata per fungere da base per i tipi che modellano serie di stati consecutivi definiti da un timestamp di inizio e fine, ad esempio lo stato operativo di una macchina per un periodo di tempo continuo.
Le versioni standard e cluster dell'archetipo definiscono i seguenti schemi di record di base:
Standard
| Campo | Tipo di dati | Obbligatorio |
|---|---|---|
tagName |
Stringa | Sì |
data |
Oggetto JSON | Sì |
eventTimestampStart |
Numero intero (formattato come ms epoch) | Sì |
eventTimestampEnd |
Numero intero (formattato come ms epoch) | Sì |
Raggruppato in cluster
| Campo | Tipo di dati | Obbligatorio |
|---|---|---|
tagName |
Stringa | Sì |
data |
Oggetto JSON | Sì |
eventTimestampStart |
Numero intero (formattato come ms epoch) | Sì |
eventTimestampEnd |
Numero intero (formattato come ms epoch) | Sì |
clustered_column_1 |
Stringa | No |
clustered_column_2 |
Stringa | No |
clustered_column_3 |
Stringa | No |
clustered_column_4 |
Stringa | No |
Campo dati
Gli archetipi serie di dati discreti e serie di dati continui accettano uno schema JSON
per il campo data. Se è definito uno schema JSON per il campo, il valore del campo data contenuto in un record emesso da un parser viene convalidato in base allo schema in fase di runtime. Ad esempio, immagina di definire lo schema seguente per un tipo di serie temporale discreta:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"eventName": {
"type": "string"
}
},
"required": ["eventName"]
}
Con lo schema precedente per un tipo di serie temporale discreta, il seguente record (parziale) di questo tipo emesso da un parser non è valido:
{
"data": {
"complex": {
"machineName": "example"
}
}
}
Se la convalida dei dati non va a buon fine, i record vengono spostati nella coda dei messaggi non recapitabili. I record nella coda dei messaggi non recapitabili possono essere elaborati manualmente in un secondo momento.
Bucket di metadati
I tipi possono fare riferimento ai bucket di metadati. Un riferimento al bucket di metadati in un tipo
definisce se i record possono o devono (a seconda del valore dell'attributo required)
fornire un riferimento a un'istanza del bucket di metadati.
I riferimenti ai bucket di metadati in un tipo definiscono il contratto dei metadati per i record di quel tipo. Ad esempio, puoi definire che tutti i record di un tipo devono essere contestualizzati con i metadati del dispositivo (fornisci un riferimento a un'istanza di metadati in un bucket di metadati chiamato device).
Se un bucket di metadati è associato a un tipo e il flag required è impostato su
true, i record di quel tipo emessi da un parser che non forniscono un riferimento
a un'istanza del bucket di metadati vengono spostati nella coda dei messaggi non recapitabili. Per
maggiori informazioni, consulta
Come rielaborare i messaggi.
Controllo delle versioni dei tipi
Esistono diversi tipi di controllo delle versioni e le sezioni seguenti descrivono ciascuno di questi.
Creazione di una nuova versione del tipo
Puoi creare nuove versioni per un tipo specifico. Ogni nuova versione può specificare associazioni di bucket di metadati aggiuntivi o modificare lo schema del campo dati. Tuttavia, per garantire la coerenza dei dati durante il ciclo di vita di un tipo, le nuove versioni del tipo possono solo evolvere in avanti e devono rispettare le regole di controllo delle versioni. Le nuove versioni di un tipo possono apportare le seguenti modifiche:
Maggio:
- Aggiungi nuovi campi facoltativi allo schema dei dati.
- Contrassegnare un campo obbligatorio come facoltativo per lo schema dei dati.
- Aggiungi nuovi riferimenti ai bucket di metadati.
Non è consentito:
- Rimuovi i campi dallo schema dei dati.
- Modifica il tipo di dati dei campi esistenti nello schema dei dati.
- Contrassegna un attributo facoltativo come obbligatorio nello schema dei dati.
- Rimuovi i riferimenti al bucket dei metadati.
Modifica della versione del tipo esistente
Le specifiche e le trasformazioni di archiviazione possono essere aggiornate in una versione del tipo esistente senza dover creare una nuova versione del tipo.
Modifica del tipo
La maggior parte delle operazioni sui tipi richiede la creazione di una nuova versione del tipo o la modifica di una versione del tipo esistente. L'unica operazione che può essere eseguita sul tipo indipendentemente dalla sua versione è l'attivazione o la disattivazione. Quando un tipo viene disattivato, tutte le versioni di quel tipo smettono di accettare dati.
Limitazioni di denominazione per i tipi
Un nome di tipo può contenere:
- Lettere (maiuscole e minuscole), numeri e i caratteri speciali
-e_. - Può contenere fino a 255 caratteri.
Puoi utilizzare la seguente espressione regolare per la convalida: ^[a-z][a-z0-9\\-_]{1,255}$.
Se tenti di creare un'entità che viola le limitazioni di denominazione, riceverai un 400 error.