
Parser
I parser sono entità di configurazione che definiscono in che modo i messaggi di una specifica classe di messaggi di origine vengono analizzati e trasformati in record di un tipo target specifico.
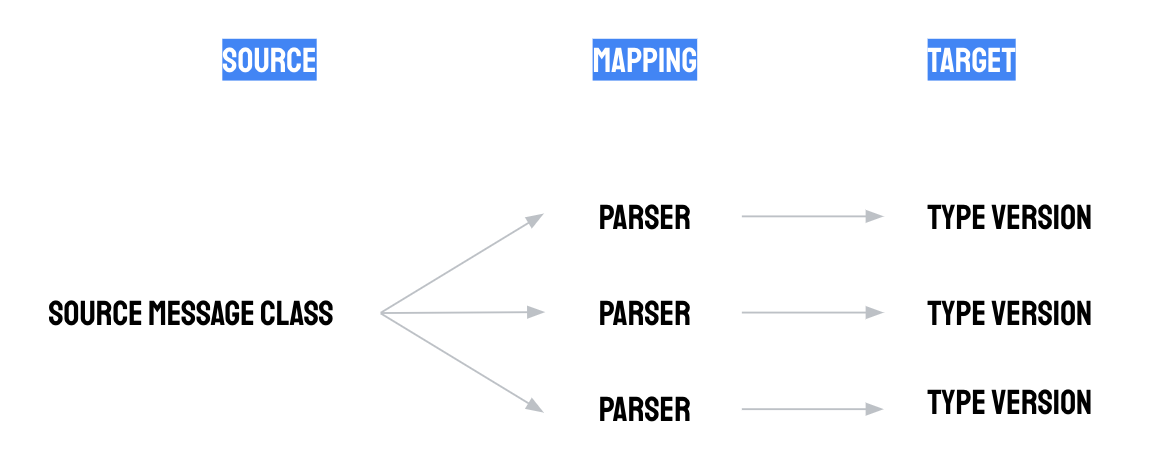
Una configurazione del parser è costituita dai seguenti tre componenti:
- Associazione della classe di messaggi di origine: un parser elabora i messaggi di origine da una singola classe di messaggi di origine. Per saperne di più, consulta Classi di messaggi di origine.
- Associazione di versioni di tipo: un parser genera record proto di una singola versione di tipo. La configurazione della versione del tipo definisce i campi che devono essere presenti nel record proto emesso e ne determina la struttura (schema). Per saperne di più, consulta Tipo.
- Script Whistle: gli script Whistle definiscono come trasformare i messaggi di origine in record proto utilizzando la logica di mapping, analisi e trasformazione. Gli script Whistle sono scritti dagli utenti. Tuttavia, Manufacturing Data Engine (MDE) fornisce pacchetti di configurazione per i casi d'uso tipici. Per saperne di più, consulta la sezione seguente.
Definizione di fischio
Whistle è un linguaggio di mappatura che può essere utilizzato per convertire dati nidificati complessi da uno schema a un altro. Nel settore manifatturiero, i modelli di dati possono essere complessi e possono contenere molte strutture annidate e ripetute. Ciò rende difficile esprimere la logica di mappatura in un formato procedurale. Whistle risolve questo problema fornendo un linguaggio dichiarativo che consente di definire la logica di mappatura e trasformazione in modo naturale.
Ad esempio, potresti utilizzare Whistle per armonizzare diversi modelli di dati dei sensori in diverse fabbriche in un modello di tipo MDE unificato. I dati di origine potrebbero contenere strutture nidificate, ad esempio un elenco di componenti o una gerarchia di funzionalità. Whistle ti consente di esprimere la logica di mappatura per queste strutture nidificate in modo naturale, senza dover scrivere codice procedurale.
Whistle supporta anche funzioni che consentono di suddividere mappature complesse che coinvolgono strutture ripetute in funzioni. In questo modo è più facile comprendere e gestire il codice di mappatura, nonché riutilizzarlo.
Whistle offre vantaggi rispetto agli approcci procedurali. Vedi il seguente esempio:
Dato questo payload di esempio:
{
"payload": {
"tag": "vibration-sensor"
},
"details": {
"value": 0.24,
"timestamp": "2023-06-26 12:19:20.046000 UTC"
}
}
E il seguente script di Whistle:
package mde
[{
tagName: $root.payload.tag
timestamps: {
eventTimestamp: $root.details.timestamp
}
data: {
numeric: $root.details.value
}
}]
Applicando lo script Whistle precedente, il parser produrrebbe un record proto simile al seguente:
[
{
"tagName": "vibration-sensor",
"timestamps": {
"eventTimestamp": "2023-06-26 12:19:20.046000 UTC"
},
"data": {
"value": 0.24
}
}
]
Per ulteriori informazioni sulla sintassi del linguaggio Whistle e sulle funzioni disponibili, consulta la documentazione di Whistle.
Comportamento di runtime dei parser
In fase di runtime, il parser riceve tutti i messaggi della classe di messaggi di origine a cui è associato, applica lo script Whistle configurato a ogni messaggio ed emette uno o più record proto del tipo configurato.
I record proto emessi devono essere conformi alla configurazione del tipo. In caso contrario, vengono spostati nella coda dei messaggi non recapitabili.
Regole di associazione
Un parser può essere associato a una sola classe di messaggi e a una sola versione del tipo. Tuttavia, un parser può emettere uno o più record purché siano del tipo di versione a cui è collegato. L'output di un parser è un array di oggetti record proto.
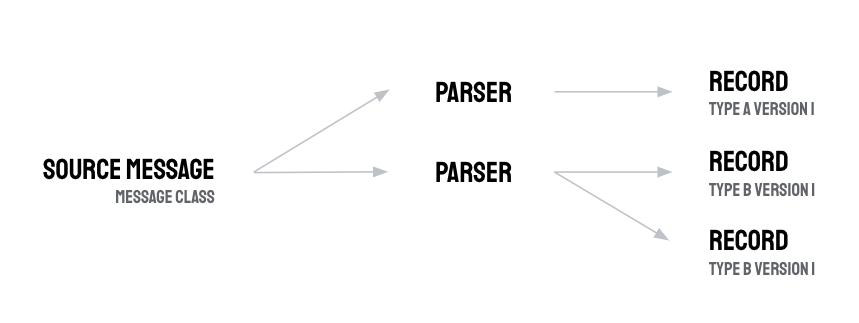
L'emissione di più record da un parser è utile negli scenari in cui un messaggio di origine contiene un array di letture o eventi che vuoi disaggregare. I parser consentono di "dividere" il messaggio di origine in più record proto in modo che ogni lettura, ad esempio, diventi una riga in una tabella di record in BigQuery.
I record proto emessi possono fare riferimento a qualsiasi nome tag. Questo comportamento è una modifica rispetto alle versioni 1.1 e 1.2, in cui i nomi dei tag erano limitati al tipo. Dopo la versione 1.3 i record proto MDE emessi da qualsiasi parser possono
Schema del record Proto
Lo schema JSON a cui devono conformarsi i record proto dipende da:
- Archetipo: l'archetipo specifico associato al tipo.
- Type Configuration (Configurazione tipo): le impostazioni di configurazione definite per il tipo.
L'archetipo definisce lo schema di base per i record. Ad esempio, un tipo nella famiglia di archetipi discrete richiede che i record proto contengano valori per i seguenti attributi:
tagNametimestamps.eventTimestampdata.complex
Il tipo può imporre ulteriori limitazioni ai record proto. Ad esempio, puoi definire uno schema per il campo data oppure puoi richiedere che i record proto forniscano un riferimento a un'istanza di metadati.
Per saperne di più, consulta il riferimento al record proto.
Ricerca dei dati di riferimento
MDE fornisce una funzione Whistle personalizzata per cercare un valore per una chiave fornita da un bucket di ricerca.
Puoi cercare un'istanza di bucket di ricerca in base alla sua chiave naturale chiamando la funzione mde::lookupByKey in uno script Whistle. La funzione accetta come argomenti la ricercabucketName,
bucketVersion e naturalKey dell'istanza e restituisce
l'ultima istanza di metadati per la chiave naturale fornita. Puoi utilizzare l'istanza per compilare i campi in un record proto nel parser. Ad esempio:
"data" : {
"complex" : {
"VIN" : mde::lookupByKey("vin-lookup-bucket", input.vinKey, 1).VIN,
"vin_registration_time" : mde::lookupByKey("vin-lookup-bucket", input.vinKey, 1).vin_registration_time,
"ResultValue" : 163.0482614,
}
}
Limitazioni di denominazione per i parser
Il nome di un parser può contenere:
- Lettere (maiuscole e minuscole), numeri e i caratteri speciali
-e_. - Può contenere fino a 255 caratteri.
Puoi utilizzare la seguente espressione regolare per la convalida: ^[a-z][a-z0-9\\-_]{1,255}$.
Se tenti di creare un'entità che viola le limitazioni di denominazione, riceverai
un 400 error.
Puoi utilizzare la funzione mde::sanitizeTagName() per assicurarti che il nome sia conforme alle limitazioni di denominazione. Per saperne di più, consulta Funzioni MDE di Whistle.