
パーサー
パーサーは、特定のソース メッセージ クラスからのメッセージを特定のターゲット タイプのレコードに解析して変換する方法を定義する構成エンティティです。
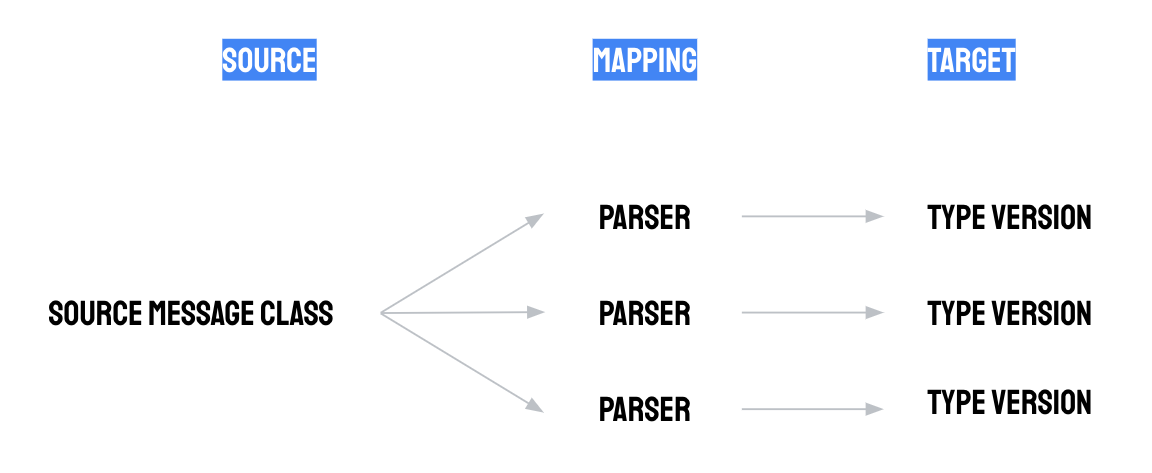
パーサー構成には、次の 3 つのコンポーネントがあります。
- ソース メッセージ クラスの関連付け: パーサーは、単一のソース メッセージ クラスのソース メッセージを処理します。詳細については、ソース メッセージ クラスをご覧ください。
- 型バージョンの関連付け: パーサーは、単一の型バージョンの proto レコードを出力します。タイプ バージョン構成は、出力される proto レコードに存在する必要があるフィールドを定義し、その構造(スキーマ)を決定します。詳細については、タイプをご覧ください。
- Whistle スクリプト: Whistle スクリプトは、マッピング、解析、変換ロジックを使用してソース メッセージを proto レコードに変換する方法を定義します。Whistle スクリプトはユーザーが作成しますが、Manufacturing Data Engine(MDE)には一般的なユースケース用の構成パッケージが用意されています。詳細については、次のセクションをご覧ください。
Whistle の定義
Whistle は、複雑なネストされたデータをスキーマから別のスキーマに変換するために使用できるマッピング言語です。製造業では、データモデルが複雑になり、ネストされた構造や繰り返される構造が多数含まれることがあります。そのため、マッピング ロジックをプロシージャル形式で表現することが困難になります。Whistle は、マッピングと変換ロジックを自然な方法で定義できる宣言型言語を提供することで、この問題に対処します。
たとえば、Whistle を使用して、さまざまな工場にわたる複数のセンサー データモデルを統合された MDE タイプモデルに調和させることができます。ソースデータには、コンポーネントのリストや機能の階層などのネストされた構造が含まれている場合があります。Whistle を使用すると、手続き型コードを記述することなく、これらのネストされた構造のマッピング ロジックを自然な方法で表現できます。
Whistle は、繰り返し構造を含む複雑なマッピングを関数に分割できる関数もサポートしています。これにより、マッピング コードの理解と保守が容易になり、コードの再利用も容易になります。
Whistle には、手続き型アプローチよりもメリットがあります。次の例をご覧ください。
次のサンプル ペイロードを想定します。
{
"payload": {
"tag": "vibration-sensor"
},
"details": {
"value": 0.24,
"timestamp": "2023-06-26 12:19:20.046000 UTC"
}
}
次の Whistle スクリプト:
package mde
[{
tagName: $root.payload.tag
timestamps: {
eventTimestamp: $root.details.timestamp
}
data: {
numeric: $root.details.value
}
}]
上記の Whistle スクリプトを適用すると、パーサーは次のような proto レコードを生成します。
[
{
"tagName": "vibration-sensor",
"timestamps": {
"eventTimestamp": "2023-06-26 12:19:20.046000 UTC"
},
"data": {
"value": 0.24
}
}
]
Whistle 言語の構文と使用可能な関数の詳細については、Whistle のドキュメントをご覧ください。
パーサーのランタイム動作
実行時に、パーサーは関連付けられているソース メッセージ クラスのすべてのメッセージを受信し、構成された Whistle スクリプトを各メッセージに適用して、構成されたタイプの 1 つ以上の proto レコードを出力します。
出力される proto レコードは、型構成に準拠している必要があります。準拠していない場合、デッドレター キューに移動されます。
関連付けルール
パーサーは、1 つのメッセージ クラスと 1 つのタイプ バージョンにのみ関連付けることができます。ただし、パーサーがリンクされているバージョン型のレコードであれば、1 つ以上のレコードを出力できます。パーサーの出力は、proto レコード オブジェクトの配列です。
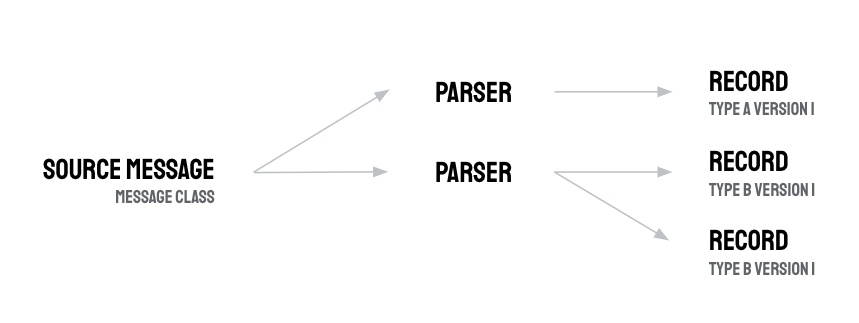
パーサーから複数のレコードを出力することは、ソース メッセージに、逆集計する読み取りまたはイベントの配列が含まれているシナリオで役立ちます。パーサーを使用すると、ソース メッセージを複数の proto レコードに分割して、各読み取り値(たとえば)が BigQuery のレコード テーブルの行になるようにできます。
出力された proto レコードは、任意のタグ名を参照できます。この動作は、タグ名が型にスコープされていた v1.1 および v1.2 からの変更です。v1.3 以降、パーサーによって出力された MDE proto レコードは、
Proto レコード スキーマ
proto レコードが準拠する必要がある JSON スキーマは、次のものによって異なります。
- アーキタイプ: タイプに関連付けられている特定のアーキタイプ。
- Type Configuration: タイプに定義された構成設定。
アーキタイプは、レコードの基本スキーマを定義します。たとえば、discrete アーキタイプ ファミリーの型では、proto レコードに次の属性の値が含まれている必要があります。
tagNametimestamps.eventTimestampdata.complex
このタイプによって、proto レコードにさらに制限が課される可能性があります。たとえば、data フィールドのスキーマを定義したり、proto レコードがメタデータ インスタンスへの参照を提供することを要求したりできます。
詳細については、proto レコード リファレンスをご覧ください。
参照データのルックアップ
MDE は、カスタムの Whistle 関数を提供して、指定されたキーの値をルックアップ バケットから検索します。
Whistle スクリプトで mde::lookupByKey 関数を呼び出すことで、自然キーでルックアップ バケット インスタンスを検索できます。この関数は、インスタンスの lookupbucketName、bucketVersion、naturalKey を引数として受け取り、指定された自然キーの最新のメタデータ インスタンスを返します。このインスタンスを使用して、パーサーの proto レコードのフィールドにデータを入力できます。次に例を示します。
"data" : {
"complex" : {
"VIN" : mde::lookupByKey("vin-lookup-bucket", input.vinKey, 1).VIN,
"vin_registration_time" : mde::lookupByKey("vin-lookup-bucket", input.vinKey, 1).vin_registration_time,
"ResultValue" : 163.0482614,
}
}
パーサーの命名に関する制限事項
パーサー名には次のものを含めることができます。
- 英字(大文字と小文字)、数字、特殊文字
-と_。 - 255 文字以内で指定できます。
検証には、次の正規表現を使用できます。^[a-z][a-z0-9\\-_]{1,255}$
命名制限に違反するエンティティを作成しようとすると、400 error が返されます。
mde::sanitizeTagName() 関数を使用すると、名前が命名制限に準拠していることを確認できます。詳細については、Whistle MDE 関数をご覧ください。