
タイプ
Manufacturing Data Engine(MDE)は、解析によって、ソース メッセージのクラスを特定のタイプのレコードに変換します。
タイプは、解析オペレーションのターゲットを表す構成エンティティです。また、共通の粒度レベルを持つ構造的および意味的に類似したレコードのセットを記述します。このレコードは、特定のメタデータ コンテキストを共有することもできます。
たとえば、「マシン状態」や「振動センサーの読み取り値」などのタイプを作成できます。最初のタイプは、マシン状態の変更イベント(「実行中」、「アイドル」、「スケジュールされたメンテナンス」、「スケジュールされていないメンテナンス」など)のモデル化に使用できます。2 番目のタイプは、数値振動センサーの読み取り値のストリームのモデル化に使用できます。
MDE にはデフォルトの型が用意されていますが、新しい型を作成することもできます。型は次の特性で定義されます。
- 名前: 型の名前。
- アーキタイプ: 型のベースとなるアーキタイプの名前。MDE の型は常に 1 つのアーキタイプにのみ関連付けられます。
- ストレージ仕様: データシンクごとの設定のリスト。ストレージ仕様では、レコードをデータシンクに書き込むかどうかを構成し、シンク固有の設定をさらに指定できます。
- 省略可能な構成パラメータ(以下を含む)。
- data フィールドの JSON スキーマ(離散アーキタイプと連続アーキタイプの型にのみ適用されます)。
- メタデータ バケットの関連付け: このタイプのレコードがインスタンス参照を提供する必要があるメタデータ バケットのリスト。
タイプとデータシンク
特定の型のレコードのストリームは、その型に対して有効になっているデータシンクによって処理されます。データシンクは、タイプごとに有効(有効または無効)にできます。たとえば、あるタイプのレコードを BigQuery に書き込むように構成できますが、Cloud Storage には書き込まないように構成できます。
サポートされているデータシンク
MDE は、次のデータシンクをサポートしています。
- BigQuery
- Bigtable/Federation API
- Cloud Storage
- Pub/Sub(JSON と Protobuf)
BigQuery データシンク
新しいタイプが作成されると、MDE は mde_data データセットの BigQuery に対応するタイプテーブルを自動的に作成します。各タイプのレコードは、対応するタイプテーブルに書き込まれます。
Cloud Storage データシンク
レコードは、10 分間のウィンドウとウィンドウあたり 10 個のパーティションを使用して Hive パーティショニングを使用する AVRO ファイルの <project_id>-gcs-ingestion という名前の Cloud Storage バケットに保存されます。レコードはタイプごとにフォルダにグループ化されます。
Pub/Sub データシンク
Pub/Sub シンクは、専用のトピックにレコードをパブリッシュします。Pub/Sub メッセージ スキーマについては、Pub/Sub シンク メッセージ スキーマをご覧ください。
メタデータの具体化
型の各データシンクは、レコード内のメタデータを具体化するように構成できます。この設定が有効になっている場合、メタデータ インスタンス参照はメタデータ インスタンス オブジェクトに解決され、オブジェクトはレコードに含まれます。メタデータの永続化または出力の正確な方法は、データシンクによって異なります。たとえば、BigQuery では、マテリアライズされたメタデータは次のスキーマで materialized_metadata_field に書き込まれます。
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"additionalProperties": {
"type": "object",
"description": "Metadata instance"
}
}
アーキタイプ
アーキタイプは型のスーパークラスを表し、各アーキタイプはレコードに最適な処理モデルとストレージ モデルを提供するように設計されています。アーキタイプは、パーサーによって出力される特定のタイプのレコードに存在する必要があるコアの必須フィールドを定義します。MDE には、3 つのアーキタイプ ファミリーにグループ化された、システム定義の標準アーキタイプとクラスタ アーキタイプが 6 つ用意されています。
- 数値データ系列(NDS)
- 離散データ系列(DDS)
- 連続データ系列(CDS)
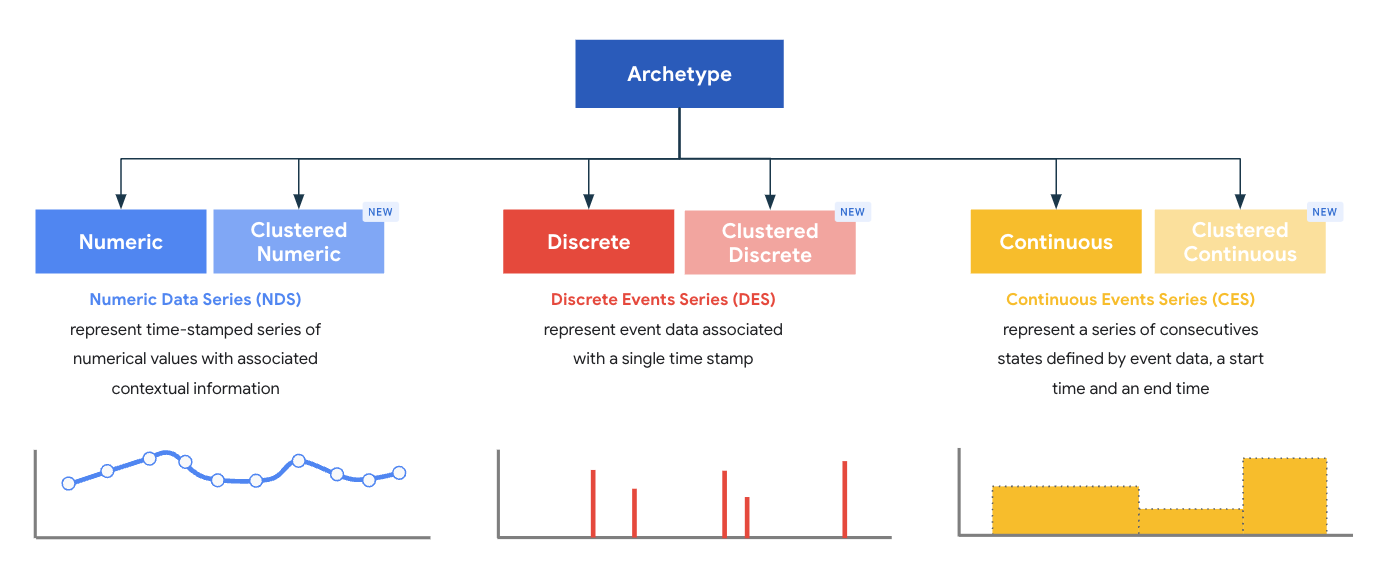
MDE の型は常に 1 つのアーキタイプに関連付けられ、型のアーキタイプは作成時に定義されます。
型を使用すると、アーキタイプによって課される制約を超えて、パーサーによって出力される proto レコードに制約を定義できます。たとえば、型の data フィールドの形状を指定したり、型のレコードを特定のメタデータでコンテキスト化する必要があることを定義したりできます。
要約すると、proto レコード スキーマは次の要素の組み合わせです。
- アーキタイプ スキーマ
- 型スキーマ
アーキタイプ ファミリー
各アーキタイプ ファミリーには、次の 2 種類のアーキタイプが含まれています。
- 標準
- クラスタリング後
MDE v1.3 では、標準アーキタイプの機能を拡張するクラスタ化されたアーキタイプのコンセプトが導入されています。クラスタ化されたアーキタイプには、パーサーの値で入力できる 4 つの汎用フィールドが用意されています。各データシンクは、次の 4 つのフィールドを使用して、クエリとデータアクセスの追加機能を提供します。
- BigQuery: BigQuery のクラスタ化テーブルは、4 つの汎用フィールドで順にクラスタ化されます。これにより、クラスタ化されたフィールドで BigQuery のデータを効率的にフィルタできます。
- Bigtable Federation API: Federation API は、クラスタ化されたフィールドを使用して Bigtable の行キーを構築し、新しいデータアクセス パターンを可能にしました。
- Pub/Sub: Pub/Sub メッセージは、Pub/Sub メッセージの最上位フィールドとしてフィールドを渡します。
数値アーキタイプ ファミリー
数値アーキタイプ ファミリーは、タイムスタンプ付きの数値メッセージのシーケンスをモデル化する型のベースとして機能するように設計されています。たとえば、温度センサーが読み取り値のストリームを送信する場合などです。
アーキタイプの標準バージョンとクラスタ バージョンでは、次のベースレコード スキーマが定義されています。
標準
| フィールド | データ型 | 必須 |
|---|---|---|
tagName |
文字列 | ○ |
value |
数値 | ○ |
eventTimestamp |
整数(エポック ms としてフォーマット) | ○ |
クラスタリング後
| フィールド | データ型 | 必須 |
|---|---|---|
tagName |
文字列 | ○ |
value |
数値 | ○ |
eventTimestamp |
整数(エポック ms としてフォーマット) | ○ |
clustered_column_1 |
文字列 | × |
clustered_column_2 |
文字列 | × |
clustered_column_3 |
文字列 | × |
clustered_column_4 |
文字列 | × |
Discrete アーキタイプ ファミリー
個別のアーキタイプ ファミリーは、タイムスタンプ付きイベントをモデル化するタイプ(特定のマシンまたはプロセスでのオペレーター主導のパラメータ変更など)のベースとして機能するように設計されています。
アーキタイプの標準バージョンとクラスタ バージョンでは、次のベースレコード スキーマが定義されています。
標準
| フィールド | データ型 | 必須 |
|---|---|---|
tagName |
文字列 | ○ |
data |
JSON オブジェクト | ○ |
eventTimestamp |
整数(エポック ms としてフォーマット) | ○ |
クラスタリング後
| フィールド | データ型 | 必須 |
|---|---|---|
tagName |
文字列 | ○ |
data |
JSON オブジェクト | ○ |
eventTimestamp |
整数(エポック ms としてフォーマット) | ○ |
clustered_column_1 |
文字列 | × |
clustered_column_2 |
文字列 | × |
clustered_column_3 |
文字列 | × |
clustered_column_4 |
文字列 | × |
連続アーキタイプ ファミリー
連続アーキタイプ ファミリーは、開始タイムスタンプと終了タイムスタンプで定義された連続した状態のシリーズをモデル化するタイプのベースとして機能するように設計されています。たとえば、一定期間のマシンの動作状態などです。
アーキタイプの標準バージョンとクラスタ バージョンでは、次のベースレコード スキーマが定義されています。
標準
| フィールド | データ型 | 必須 |
|---|---|---|
tagName |
文字列 | ○ |
data |
JSON オブジェクト | ○ |
eventTimestampStart |
整数(エポック ms としてフォーマット) | ○ |
eventTimestampEnd |
整数(エポック ms としてフォーマット) | ○ |
クラスタリング後
| フィールド | データ型 | 必須 |
|---|---|---|
tagName |
文字列 | ○ |
data |
JSON オブジェクト | ○ |
eventTimestampStart |
整数(エポック ms としてフォーマット) | ○ |
eventTimestampEnd |
整数(エポック ms としてフォーマット) | ○ |
clustered_column_1 |
文字列 | × |
clustered_column_2 |
文字列 | × |
clustered_column_3 |
文字列 | × |
clustered_column_4 |
文字列 | × |
データ フィールド
離散データ系列と連続データ系列のアーキタイプは、data フィールドの JSON スキーマを受け入れます。フィールドの JSON スキーマが定義されている場合、パーサーによって出力されたレコードに含まれる data フィールドの値は、実行時にスキーマに対して検証されます。たとえば、離散時系列型に次のスキーマを定義するとします。
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"eventName": {
"type": "string"
}
},
"required": ["eventName"]
}
離散時系列タイプの以前のスキーマでは、パーサーによって出力された次の(部分的な)レコードは無効です。
{
"data": {
"complex": {
"machineName": "example"
}
}
}
データ検証が失敗すると、レコードはデッドレター キューに移動されます。デッドレター キュー内のレコードは、後で手動で処理できます。
メタデータ バケット
型はメタデータ バケットを参照できます。型に対するメタデータ バケット参照は、レコードがメタデータ バケット インスタンスへの参照を提供できるか、提供する必要があるか(required 属性の値によって異なる)を定義します。
型に対するメタデータ バケット参照は、その型のレコードのメタデータ コントラクトを定義します。たとえば、あるタイプのすべてのレコードをデバイス メタデータでコンテキスト化する必要があることを定義できます(デバイスというメタデータ バケット内のメタデータ インスタンスへの参照を指定します)。
メタデータ バケットが型に関連付けられており、required フラグが true に設定されている場合、メタデータ バケット インスタンスへの参照を提供しないパーサーによって出力されたその型のレコードは、デッドレター キューに移動されます。詳細については、メッセージを再処理する方法をご覧ください。
型のバージョニング
バージョン管理にはさまざまなタイプがあり、以降のセクションでそれぞれについて説明します。
新しいタイプのバージョンの作成
特定のタイプの新しいバージョンを作成できます。新しいバージョンごとに、追加のメタデータ バケットの関連付けを指定したり、データフィールドのスキーマを変更したりできます。ただし、タイプのライフサイクル全体でデータの整合性を確保するため、新しいタイプのバージョンは前方のみに進化でき、バージョニング ルールを遵守する必要があります。タイプの新しいバージョンでは、次の変更を行うことができます。
5 月:
- データスキーマに新しいオプション フィールドを追加します。
- データスキーマの必須フィールドをオプションとしてマークします。
- 新しいメタデータ バケット参照を追加します。
禁止事項:
- データ スキーマからフィールドを削除します。
- データ スキーマ内の既存のフィールドのデータ型を変更します。
- データスキーマでオプションの属性を必須としてマークします。
- メタデータ バケット参照を削除します。
既存のタイプのバージョンを編集する
新しい型バージョンを作成しなくても、既存の型バージョンでストレージ仕様と変換を更新できます。
タイプの編集
型に対するほとんどのオペレーションでは、新しい型バージョンの作成または既存の型バージョンの編集が必要です。バージョンの種類に関係なく実行できる唯一のオペレーションは、有効化または無効化です。タイプが無効になると、そのタイプのすべてのバージョンでデータの受け入れが停止します。
型の命名に関する制限事項
型名には次のものを含めることができます。
- 英字(大文字と小文字)、数字、特殊文字
-と_。 - 255 文字以内で指定できます。
検証には、次の正規表現を使用できます。^[a-z][a-z0-9\\-_]{1,255}$。
命名制限に違反するエンティティを作成しようとすると、400 error が返されます。