
Die Schemaregistrierung bietet Repositories mit Schemas, die von mehreren Anwendungen gemeinsam genutzt werden. Bisher waren Teams ohne Schemaregister möglicherweise auf informelle Vereinbarungen angewiesen, um das Nachrichtenformat und die Serialisierung und Deserialisierung von Nachrichten zu definieren. Dazu gehörten beispielsweise mündliche Absprachen, freigegebene Dokumente, die nicht programmatisch erzwungen wurden, oder Wiki-Seiten. Die Schemaregistrierung sorgt für eine einheitliche Codierung und Decodierung von Nachrichten.
In diesem Dokument erhalten Sie einen Überblick über die Schema-Registry-Funktion für Managed Service for Apache Kafka, ihre Komponenten und den grundlegenden Workflow.
Schemas verstehen
Stellen Sie sich vor, Sie entwickeln eine Anwendung, mit der Kundenbestellungen nachverfolgt werden. Sie können beispielsweise ein Kafka-Thema namens customer_orders verwenden, um Nachrichten mit Informationen zu jeder Bestellung zu übertragen. Eine typische Bestellnachricht kann die folgenden Felder enthalten:
Bestell-ID
Kundenname
Produktname
Menge
Preis
Damit diese Nachrichten einheitlich strukturiert sind, können Sie ein Schema definieren. Hier ein Beispiel im Apache Avro-Format:
{
"type": "record",
"name": "Order",
"namespace": "com.example",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "customerName", "type": "string"},
{"name": "productName", "type": "string"},
{"name": "quantity", "type": "int"},
{"name": "price", "type": "double"}
]
}
Hier ist dasselbe Beispiel im Protocol Buffer-Format.
syntax = "proto3";
package com.example;
option java_multiple_files = true; // Optional: Recommended for Java users
option java_package = "com.example"; // Optional: Explicit Java package
message Order {
string orderId = 1;
string customerName = 2;
string productName = 3;
int32 quantity = 4; // Avro int maps to Protobuf int32
double price = 5;
}
Dieses Schema ist ein Bauplan für eine Nachricht. Sie besagt, dass eine order-Nachricht fünf Felder hat: eine Bestell-ID, einen Kundennamen, einen Produktnamen, eine Menge und einen Preis. Außerdem wird der Datentyp jedes Felds angegeben.
Wenn ein Consumer-Client eine binäre Nachricht empfängt, die mit diesem Schema codiert ist, muss er genau wissen, wie er sie interpretieren muss. Dazu speichert der Producer das order-Schema in einer Schema-Registry und übergibt eine Kennung des Schemas zusammen mit der Nachricht. Solange ein Empfänger der Nachricht weiß, welche Registry verwendet wurde, kann er dasselbe Schema abrufen und die Nachricht decodieren.
Angenommen, Sie möchten Ihren order-Nachrichten das Feld orderDate hinzufügen. Sie erstellen eine neue Version des order-Schemas und registrieren es unter demselben Betreff. So können Sie die Entwicklung Ihres Schemas im Zeitverlauf nachvollziehen.
Das Hinzufügen eines Felds ist eine vorwärtskompatible Änderung. Das bedeutet, dass Verbraucher, die ältere Schemaversionen (ohne orderDate) verwenden, weiterhin Nachrichten lesen und verarbeiten können, die mit dem neuen Schema erstellt wurden. Das neue Feld wird ignoriert.
Abwärtskompatibilität für die Schemaregistrierung bedeutet, dass eine Consumer-Anwendung, die mit einer neuen Schemaversion konfiguriert ist, Daten lesen kann, die mit einem vorherigen Schema erstellt wurden.
In diesem Beispiel wäre das ursprüngliche order-Schema Version 1. Wenn Sie das Feld orderDate hinzufügen, erstellen Sie Version 2 des order-Schemas. Beide Versionen werden unter demselben Thema gespeichert. So können Sie Schema-Updates verwalten, ohne bestehende Anwendungen zu beeinträchtigen, die möglicherweise noch auf Version 1 basieren.
Hier sehen Sie eine Übersicht über eine Beispiel-Schemaregistrierung namens schema_registry_test, die nach Kontext, Thema und Schemaversion organisiert ist:
customer_supportcontextorderBetreffV1-Version (mit orderId, customerName, productName, quantity, price)V2-Version (fügt orderDate zu V1 hinzu)
Was ist ein Schema?
Apache Kafka-Nachrichten bestehen aus Byte-Strings. Ohne eine definierte Struktur müssen Consumer-Anwendungen direkt mit Producer-Anwendungen zusammenarbeiten, um zu verstehen, wie diese Bytes interpretiert werden.
Ein Schema enthält eine formale Beschreibung der Daten in einer Nachricht. Es definiert die Felder und ihre Datentypen wie String, Ganzzahl oder boolescher Wert sowie alle verschachtelten Strukturen.
Managed Service for Apache Kafka unterstützt Schemas in den folgenden Formaten:
Protocol Buffers (Protobuf)
Die Schema Registry API unterstützt kein JSON.
Mit der in Managed Service for Apache Kafka integrierten Schema-Registry können Sie diese Schemata mit Ihren Kafka-Clients erstellen, verwalten und verwenden. Die Schemaregistrierung implementiert die Confluent Schema Registry REST API, die mit vorhandenen Apache Kafka-Anwendungen und gängigen Clientbibliotheken kompatibel ist.
Organisation der Schema-Registry
In der Schema-Registry werden Schemas in einer hierarchischen Struktur organisiert.
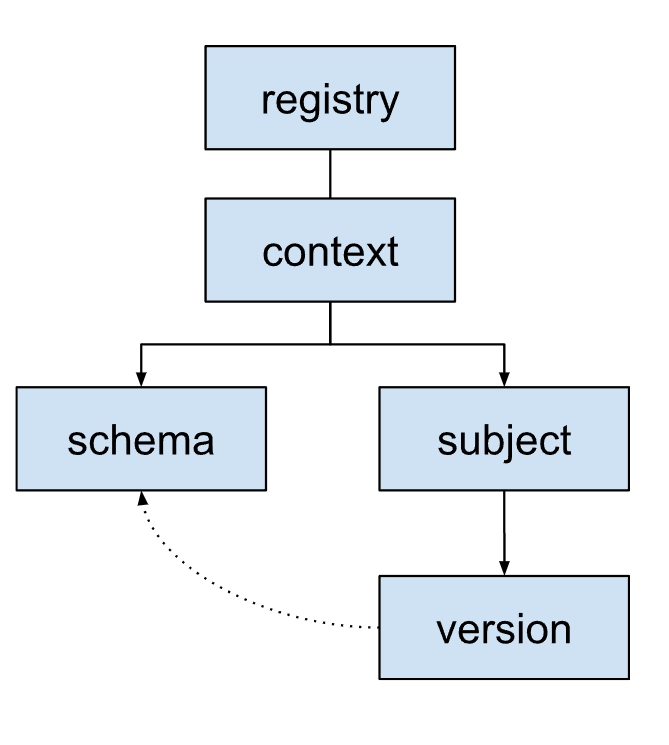
Schema:Die Struktur und die Datentypen einer Nachricht. Jedes Schema wird durch eine Schema-ID identifiziert. Diese ID wird von Anwendungen verwendet, um das Schema abzurufen.
Thema:Ein logischer Container für verschiedene Versionen eines Schemas. Mit Subjekten wird mithilfe von Kompatibilitätsregeln verwaltet, wie sich Schemas im Laufe der Zeit entwickeln. Jedes Subjekt entspricht in der Regel einem Kafka-Thema oder einem Datensatzobjekt.
Version:Wenn für die Geschäftslogik Änderungen an einer Nachrichtenstruktur erforderlich sind, erstellen und registrieren Sie eine neue Schemaversion für das entsprechende Thema.
Jede Version verweist auf ein bestimmtes Schema. Versionen verschiedener Themen können auf dasselbe Schema verweisen, wenn das zugrunde liegende Schema identisch ist.
Kontext:Eine übergeordnete Gruppierung oder ein Namespace für Themen. Kontexte ermöglichen es verschiedenen Teams oder Anwendungen, denselben Betreffnamen ohne Konflikte innerhalb derselben Schemaregistrierung zu verwenden.
Eine Schemaregistrierung kann mehrere Kontexte haben. Er enthält immer einen Standardkontext, der als
.gekennzeichnet ist. Dort werden Schemas und Themen platziert, wenn keine andere Kontext-ID angegeben ist.Ein Kontext kann mehrere Themen enthalten.
Registry:Der Container der obersten Ebene für das gesamte Schema-Ökosystem. Darin werden alle Schemas, Themen, Versionen und Kontexte gespeichert und verwaltet.
Workflow für die Schema-Registry
Wenn Sie den in diesem Abschnitt beschriebenen Workflow ausprobieren möchten, können Sie die Kurzanleitung Avro-Nachrichten mit der Schemaregistrierung erstellen verwenden.
Serialisierungsprogramme und Deserialisierungsprogramme in Ihren Kafka-Clients interagieren mit der Schemaregistrierung, um sicherzustellen, dass Nachrichten einem definierten Schema entsprechen. Hier ist ein typischer Workflow für eine Schema-Registry in Managed Service for Apache Kafka:
Initialisieren Sie Ihre Producer-Anwendung mit einem bestimmten Schema, das als Avro-generierte Klasse angegeben ist, und konfigurieren Sie sie so, dass eine bestimmte Schemaregistrierungs- und Serialisierungsbibliothek verwendet wird.
Konfigurieren Sie einen Consumer-Client so, dass er eine entsprechende Deserialisierungsbibliothek und dieselbe Schemaregistrierung verwendet.
Zur Laufzeit übergibt der Client das Nachrichtenobjekt an die Methode
producer.send. Die Kafka-Clientbibliothek verwendet den konfigurierten Serializer, um diesen Datensatz in die Avro-codierten Byte zu konvertieren.Der Serializer bestimmt einen Betreffnamen für das Schema basierend auf einer konfigurierten Betreffnamensstrategie in der Clientbibliothek. Anschließend wird dieser Betreffname in einer Anfrage an die Schemaregistrierung verwendet, um die ID des Schemas abzurufen. Weitere Informationen finden Sie unter Strategien zur Benennung von Themen.
Wenn das Schema in der Registrierung unter diesem Betreffnamen nicht vorhanden ist, kann der Client so konfiguriert werden, dass das Schema registriert wird. In diesem Fall erhält er die neu zugewiesene ID.
Vermeiden Sie diese Konfiguration in Produktionsumgebungen.
Der Producer sendet die serialisierte Nachricht mit der Schema-ID an das entsprechende Thema eines Kafka-Brokers.
Der Kafka-Broker speichert die Byte-Array-Darstellung Ihrer Nachricht in einem Thema.
Die Consumer-Anwendung empfängt die Nachricht.
Der Deserializer ruft das Schema mit dieser ID aus der Schemaregistrierung ab.
Der Deserializer parst die Nachricht für die Consumer-Anwendung.
Beschränkungen
Die folgenden Funktionen werden von der Schemaregistrierung nicht unterstützt:
Schemaformate:
- JSON-Schemaformat.
Schemamodi:
READONLY_OVERRIDE-Schemamodus.
Werte für die Schemakonfiguration:
Normalize- undAlias-Konfigurationswerte.
API-Methoden:
- Die Methode
ModifySchemaTags(/subjects/{subject}/versions/{version}/tags). - Die Methode
GetLatestWithMetadata(/subjects/{subject}/metadata). - Die Methode
ListSchemas(/schemas). - Die Methode
DeleteSchemaMode. - Für die Methode
GetVersion: die Parameterformat,deletedundfindTags. - Für die Methode
CreateVersion: die Parametermetadata,ruleSet,schemaTagsToAddundschemaTagsToRemove. - Für die Methode
UpdateSchemaMode: der Parameterforce. - Für die Methode
GetSchemaMode: der ParameterdefaultToGlobal. - Für die Methode
GetSchema: die ParameterWorkspaceMaxIdundfindTags. - Für die Methode
ListVersions: der ParameterdeletedOnly. - Für die Methode
ListSubjects: der ParameterdeletedOnly.
- Die Methode