
El registro de esquemas proporciona repositorios de esquemas compartidos por varias aplicaciones. Anteriormente, sin un registro de esquemas, los equipos podían depender de acuerdos informales, como entendimientos verbales, documentos compartidos que no se aplicaban de forma programática o páginas wiki, para definir el formato de los mensajes y cómo serializarlos y deserializarlos. El registro de esquemas garantiza una codificación y decodificación coherentes de los mensajes.
En este documento, se proporciona una descripción general de la función de registro de esquemas de Managed Service para Apache Kafka, sus componentes y el flujo de trabajo básico.
Información sobre los esquemas
Imagina que estás creando una aplicación que hace un seguimiento de los pedidos de los clientes. Podrías usar un tema de Kafka llamado customer_orders para transmitir mensajes que contengan información sobre cada pedido. Un mensaje de pedido típico puede incluir los siguientes campos de información:
ID de pedido
Nombre del cliente
Nombre del producto
Cantidad
Precio
Para garantizar que estos mensajes estén estructurados de manera coherente, puedes definir un esquema. Este es un ejemplo en formato Apache Avro:
{
"type": "record",
"name": "Order",
"namespace": "com.example",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "customerName", "type": "string"},
{"name": "productName", "type": "string"},
{"name": "quantity", "type": "int"},
{"name": "price", "type": "double"}
]
}
Aquí tienes el mismo ejemplo en formato de búfer de protocolo.
syntax = "proto3";
package com.example;
option java_multiple_files = true; // Optional: Recommended for Java users
option java_package = "com.example"; // Optional: Explicit Java package
message Order {
string orderId = 1;
string customerName = 2;
string productName = 3;
int32 quantity = 4; // Avro int maps to Protobuf int32
double price = 5;
}
Este esquema es un modelo para un mensaje. Te indica que un mensaje order tiene cinco campos: un ID de pedido, un nombre de cliente, un nombre de producto, una cantidad y un precio. También especifica el tipo de datos de cada campo.
Si un cliente consumidor recibe un mensaje binario codificado con este esquema, debe saber exactamente cómo interpretarlo. Para que esto sea posible, el productor almacena el esquema order en un registro de esquemas y pasa un identificador del esquema junto con el mensaje. Siempre que un consumidor del mensaje sepa qué registro se usó, puede recuperar el mismo esquema y decodificar el mensaje.
Supongamos que deseas agregar un campo, orderDate, a tus mensajes de order. Crearías una versión nueva del esquema order y la registrarías con el mismo asunto. Esto te permite hacer un seguimiento de la evolución de tu esquema a lo largo del tiempo.
Agregar un campo es un cambio compatible con versiones posteriores. Esto significa que los consumidores que usan versiones de esquema anteriores (sin orderDate) aún pueden leer y procesar los mensajes producidos con el esquema nuevo. Se ignorará el campo nuevo.
La retrocompatibilidad del registro de esquemas significa que una aplicación de consumidor configurada con una nueva versión del esquema puede leer los datos producidos con un esquema anterior.
En este ejemplo, el esquema order inicial sería la versión 1. Cuando agregas el campo orderDate, creas la versión 2 del esquema order. Ambas versiones se almacenan bajo el mismo asunto, lo que te permite administrar las actualizaciones del esquema sin interrumpir las aplicaciones existentes que aún podrían depender de la versión 1.
A continuación, se muestra una vista de arriba hacia abajo de un registro de esquemas de muestra llamado schema_registry_test organizado por contexto, asunto y versión del esquema:
customer_supportcontextorderasuntoVersión
V1(incluye orderId, customerName, productName, quantity y price)Versión
V2(agrega orderDate a la versión 1)
Qué es un esquema
Los mensajes de Apache Kafka constan de cadenas de bytes. Sin una estructura definida, las aplicaciones de consumidor deben coordinarse directamente con las aplicaciones de productor para comprender cómo interpretar estos bytes.
Un esquema proporciona una descripción formal de los datos dentro de un mensaje. Define los campos y sus tipos de datos, como cadena, número entero o booleano, y cualquier estructura anidada.
Managed Service para Apache Kafka admite esquemas en los siguientes formatos:
Búferes de protocolo (Protobuf)
La API del registro de esquemas no admite JSON.
La función de registro de esquemas integrada en Managed Service for Apache Kafka te permite crear, administrar y usar estos esquemas con tus clientes de Kafka. El registro de esquemas implementa la API de REST de Confluent Schema Registry, que es compatible con las aplicaciones existentes de Apache Kafka y las bibliotecas cliente comunes.
Organización del registro de esquemas
El registro de esquemas usa una estructura jerárquica para organizar los esquemas.
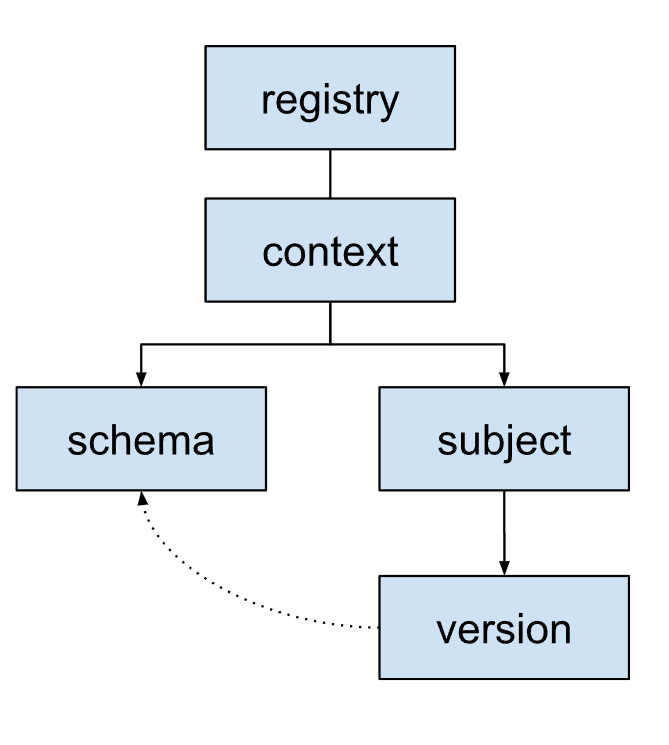
Esquema: Es la estructura y los tipos de datos de un mensaje. Cada esquema se identifica con un ID de esquema. Las aplicaciones usan este ID para recuperar el esquema.
Asunto: Es un contenedor lógico para diferentes versiones de un esquema. Los temas administran cómo evolucionan los esquemas con el tiempo a través de reglas de compatibilidad. Por lo general, cada tema corresponde a un tema de Kafka o a un objeto de registro.
Versión: Cuando la lógica empresarial requiera cambios en la estructura de un mensaje, crea y registra una nueva versión del esquema en el tema correspondiente.
Cada versión hace referencia a un esquema específico. Las versiones de diferentes temas pueden hacer referencia al mismo esquema si el esquema subyacente resulta ser el mismo.
Context: Es una agrupación o un espacio de nombres de alto nivel para los temas. Los contextos permiten que diferentes equipos o aplicaciones usen el mismo nombre de asunto sin conflictos dentro del mismo registro de esquema.
Un registro de esquema puede tener varios contextos. Siempre contiene un contexto predeterminado identificado como
., que es donde van los esquemas y los temas cuando no se especifica ningún otro identificador de contexto.Un contexto puede contener varios temas.
Registro: Es el contenedor de nivel superior para todo el ecosistema de esquemas. Almacena y administra todos los esquemas, temas, versiones y contextos.
Flujo de trabajo del registro de esquemas
Para seguir el flujo de trabajo que se describe en esta sección, puedes probar la guía de inicio rápido en Produce mensajes Avro con el registro de esquemas.
Los serializadores y deserializadores de tus clientes de Kafka interactúan con el registro de esquemas para garantizar que los mensajes se ajusten a un esquema definido. A continuación, se muestra un flujo de trabajo típico para un registro de esquema en Managed Service para Apache Kafka:
Inicializa tu aplicación de productor con un esquema específico que se especifica como una clase generada por Avro y configúrala para que use un registro de esquema y una biblioteca de serializador en particular.
Configura un cliente consumidor para que use una biblioteca de deserializador correspondiente y el mismo registro de esquema.
En el tiempo de ejecución, el cliente pasa el objeto de mensaje al método
producer.send, y la biblioteca cliente de Kafka usa el serializador configurado para convertir este registro en los bytes codificados en Avro.El serializador determina un nombre de tema para el esquema según una estrategia de nombres de temas configurada dentro de la biblioteca cliente. Luego, usa este nombre de asunto en una solicitud al registro de esquemas para recuperar el ID del esquema. Para obtener más información, consulta Estrategias de asignación de nombres de asuntos.
Si el esquema no existe en el registro con ese nombre de tema, se puede configurar el cliente para que registre el esquema, en cuyo caso recibe el ID recién asignado.
Evita esta configuración en entornos de producción.
El productor envía el mensaje serializado con el ID de esquema al tema apropiado de un agente de Kafka.
El agente de Kafka almacena la representación de array de bytes de tu mensaje en un tema.
La aplicación del consumidor recibe el mensaje.
El deserializador recupera el esquema con este ID del registro de esquemas.
El deserializador analiza el mensaje para la aplicación del consumidor.
Limitaciones
El registro de esquema no admite las siguientes funciones:
Formatos de esquema:
- Es el formato del esquema JSON.
Modos de esquema:
- Modo de esquema
READONLY_OVERRIDE
- Modo de esquema
Valores de configuración del esquema:
- Valores de configuración de
NormalizeyAlias
- Valores de configuración de
Métodos de la API:
- El método
ModifySchemaTags(/subjects/{subject}/versions/{version}/tags). - El método
GetLatestWithMetadata(/subjects/{subject}/metadata). - El método
ListSchemas(/schemas). - El método
DeleteSchemaMode. - Para el método
GetVersion: Los parámetrosformat,deletedyfindTags - Para el método
CreateVersion: Los parámetrosmetadata,ruleSet,schemaTagsToAddyschemaTagsToRemove - Para el método
UpdateSchemaMode, el parámetroforce. - Para el método
GetSchemaMode, el parámetrodefaultToGlobal. - Para el método
GetSchema, los parámetrosWorkspaceMaxIdyfindTags - Para el método
ListVersions, el parámetrodeletedOnly. - Para el método
ListSubjects, el parámetrodeletedOnly.
- El método