
O registro de esquema fornece repositórios de esquemas compartilhados por vários aplicativos. Antes, sem um registro de esquema, as equipes dependiam de acordos informais, como entendimentos verbais, documentos compartilhados não aplicados de forma programática ou páginas wiki, para definir o formato da mensagem e como serializar e desserializar mensagens. O registro de esquema garante codificação e decodificação de mensagens consistentes.
Este documento apresenta uma visão geral do recurso de registro de esquema do Serviço gerenciado para Apache Kafka, dos componentes dele e do fluxo de trabalho básico.
Entender esquemas
Imagine que você está criando um aplicativo que rastreia pedidos de clientes. Você pode usar um tópico do Kafka chamado customer_orders para transmitir mensagens com informações sobre cada pedido. Uma mensagem de pedido típica pode incluir os seguintes campos de informação:
Código do pedido
Nome do cliente
Nome do produto
Quantidade
Preço
Para garantir que essas mensagens sejam estruturadas de maneira consistente, defina um esquema. Confira um exemplo no formato Apache Avro:
{
"type": "record",
"name": "Order",
"namespace": "com.example",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "customerName", "type": "string"},
{"name": "productName", "type": "string"},
{"name": "quantity", "type": "int"},
{"name": "price", "type": "double"}
]
}
Este é o mesmo exemplo no formato Protocol Buffer.
syntax = "proto3";
package com.example;
option java_multiple_files = true; // Optional: Recommended for Java users
option java_package = "com.example"; // Optional: Explicit Java package
message Order {
string orderId = 1;
string customerName = 2;
string productName = 3;
int32 quantity = 4; // Avro int maps to Protobuf int32
double price = 5;
}
Esse esquema é um blueprint para uma mensagem. Ele informa que uma mensagem order tem cinco campos: um ID do pedido, um nome de cliente, um nome de produto, uma quantidade e um preço. Ele também especifica o tipo de dados de cada campo.
Se um cliente consumidor receber uma mensagem binária codificada com esse esquema, ele precisará saber exatamente como interpretá-la. Para isso, o produtor
armazena o esquema order em um registro de esquema e transmite um identificador do
esquema junto com a mensagem. Desde que um consumidor da mensagem saiba qual
registro foi usado, ele pode recuperar o mesmo esquema e decodificar a mensagem.
Suponha que você queira adicionar um campo, orderDate, às suas mensagens order. Você
criaria uma nova versão do esquema order e a registraria no mesmo
assunto. Assim, você pode acompanhar a evolução do seu esquema ao longo do tempo.
Adicionar um campo é uma mudança compatível com versões futuras. Isso significa que os consumidores que usam versões mais antigas do esquema (sem orderDate) ainda podem ler e processar mensagens produzidas com o novo esquema. O novo campo é ignorado.
A compatibilidade com versões anteriores do registro de esquema significa que um aplicativo consumidor configurado com uma nova versão de esquema pode ler dados produzidos com um esquema anterior.
Neste exemplo, o esquema order inicial seria a versão 1. Ao adicionar o campo orderDate, você cria a versão 2 do esquema order. As duas versões
são armazenadas no mesmo assunto, permitindo gerenciar atualizações de esquema sem
interromper aplicativos atuais que ainda podem depender da versão 1.
Confira uma visão de cima para baixo de um exemplo de registro de esquema chamado
schema_registry_test organizado por contexto, assunto e
versão do esquema:
customer_supportcontextorderassuntoversão
V1(inclui orderId, customerName, productName, quantity, price)Versão
V2(adiciona orderDate à V1)
O que é um esquema
As mensagens do Apache Kafka consistem em strings de bytes. Sem uma estrutura definida, os aplicativos consumidores precisam coordenar diretamente com os aplicativos produtores para entender como interpretar esses bytes.
Um esquema fornece uma descrição formal dos dados em uma mensagem. Ele define os campos e os tipos de dados deles, como string, número inteiro ou booleano, e todas as estruturas aninhadas.
O Serviço Gerenciado para Apache Kafka aceita esquemas nos seguintes formatos:
Buffers de protocolo (Protobuf)
A API do registro de esquema não é compatível com JSON.
O recurso de registro de esquema integrado ao Serviço gerenciado para Apache Kafka permite criar, gerenciar e usar esses esquemas com seus clientes do Kafka. O Schema Registry implementa a API REST do Confluent Schema Registry, que é compatível com aplicativos Apache Kafka atuais e bibliotecas de cliente comuns.
Organização do registro de esquema
O registro de esquema usa uma estrutura hierárquica para organizar os esquemas.
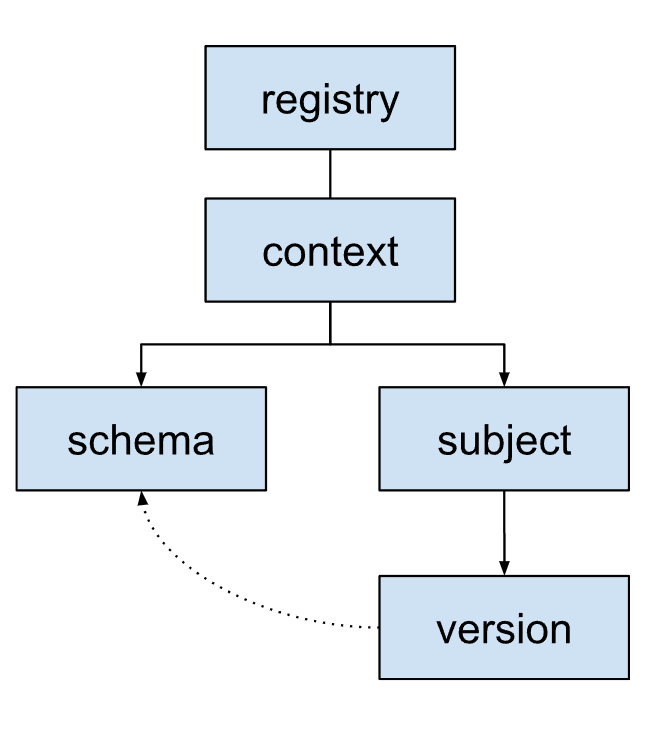
Esquema:a estrutura e os tipos de dados de uma mensagem. Cada esquema é identificado por um ID. Esse ID é usado por aplicativos para recuperar o esquema.
Assunto:um contêiner lógico para diferentes versões de um esquema. Os assuntos gerenciam como os esquemas evoluem ao longo do tempo usando regras de compatibilidade. Cada assunto normalmente corresponde a um tópico ou objeto de registro do Kafka.
Versão:quando a lógica de negócios exige mudanças em uma estrutura de mensagem, crie e registre uma nova versão do esquema no assunto relevante.
Cada versão faz referência a um esquema específico. Versões de assuntos diferentes podem referenciar o mesmo esquema se o esquema subjacente for o mesmo.
Contexto:um agrupamento ou namespace de alto nível para assuntos. Os contextos permitem que diferentes equipes ou aplicativos usem o mesmo nome de assunto sem conflitos no mesmo registro de esquema.
Um registro de esquema pode ter vários contextos. Ele sempre contém um contexto padrão identificado como
., que é onde os esquemas e assuntos vão quando nenhum outro identificador de contexto é especificado.Um contexto pode conter vários assuntos.
Registro:o contêiner de nível superior para todo o ecossistema de esquemas. Ele armazena e gerencia todos os esquemas, assuntos, versões e contextos.
Fluxo de trabalho do registro de esquema
Para seguir o fluxo de trabalho descrito nesta seção, consulte o guia de início rápido em Produzir mensagens Avro com o registro de esquema.
Serializadores e desserializadores nos seus clientes do Kafka interagem com o registro de esquema para garantir que as mensagens estejam de acordo com um esquema definido. Confira um fluxo de trabalho típico para um registro de esquema no Serviço gerenciado para Apache Kafka:
Inicialize o aplicativo produtor com um esquema específico especificado como uma classe gerada pelo Avro e configure-o para usar um registro de esquema e uma biblioteca de serialização específicos.
Configure um cliente consumidor para usar uma biblioteca de desserialização correspondente e o mesmo registro de esquema.
No ambiente de execução, o cliente transmite o objeto de mensagem para o método
producer.send, e a biblioteca de cliente do Kafka usa o serializador configurado para converter esse registro em bytes codificados em Avro.O serializador determina um nome de assunto para o esquema com base em uma estratégia de nome de assunto configurada na biblioteca de cliente. Em seguida, ele usa esse nome de assunto em uma solicitação ao registro de esquema para recuperar o ID do esquema. Para mais informações, consulte Estratégias de nomenclatura de assunto.
Se o esquema não existir no registro com esse nome de assunto, o cliente poderá ser configurado para registrar o esquema, e ele receberá o ID recém-atribuído.
Evite essa configuração em ambientes de produção.
O produtor envia a mensagem serializada com o ID do esquema para o tópico apropriado de um agente do Kafka.
O agente do Kafka armazena a representação de matriz de bytes da sua mensagem em um tópico.
O aplicativo consumidor recebe a mensagem.
O desserializador recupera o esquema com esse ID do registro de esquema.
O desserializador analisa a mensagem para o aplicativo consumidor.
Limitações
Os seguintes recursos não são compatíveis com o registro de esquema:
Formatos de esquema:
- Formato de esquema JSON.
Modos de esquema:
- Modo de esquema
READONLY_OVERRIDE.
- Modo de esquema
Valores de configuração do esquema:
- Valores de configuração
NormalizeeAlias.
- Valores de configuração
Métodos de API:
- O método
ModifySchemaTags(/subjects/{subject}/versions/{version}/tags). - O método
GetLatestWithMetadata(/subjects/{subject}/metadata). - O método
ListSchemas(/schemas). - O método
DeleteSchemaMode. - Para o método
GetVersion: os parâmetrosformat,deletedefindTags. - Para o método
CreateVersion: os parâmetrosmetadata,ruleSet,schemaTagsToAddeschemaTagsToRemove. - Para o método
UpdateSchemaMode: o parâmetroforce. - Para o método
GetSchemaMode: o parâmetrodefaultToGlobal. - Para o método
GetSchema: os parâmetrosWorkspaceMaxIdefindTags. - Para o método
ListVersions: o parâmetrodeletedOnly. - Para o método
ListSubjects: o parâmetrodeletedOnly.
- O método