
Los clientes pueden conectarse a un clúster de Managed Service for Apache Kafka desde cualquier red de nube privada virtual (VPC) en tus proyectos de Google Cloud.
En esta página, se explica cómo se configura la red en el Servicio administrado para Apache Kafka, cómo habilitar las conexiones entre los clientes de Kafka y tu clúster, y cómo habilitar la conectividad entre proyectos.
Descripción general
Cuando creas un clúster, el servicio lo coloca en una red de VPC administrada por Google Cloud. Esta red se denomina red de inquilino. Cada clúster de Managed Service para Apache Kafka tiene su propia red de arrendatario aislada. Para permitir que las aplicaciones cliente se comuniquen con el clúster, conecta las subredes dentro de tus redes de VPC a la red del arrendatario.
En el siguiente diagrama, se muestran dos proyectos de Google Cloud , project-1 yproject-2. Un clúster de Managed Service para Apache Kafka se encuentra en project-1.
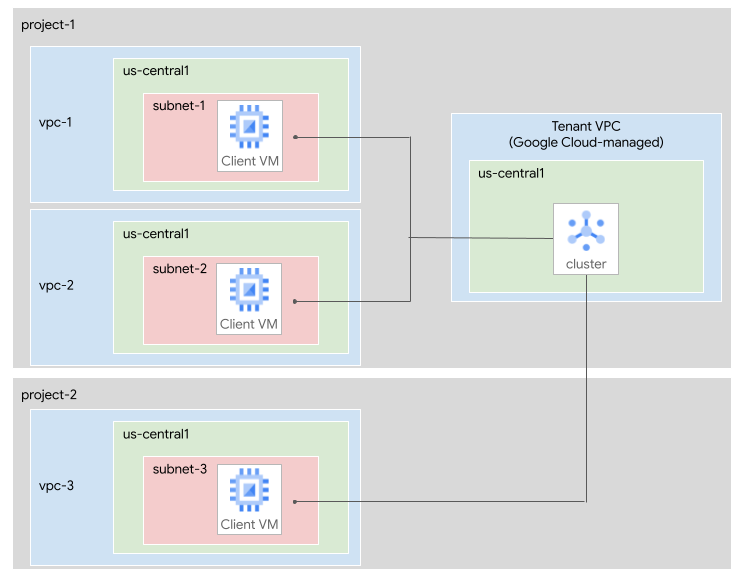
Las siguientes subredes están conectadas al clúster:
subnet-1, en la red de VPCvpc-1enproject-1subnet-2, en la red de VPCvpc-2enproject-1subnet-3, en la red de VPCvpc-3enproject-2
Conecta subredes a un clúster
Cuando creas un clúster de Managed Service para Apache Kafka por primera vez, debes especificar al menos una subred. Más adelante, puedes actualizar el clúster para agregar o quitar subredes.
Las subredes conectadas pueden pertenecer al mismo proyecto Google Cloud que el clúster o a uno diferente. Las subredes conectadas deben estar en la misma región que el clúster, pero los clientes de cualquier región dentro de la misma VPC pueden conectarse a las direcciones IP de esa subred. Como máximo, se puede conectar una subred por red de VPC al clúster.
Para ver las subredes conectadas a un clúster, consulta Cómo ver las subredes de un clúster.
Entradas de DNS del clúster
Cuando conectas una subred a un clúster, el servicio crea entradas de DNS dentro de esa red de subred para la dirección de arranque y los intermediarios del clúster. Los clientes de Kafka usan la dirección de inicio para ubicar los agentes y establecer una conexión.
Los nombres de DNS son los mismos en todas las subredes conectadas, aunque corresponden a diferentes direcciones IP en cada subred. Debido a que los nombres de DNS son coherentes, todas tus aplicaciones cliente de Kafka pueden usar la misma dirección de arranque. Para obtener la dirección de arranque del clúster, consulta Cómo ver la dirección de arranque de un clúster.
Para ver ejemplos de aplicaciones cliente que se conectan a Managed Service para Apache Kafka, consulta los siguientes instructivos:
Tamaño de la subred
Cuando agregas una subred a un clúster, esta debe tener suficientes direcciones IP disponibles. Cada subred requiere una dirección IP para cada agente de Kafka, además de una dirección IP para la dirección de arranque. El tamaño mínimo del clúster para Managed Service for Apache Kafka es de tres agentes, por lo que cada subred necesita al menos cuatro direcciones IP utilizables, incluida la dirección de arranque.
Si tu clúster tiene más de 45 CPU virtuales, tendrá un agente por cada 15 CPU virtuales. En ese caso, calcula la cantidad mínima de direcciones IP para cada subred de la siguiente manera:
- Divide la cantidad de CPU virtuales por 15.
- Redondea hacia arriba al número entero más cercano.
- Agrega 1 para tener en cuenta la dirección de arranque.
Por ejemplo, un clúster con 60 CPU virtuales necesita al menos (60/15 + 1) = 5 direcciones IP utilizables.
Es posible que Google cambie la proporción de intermediarios por CPU virtuales en el futuro. Para tener en cuenta cualquier cambio futuro, te recomendamos que asignes 3 veces la cantidad de direcciones IP que calculaste en el paso anterior.
Cuando planifiques el tamaño de la subred, basa tus cálculos en el tamaño máximo al que esperas escalar tu clúster en el futuro.
Si planeas usar Kafka Connect, también debes tener en cuenta los requisitos de subred para el clúster de Connect. Para obtener más información, consulta subred de trabajadores.
Rangos de IP públicas que se usan de forma privada
Puedes conectar tu clúster a subredes que usan el espacio de direcciones que no es RFC 1918. Estos rangos de direcciones IP se denominan rangos de IP públicas de uso privado (PUPI).
No se requiere configuración adicional para conectarse a las subredes de PUPI. Las subredes de PUPI deben usar un rango IPv4 válido que no sea un rango de subred IPv4 prohibido.
Conecta clientes y clústeres en diferentes proyectos
Si tienes clientes de Kafka en diferentes proyectos de Google Cloud , puedes conectarlos a tu clúster de las siguientes maneras:
- Conecta el clúster a redes de VPC en varios proyectos.
- Usa la VPC compartida para conectar proyectos.
En las siguientes secciones, se describen estas opciones.
Conecta un clúster en varios proyectos
Puedes conectar subredes de otros proyectos a tu clúster. Para habilitar el acceso entre proyectos, debes otorgar permisos a la cuenta de servicio administrada por Google que está asociada al clúster. En cada proyecto en el que desees que los clientes de Kafka accedan al clúster, la cuenta de servicio debe tener el rol de IAM de agente de servicio de Kafka administrado en ese proyecto. Este rol permite que el clúster acceda a los recursos deGoogle Cloud , de modo que pueda crear recursos de red y entradas de DNS.
Ejemplo: Si project-1 contiene el clúster y deseas que los clientes de project-2 accedan al clúster, otorga a la cuenta de servicio de Kafka administrado para project-1 el rol de agente de servicio de Kafka administrado en project-2. Luego, conecta una subred de project-2 al clúster, como se describe en Conecta subredes al clúster.
Para otorgar los roles necesarios, sigue estos pasos:
Console
Determina los Google Cloud proyectos en los que deseas que tus clientes de Kafka accedan al clúster de Managed Service para Apache Kafka.
Para cada proyecto, en la consola de Google Cloud , ve a la página IAM de ese proyecto:
Haz clic en Otorgar acceso.
En el campo Principales nuevas, ingresa lo siguiente:
service-CLUSTER_PROJECT_NUMBER@gcp-sa-managedkafka.iam.gserviceaccount.comReemplaza CLUSTER_PROJECT_NUMBER por el número del proyecto que contiene el clúster de Managed Service para Apache Kafka.
Haz clic en Agregar roles.
En el campo Buscar roles, ingresa
Managed Kafka Service Agent. El nombre del agente de servicio aparece en los resultados de la búsqueda.En los resultados de la búsqueda, selecciona Agente de servicio de Kafka administrado.
Haz clic en Aplicar.
Haz clic en Guardar.
gcloud
Determina los Google Cloud proyectos en los que deseas que tus clientes de Kafka accedan al clúster de Managed Service para Apache Kafka.
Para cada proyecto, ejecuta el comando
gcloud projects add-iam-policy-binding:gcloud projects add-iam-policy-binding CLIENT_PROJECT_ID \ --member=serviceAccount:service-CLUSTER_PROJECT_NUMBER@gcp-sa-managedkafka.iam.gserviceaccount.com \ --role=roles/managedkafka.serviceAgentReemplaza lo siguiente:
- CLIENT_PROJECT_ID: Es el nombre del proyecto que contiene la red de VPC a la que se conectará.
- CLUSTER_PROJECT_NUMBER: Es el número de proyecto del proyecto que contiene el clúster de Managed Service para Apache Kafka.
Usa la VPC compartida para conectar proyectos
La VPC compartida permite que una organización conecte recursos de varios proyectos a una red de VPC común. Para usar la VPC compartida con Managed Service for Apache Kafka, sigue estos pasos:
Crea un clúster de Managed Service para Apache Kafka.
Otorga a la cuenta de servicio de Kafka administrado los roles necesarios en el proyecto host de la VPC compartida, como se describe en la sección anterior.
Conecta el clúster de Managed Service para Apache Kafka a una subred en la red de VPC compartida.
Los clientes del proyecto host de la VPC compartida o de los proyectos de servicio pueden conectarse al clúster.
Para obtener información sobre cuándo usar la VPC compartida en tus arquitecturas de red, consulta Prácticas recomendadas y arquitecturas de referencia para el diseño de VPC.
Arquitectura de red de un clúster
En esta sección, se describen los detalles de la arquitectura de redes que se usa en Managed Service para Apache Kafka.
Un clúster de Kafka abarca una red de arrendatario y una o más redes de consumidores.
En la red del arrendatario, el clúster tiene una sola dirección IP y URL de arranque. Esta dirección de arranque corresponde a un balanceador de cargas conectado a todos los agentes del clúster. Cada broker también puede actuar de forma individual como servidor de arranque, pero te recomendamos que uses la dirección de arranque para mayor confiabilidad.
Dentro de cada red del consumidor, el servicio crea un extremo de Private Service Connect para la dirección de arranque y un extremo para cada agente.
La URL de la dirección de arranque es la misma en todas las redes de VPC a las que se conecta un clúster. La dirección IP es local para la red del consumidor.
Los clientes se conectan a los agentes de Kafka con nombres de DNS. Estos nombres se registran automáticamente en cada red de VPC a la que se conecta un clúster de Kafka. La dirección de arranque y su número de puerto están disponibles como una propiedad del clúster.
Los clientes usan la dirección de arranque para recuperar las URLs de los intermediarios, que se resuelven en direcciones IP locales para cada red de VPC. Puedes encontrar las direcciones IP y URLs reales del agente en Cloud DNS.
En el siguiente diagrama, se muestra un ejemplo de arquitectura de una red de clúster de Managed Service para Apache Kafka.
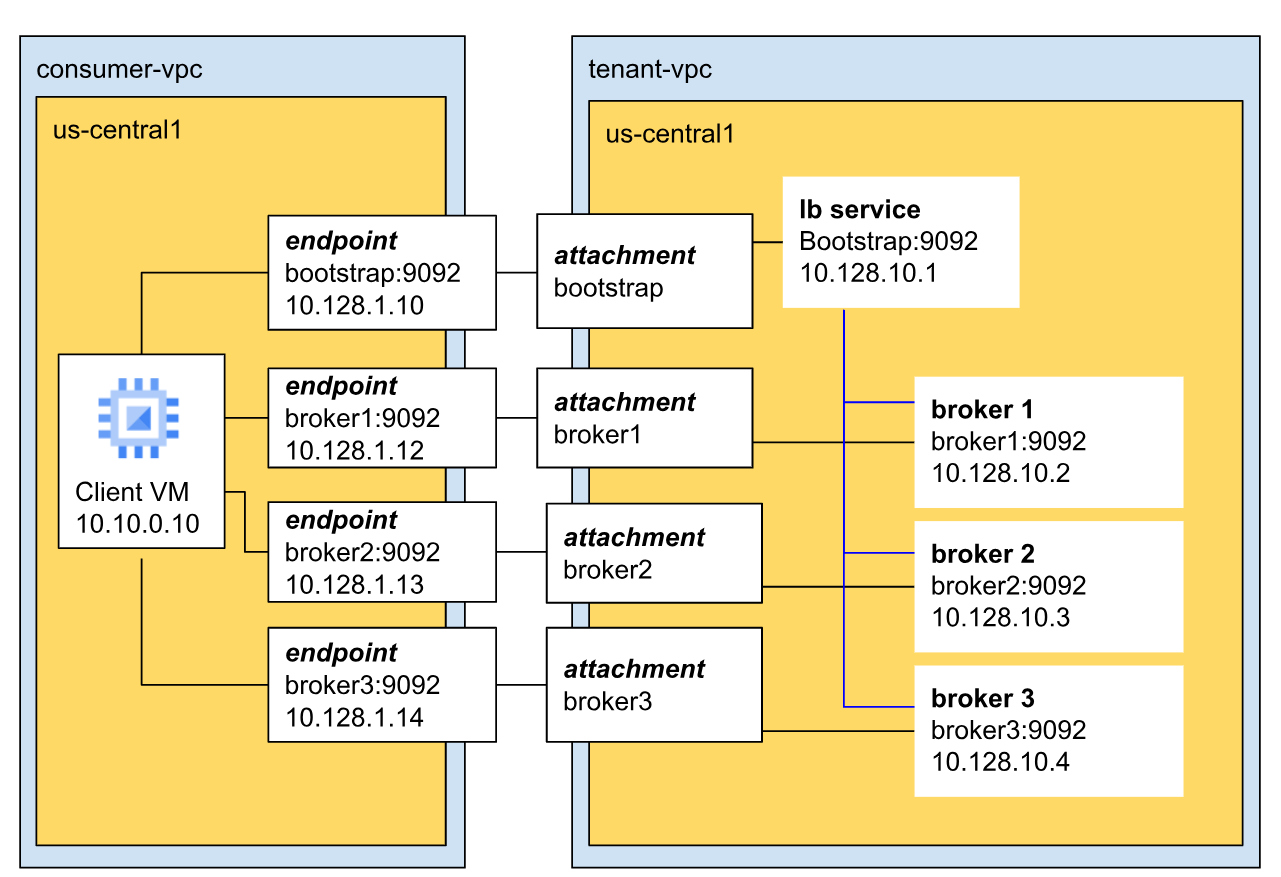
En este ejemplo, el clúster tiene tres intermediarios y se encuentra en la VPC del arrendatario.
Los agentes se comunican con los clientes a través del puerto predeterminado de Kafka (9092) y tienen direcciones IP únicas. En este ejemplo, los tres intermediarios tienen las direcciones IP 10.128.10.2, 10.128.10.3 y 10.128.10.4, respectivamente.
Los tres intermediarios se conectan al balanceador de cargas de inicio. Esto garantiza una alta disponibilidad y tolerancia a errores regionales, ya que la dirección de arranque no se limita a un solo agente o zona.
Soluciona problemas relacionados con la configuración de la red de VPC
Si el servicio no puede configurar la red de VPC del consumidor para acceder al clúster de Managed Service para Apache Kafka, registra mensajes similares a los siguientes:
Managed Service for Apache Kafka failed to set up networking in VPC subnet
to the cluster project.
Si tus clientes de Kafka no se pueden conectar a un clúster de Managed Service para Apache Kafka, sigue estos pasos para solucionar el problema:
Habilita las APIs de Compute Engine y Cloud DNS en el proyecto principal de la red de VPC del consumidor.
Si el clúster de Managed Service para Apache Kafka y la red de VPC del consumidor están en proyectos diferentes, configura los permisos necesarios. Consulta Cómo conectar un clúster entre proyectos.
Asegúrate de que no haya restricciones de políticas de la organización que impidan que el servicio cree los recursos necesarios en el proyecto de la red de VPC del consumidor.
Asegúrate de que los clientes usen la dirección de arranque correcta.
Asegúrate de que los clientes de Kafka se ejecuten en una red de VPC configurada para acceder al clúster de Managed Service para Apache Kafka.
Si ejecutas el cliente de Kafka en una computadora o laptop, puedes configurar una instancia de Compute Engine para que se use como proxy y acceder al clúster de Managed Service for Apache Kafka. Para obtener más información, consulta Cómo configurar una máquina cliente.